El nuevo modelo de lenguaje grande de Meta funciona con hardware Intel y Qualcomm

[ad_1]
Meta ha lanzado Llama 3, el último modelo de lenguaje grande (LLM) para una experiencia de IA generativa más segura y precisa. Junto con el LLM, Meta presentó las herramientas de confianza y seguridad Llama Guard 2, Code Shield y CyberSec Eval 2 para garantizar el cumplimiento de las expectativas de seguridad de la industria y los usuarios. Si bien Meta todavía está desarrollando modelos de IA Llama 3, la compañía ahora está presentando los dos primeros modelos al público.
Los usuarios ahora pueden experimentar con los dos primeros LLM de Meta. Imagen cortesía de Meta
El Llama 3 de código abierto integra seguridad en los modelos y ofrece soporte de hardware para múltiples plataformas. Meta señala que el soporte para Llama 3 pronto estará disponible en todas las plataformas principales, incluidos los proveedores de nube y los proveedores de API modelo. Las empresas que pronto albergarán Llama 3 LLM incluyen AWS, Databricks, Google Cloud, Hugging Face, Kaggle, IBM WatsonX, Microsoft Azure, Nvidia NIM y Snowflake. El LLM también es compatible con hardware de AMD, AWS, Dell, Intel, Nvidia y Qualcomm.
Qualcomm e Intel están ejecutando rápidamente Llama 3 en plataformas de hardware
Los procesadores de IA generativa necesitan mover grandes cantidades de datos rápidamente y procesar matemáticas en operaciones masivamente paralelas. Esto se aplica a todo tipo de procesadores, ya sean unidades de procesamiento gráfico (GPU), unidades de procesamiento neuronal (NPU) o unidades de procesamiento tensorial (TPU) en combinación con CPU de alto rendimiento. Las GPU, NPU y TPU pueden ser coprocesadores independientes de alto rendimiento o núcleos integrados en procesadores de sistema en chip (SoC).
Qualcomm está utilizando un enfoque SoC para llevar Llama 3 a sus procesadores móviles. La compañía trabajó con Meta durante el desarrollo de Llama 3 para garantizar que el LLM fuera compatible con sus productos insignia Snapdragon. Los procesadores Snapdragon tienen núcleos NPU, CPU y GPU preparados para IA.

Intel ha validado su cartera de productos de IA para los primeros modelos Llama 3 8B y 70B. Imagen cortesía de Intel
Intel también trabajó con Meta para desarrollar Llama 3 para procesadores a nivel de centro de datos. Intel ha optimizado sus aceleradores de IA Gaudi 2 para Llama 2, la versión anterior del LLM de Meta, y ahora ha demostrado la compatibilidad de los aceleradores con Llama 3. Los procesadores Intel Xeon, Core Ultra y Arc también han sido validados con Llama 3.
¿Cómo funcionan los LLM, especialmente Llama 3?
Los LLM de IA interpretan un conjunto de datos y lo convierten en una oración interpretable por máquina. Esto permite que la IA generativa duplique una experiencia similar a la humana cuando se construye sobre una base de conocimientos previa. El proceso de modelado logra esto tokenizando palabras, de manera similar a cómo un compilador de software toma palabras clave y las convierte en códigos de operación de CPU. Reglas como la gramática, la sintaxis y la puntuación se incorporan al gobierno para la interpretación y generación de resultados de la IA.
Cuantos más parámetros se tokenicen, más precisa y humana será la salida. Sin embargo, la cantidad de parámetros debe equilibrarse con la carga computacional de la tokenización, la aplicación de reglas y la interpretación. Llama 3 viene en dos modelos diferentes: uno con ocho mil millones de parámetros para IA de vanguardia, como los utilizados en procesadores de teléfonos, y otro con 70 mil millones para sistemas de centros de datos más grandes.
Llama 3 utiliza un vocabulario de tokens de 128 KB para una codificación eficiente. Utiliza atención de consultas agrupadas (GQA) para los modelos 8B y 70B. Los modelos fueron entrenados con secuencias de 8.192 tokens. Meta usó una máscara para evitar que su propia atención cruzara las barreras de los documentos.

Mediciones de rendimiento para Lama 3 8B y 70B. Imagen cortesía de Meta
En las pruebas de aprendizaje de disparo cero (0-shot), el modelo de IA no se entrena específicamente con los datos utilizados en la pregunta. Por ejemplo, se le pedirá al modelo de IA que identifique un pato si no ha sido entrenado con ejemplos de patos. En cambio, se debe derivar un resultado basado en relaciones semánticas.
Para pruebas de aprendizaje de N disparos (n > 0), el modelo se entrenó con al menos n ejemplos de datos de preguntas de prueba. Chain of Thought (CoT) prueba el pensamiento de la IA para tareas complejas como matemáticas y física. Metaprobó a Llama con un nuevo conjunto de evaluación humana que incluía 1.800 indicaciones para 12 casos de uso comunes.
Meta tiene en cuenta la seguridad de la IA
Después de más de un año de uso generalizado de la IA por parte del público en general, las cuestiones de seguridad, precisión y confiabilidad han pasado a primer plano. Meta ha tenido en cuenta estas preocupaciones y permite a los desarrolladores de IA ajustar los modelos de seguridad en cada aplicación.
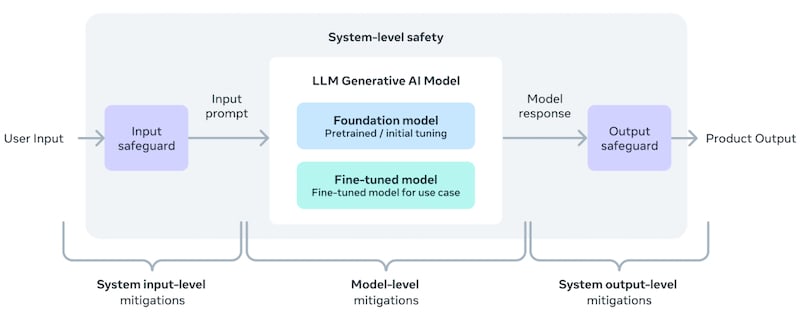
Modelo de seguridad a nivel de sistema Llama 3. Imagen cortesía de Meta
Meta proporciona separación entre los casos de prueba y los desarrolladores del modelo para evitar un sobreajuste involuntario. El sobreajuste de LLM ocurre cuando un modelo complejo esencialmente almacena los datos de entrenamiento en lugar de aprender a usar los patrones subyacentes. Cuando está abarrotado, un LLM con datos de capacitación sería muy efectivo, pero tendría una capacidad limitada para trabajar con datos nuevos o diferentes. Un LLM muy sobreadaptado es bueno imitando pero no es capaz de pensar por sí mismo.
Los próximos pasos de Lama 3
La IA todavía es un trabajo en progreso y lo será durante bastante tiempo, y Meta Llama 3 LLM en desarrollo no es una excepción.

Vista previa del rendimiento futuro de Llama 3. Imagen cortesía de Meta.
Aunque Meta lanzó los modelos 8B y 70B, la compañía todavía está entrenando la versión de parámetros 400B. Y si bien los 400 mil millones de parámetros muestran una mejora en la precisión con un conjunto de parámetros más grande, la comparación de los números 400B+ con los gráficos de rendimiento 8B y 70B muestra rendimientos no lineales en algunos puntos de referencia. De esto es fácil concluir que las mayores demandas de hardware de IA no disminuirán en el futuro previsible.
Imágenes utilizadas con el amable permiso de Meta.
[ad_2]
Deja una respuesta