
[ad_1]
Permitir que los usuarios finales enseñen interactivamente a los robots a realizar tareas novedosas es una capacidad crítica para su integración exitosa en aplicaciones del mundo real. Por ejemplo, un usuario podría querer enseñarle a un perro robot a realizar un nuevo truco o enseñarle a un robot manipulador cómo organizar una lonchera según las preferencias del usuario. Los avances recientes en modelos de lenguaje de gran tamaño (LLM, por sus siglas en inglés) previamente entrenados con grandes datos de Internet han mostrado una forma prometedora de lograr este objetivo. De hecho, los investigadores han explorado varias formas de aprovechar los LLM en robótica, desde la planificación paso a paso y el diálogo orientado a objetivos hasta agentes robóticos de escritura de códigos.
Si bien estos métodos transmiten nuevos modos de generalización compositiva, se centran en el uso del lenguaje para vincular nuevos comportamientos de una biblioteca existente de primitivas de control, ya sea desarrolladas manualmente o aprendidas. a priori. A pesar del conocimiento interno de los movimientos de los robots, los LLM tienen dificultades para emitir directamente comandos de robot de bajo nivel debido a la disponibilidad limitada de datos de capacitación relevantes. Como resultado, la expresión de estos métodos está limitada por la amplitud de primitivas disponibles, que a menudo requieren amplios conocimientos expertos o recopilación de datos para diseñar.
En «Lenguaje para recompensas por la síntesis de habilidades robóticas» proponemos un enfoque que permite a los usuarios enseñar a los robots acciones novedosas a través del lenguaje natural. Para ello, utilizamos funciones de recompensa como una interfaz que cierra la brecha entre el lenguaje y las acciones robóticas de bajo nivel. Postulamos que las funciones de recompensa proporcionan una interfaz ideal para tales tareas debido a su riqueza en semántica, modularidad e interpretabilidad. También proporcionan un vínculo directo con políticas de bajo nivel a través de la optimización de caja negra o el aprendizaje por refuerzo (RL). Desarrollamos un sistema de voz a recompensa que utiliza LLM para traducir instrucciones de usuario en lenguaje natural en código que especifica recompensas y luego aplica MuJoCo MPC para encontrar acciones óptimas de robot de bajo nivel que maximicen la función de recompensa generada. Demostramos nuestro sistema de discurso-recompensa a través de una variedad de tareas de control de robots en simulación utilizando un robot de cuatro patas y un robot manipulador diestro. Además validamos nuestro método en un manipulador robótico físico.
El sistema Language-to-Reward consta de dos componentes principales: (1) un traductor de recompensas y (2) un controlador de movimiento. El El traductor de recompensas asigna instrucciones en lenguaje natural de los usuarios a funciones de recompensa, representadas como código Python. El controlador de movimiento optimiza la función de recompensa dada utilizando la optimización del horizonte de retroceso para encontrar las acciones óptimas del robot de bajo nivel, p. B. la cantidad de torque que se debe aplicar a cada motor del robot.
 |
| Los LLM no pueden generar acciones directas de robot de bajo nivel debido a la falta de datos en el conjunto de datos previo al entrenamiento. Proponemos utilizar funciones de recompensa para cerrar la brecha entre el habla y las acciones robóticas de bajo nivel, permitiendo nuevos movimientos robóticos complejos a partir de instrucciones en lenguaje natural. |
Traductor de recompensas: traduce las instrucciones del usuario en funciones de recompensa
El módulo Reward Translator se desarrolló con el objetivo de asignar instrucciones de usuario en lenguaje natural a funciones de recompensa. El ajuste de las recompensas es muy específico de un dominio y requiere conocimientos expertos. Por lo tanto, no nos sorprendió descubrir que los LLM capacitados en conjuntos de datos de voz genéricos no pueden generar directamente una función de recompensa para un hardware específico. Para abordar este problema, aprovechamos la capacidad de aprendizaje contextual de los LLM. Además, hemos dividido Reward Translator en dos submódulos: descriptor de movimiento Y codificador de recompensa.
descriptor de movimiento
Primero, diseñamos un descriptor de movimiento que interpreta la entrada de un usuario y la convierte en una descripción en lenguaje natural del movimiento deseado del robot, siguiendo una plantilla predefinida. Este descriptor de movimiento convierte instrucciones de usuario potencialmente ambiguas o vagas en movimientos robóticos más específicos y descriptivos y hace que la tarea de codificación de recompensas sea más sólida. Además, los usuarios interactúan con el sistema a través del panel de descripción de movimiento, lo que hace que la interfaz de usuario sea más interpretable en comparación con mostrar la función de recompensa directamente.
Para crear el descriptor de movimiento, utilizamos un LLM para traducir la entrada del usuario en una descripción detallada del movimiento deseado del robot. Diseñamos indicaciones que guían a los LLM para generar la descripción del movimiento con la cantidad adecuada de detalle y en el formato correcto. Al traducir una instrucción de usuario vaga en una descripción más detallada, podemos generar la función de recompensa con nuestro sistema de manera más confiable. Esta idea también puede aplicarse de manera más general más allá de las tareas robóticas y es relevante para el monólogo interno y la cadena de pensamiento.
codificador de recompensa
En la segunda etapa, utilizamos el mismo Motion Descriptor LLM para Reward Coder, que traduce la descripción del movimiento generado en la función de recompensa. Las funciones de recompensa se representan utilizando código Python para beneficiarse del conocimiento del LLM sobre recompensa, codificación y estructura de código.
Idealmente, nos gustaría utilizar un LLM para generar directamente una función de recompensa. R (S, T) que representa el estado del robot S y tiempo T convertir a un valor de recompensa escalar. Sin embargo, generar la función de recompensa correcta desde cero sigue siendo un problema desafiante para los LLM y corregir los errores requiere que el usuario comprenda el código generado para poder proporcionar la retroalimentación correcta. Por lo tanto, predefinimos un conjunto de condiciones de recompensa comúnmente utilizadas para el robot en cuestión y permitimos que los LLM compongan diferentes condiciones de recompensa para formular la función de recompensa final. Para lograr esto, diseñamos un mensaje que especifica las condiciones de recompensa y guía al LLM para generar la función de recompensa adecuada para la tarea.
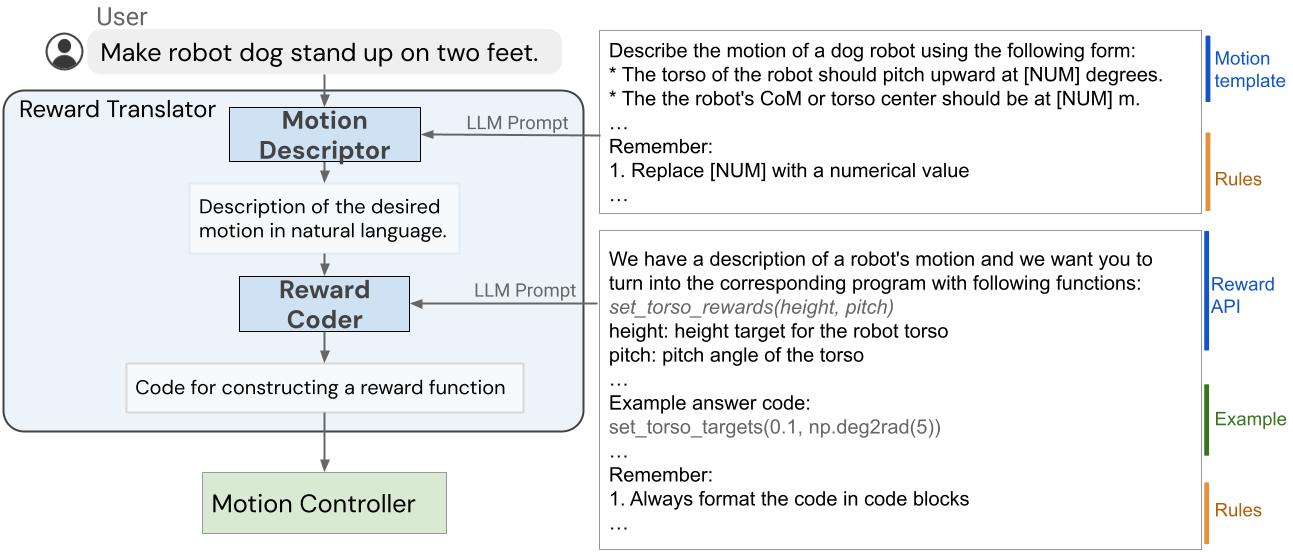 |
| La estructura interna del traductor de recompensas encargada de asignar las entradas del usuario a las funciones de recompensa. |
Controlador de movimiento: traduce funciones de recompensa en acciones robóticas
El controlador de movimiento toma la función de recompensa generada por el traductor de recompensas y sintetiza un controlador que asigna la observación del robot a acciones del robot de bajo nivel. Para hacer esto, formulamos el problema de síntesis del controlador como un proceso de decisión de Markov (MDP), que puede resolverse utilizando diferentes estrategias, incluida RL, optimización de trayectoria fuera de línea o control predictivo de modelo (MPC). Específicamente, utilizamos una implementación de código abierto basada en MuJoCo MPC (MJPC).
MJPC ha demostrado la creación interactiva de varios comportamientos como por ejemplo, locomoción de las piernas, agarre y marcha con los dedos, al tiempo que admite múltiples algoritmos de planificación como: B. Muestreo iterativo lineal-cuadrático-gaussiano (iLQG) y predictivo. Más importante aún, la reprogramación frecuente en MJPC fortalece su solidez ante las incertidumbres en el sistema y, cuando se combina con LLM, permite un sistema interactivo de corrección y síntesis de movimiento.
ejemplos
perro robot
En el primer ejemplo, aplicamos el sistema Language-to-Reward a un robot simulado de cuatro patas y le enseñamos varias habilidades. Para cada habilidad, el usuario da una instrucción concisa al sistema, que luego sintetiza el movimiento del robot utilizando funciones de recompensa como interfaz intermedia.
Manipulador experto
Luego aplicamos el sistema de discurso-recompensa a un diestro robot manipulador para realizar diversas tareas de manipulación. El manipulador experto tiene 27 grados de libertad, lo que es muy difícil de controlar. Muchas de estas tareas requieren habilidades de manipulación más allá de la comprensión, lo que dificulta el trabajo de los primitivos ya preparados. También incluimos un ejemplo en el que el usuario puede indicarle de forma interactiva al robot que coloque una manzana en un cajón.
Validación en robots reales
También validamos el método de lenguaje a recompensa utilizando un robot de manipulación del mundo real que realiza tareas como recoger objetos y abrir un cajón. Para realizar la optimización en el controlador de movimiento, utilizamos AprilTag, un sistema de marcadores de referencia, y F-VLM, una herramienta de reconocimiento de objetos de vocabulario abierto, para identificar la posición del escenario y los objetos manipulados.
Diploma
En este trabajo, describimos un nuevo paradigma para conectar un LLM a un robot mediante funciones de recompensa, respaldado por una herramienta de control predictivo de bajo nivel, MuJoCo MPC. El uso de funciones de recompensa como interfaz permite a los LLM operar en un espacio rico en semántica que explota las fortalezas de los LLM y al mismo tiempo garantiza la expresividad del controlador resultante. Para mejorar aún más el rendimiento del sistema, proponemos utilizar una plantilla de descripción de movimiento estructurada para extraer mejor el conocimiento interno sobre los movimientos del robot de los LLM. Demostramos nuestro sistema propuesto en dos plataformas robóticas simuladas y un robot real para tareas de locomoción y manipulación.
gracias
Nos gustaría agradecer a nuestros coautores Nimrod Gileadi, Chuyuan Fu, Sean Kirmani, Kuang-Huei Lee, Montse González Arenas, Hao-Tien Lewis Chiang, Tom Erez, Leonard Hasenclever, Brian Ichter, Ted Xiao, Peng Xu, Andy Zeng. , Tingnan Zhang, Nicolas Heess, Dorsa Sadigh, Jie Tan y Yuval Tassa por su ayuda y apoyo en varios aspectos del proyecto. También nos gustaría agradecer a Ken Caluwaerts, Kristian Hartikainen, Steven Bohez, Carolina Parada, Marc Toussaint y a los equipos más grandes de Google DeepMind por sus comentarios y contribuciones.
[ad_2]