
[ad_1]
La capacidad de reconocer objetos en el mundo visual es crucial para la visión por computadora y la inteligencia artificial, lo que permite aplicaciones como agentes autónomos adaptativos y sistemas de compra versátiles. Sin embargo, los detectores de objetos modernos están limitados por la anotación manual de sus datos de entrenamiento, lo que da como resultado un vocabulario significativamente más pequeño que el gran conjunto de objetos que se encuentran en la realidad. Para superar esto, se desarrolló la Tarea de Detección de Vocabulario Abierto (OVD), que utiliza pares de imagen-texto para el entrenamiento e incorpora nuevos nombres de categorías en el momento de la prueba asociándolos con el contenido de la imagen. Al tratar las categorías como incrustaciones de texto, los detectores de vocabulario abierto pueden predecir una variedad de objetos invisibles. Se han propuesto varias técnicas, como el preentrenamiento de imagen y texto, la destilación de conocimientos, el pseudoetiquetado y los modelos congelados, a menudo utilizando redes troncales de CNN (red neuronal convolucional). Con la creciente popularidad de los transformadores de visión (ViT), es importante explorar su potencial para construir potentes detectores de vocabulario abierto.
Los enfoques existentes asumen la disponibilidad de modelos de lenguaje de visión (VLM) previamente entrenados y se centran en el ajuste o destilación de estos modelos para eliminar la falta de coincidencia entre el entrenamiento previo a nivel de imagen y el ajuste a nivel de objeto. Sin embargo, dado que los VLM están diseñados principalmente para tareas a nivel de imágenes, como clasificación y recuperación, no explotan completamente el concepto de objetos o regiones durante la fase previa al entrenamiento. Por lo tanto, podría ser beneficioso para el reconocimiento de vocabulario abierto si incluimos información de ubicación en el entrenamiento previo de imagen-texto.
En «RO-ViT: entrenamiento previo con reconocimiento de región para la detección de objetos de vocabulario abierto con transformadores de visión» presentado en CVPR 2023, presentamos un método simple para entrenar previamente transformadores de visión de manera con reconocimiento de región para detectar objetos mejorados de vocabulario abierto. En Vision Transformers, se agregan incrustaciones de posición a los campos de imagen para codificar información sobre la posición espacial de cada campo dentro de la imagen. El entrenamiento previo estándar generalmente utiliza la incrustación de posiciones de fotograma completo, lo que no se traduce bien en tareas de reconocimiento. Por lo tanto, proponemos un nuevo esquema de incrustación posicional llamado «Incrustación posicional recortada» que se adapta mejor al uso de regiones recortadas al ajustar la detección. Además, reemplazamos la pérdida de entropía cruzada de softmax con una pérdida de enfoque en el aprendizaje contrastivo de imagen-texto, lo que nos permite aprender de ejemplos más desafiantes e informativos. Finalmente, aprovechamos los avances recientes en propuestas de objetos novedosos para mejorar el ajuste del reconocimiento de vocabulario abierto, motivado por la observación de que los métodos existentes a menudo pasan por alto objetos novedosos durante la fase de propuesta debido al sobreajuste de las categorías de primer plano. También publicamos el código aquí.
Entrenamiento previo de imagen y texto con reconocimiento de región
Los VLM existentes están capacitados para asociar una imagen en su conjunto con una descripción textual. Sin embargo, encontramos que existe una discrepancia entre la forma en que se utilizan las incorporaciones posicionales en los enfoques de preentrenamiento contrastivo existentes y el reconocimiento de vocabulario abierto. Las incrustaciones de posición son importantes para los transformadores porque proporcionan información sobre el origen de cada elemento del conjunto. Esta información suele ser útil para tareas posteriores de detección y localización. Los enfoques de preentrenamiento generalmente aplican incorporaciones posicionales de fotograma completo durante el entrenamiento y utilizan las mismas incorporaciones posicionales para tareas posteriores, p. B. Detección de disparo cero. Sin embargo, el reconocimiento se realiza a nivel de región para afinar el reconocimiento de vocabulario abierto, lo que requiere que las incrustaciones de posición de imagen completa se generalicen a regiones que nunca ven durante el entrenamiento previo.
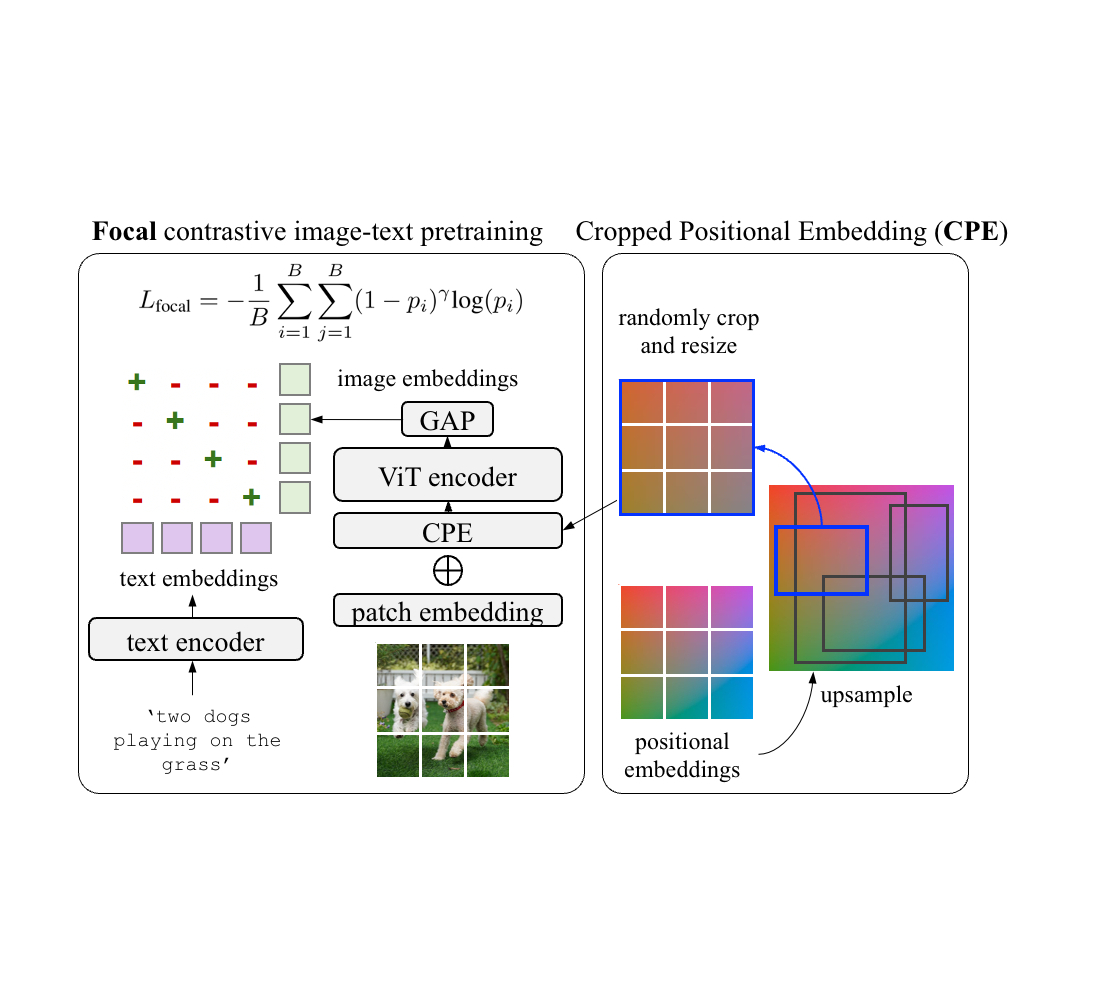
Para abordar esta cuestión proponemos incrustaciones de posición recortada (CPE). Usando CPE, tomamos muestras de incrustaciones de posición del tamaño de imagen típico para el entrenamiento previo, p. 224 x 224 píxeles, hasta el tamaño de imagen típico para tareas de reconocimiento, p. B. 1024 x 1024 píxeles. Luego recortamos y redimensionamos aleatoriamente una región y la usamos como incrustaciones de posición a nivel de imagen durante el entrenamiento previo. La posición, escala y relación de aspecto del recorte se eligen al azar. Intuitivamente, esto significa que el modelo no ve una imagen como una imagen completa por derecho propio, sino como una sección de una región de una imagen más grande y desconocida. Esto se asemeja más al caso de uso de detección posterior, donde la detección se realiza a nivel de región en lugar de a nivel de imagen.
 |
| Para el preescolar sugerimos incrustación de posición recortada (CPE) que recorta aleatoriamente y cambia el tamaño de un área con incrustaciones de posición en lugar de utilizar incrustaciones de posición de fotograma completo (PE). Además, para el aprendizaje contrastivo, utilizamos la pérdida de enfoque en lugar de la pérdida de entropía cruzada softmax habitual. |
También nos resulta útil aprender de ejemplos difíciles con pérdida de concentración. La pérdida de enfoque permite un control más detallado sobre la ponderación de los ejemplos difíciles que el que puede ofrecer la pérdida de entropía cruzada de softmax. Tomamos la pérdida de enfoque y la reemplazamos con la pérdida de entropía cruzada softmax tanto para pérdidas de imagen a texto como de texto a imagen. Tanto el CPE como la pérdida de enfoque no generan parámetros adicionales y generan costos computacionales mínimos.
Ajuste fino del detector de vocabulario abierto
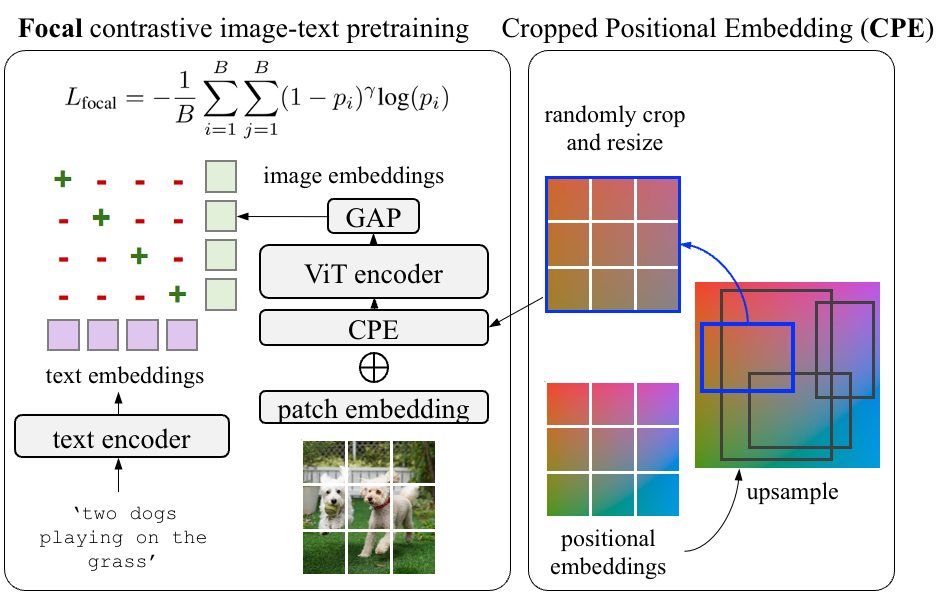
Un detector de vocabulario abierto se entrena con las etiquetas de reconocimiento de las categorías «base», pero debe reconocer la unión de las categorías «base» y «novedosa» (sin etiquetar) en el momento de la prueba. Aunque las funciones troncales se entrenan previamente a partir de los ricos datos de vocabulario abierto, las capas de detectores agregadas (cuello y cabezas) se vuelven a entrenar con el conjunto de datos de detección posteriores. Los enfoques existentes a menudo pasan por alto objetos novedosos/sin etiquetar en la fase de propuesta de objeto, ya que las propuestas tienden a clasificarlos como fondo. Para abordar esto, aprovechamos los avances recientes en un método novedoso de sugerencia de objetos y adoptamos la objetividad basada en la calidad de la localización (es decir, puntuación de centrado) en lugar de la puntuación de clasificación binaria de «objeto o no» combinada con la puntuación de reconocimiento. Durante el entrenamiento, calculamos las puntuaciones de reconocimiento para cada región reconocida como la similitud del coseno entre la inserción de la región (calculada mediante la operación RoI-Align) y las incrustaciones de texto de las categorías base. En el momento de la prueba, agregamos el texto incrustado de las categorías novedosas y la puntuación de reconocimiento ahora se calcula utilizando la unión de las categorías base y novedosa.
 |
| La columna vertebral de ViT previamente entrenada se transfiere al reconocimiento de vocabulario abierto posterior reemplazando la agrupación promedio global con cabezales detectores. Las incrustaciones de RoI-Align se comparan con las incrustaciones de categorías almacenadas en caché para obtener la puntuación VLM, que se combina con la puntuación de reconocimiento para obtener la puntuación de reconocimiento de vocabulario abierto. |
Resultados
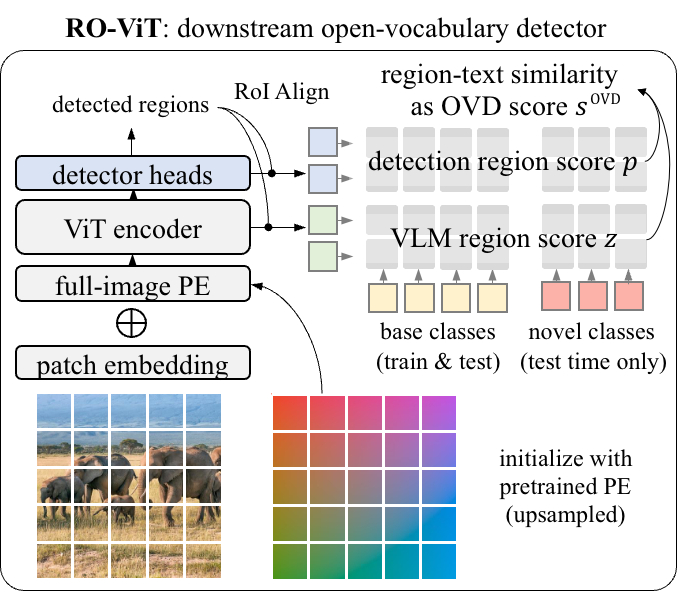
Evaluamos RO-ViT utilizando el punto de referencia LVIS para reconocer vocabulario abierto. A nivel de sistema, nuestro mejor modelo alcanza una precisión media de 33,6 cajas en categorías raras (AP).R) y máscara 32.1 APRque supera al mejor enfoque existente basado en ViT OWL-ViT por 8.0 APR y el mejor enfoque basado en CNN ViLD-Ens de 5.8 Mask APR. También supera a muchos otros enfoques basados en la destilación del conocimiento, la educación preescolar o la capacitación colaborativa con una supervisión débil.
 |
| RO-ViT supera a los métodos de última generación basados en ViT (SOTA) y CNN en el punto de referencia LVIS para el reconocimiento de vocabulario abierto. Mostramos la máscara AP en categorías raras (APR), excepto para SOTA ViT (OwL-ViT), donde mostramos Box AP. |
Además de evaluar la representación a nivel de región mediante el reconocimiento de vocabulario abierto, evaluamos la representación de RO-ViT a nivel de imagen en la recuperación de texto de imagen utilizando los puntos de referencia MS-COCO y Flickr30K. Nuestro modelo de 303 millones de ViT supera al modelo CoCa de última generación con 1.000 millones de ViT en MS COCO y está empatado en Flickr30K. Esto muestra que nuestro método de preentrenamiento mejora no solo la representación a nivel de región, sino también la representación a nivel de marco global para la recuperación.
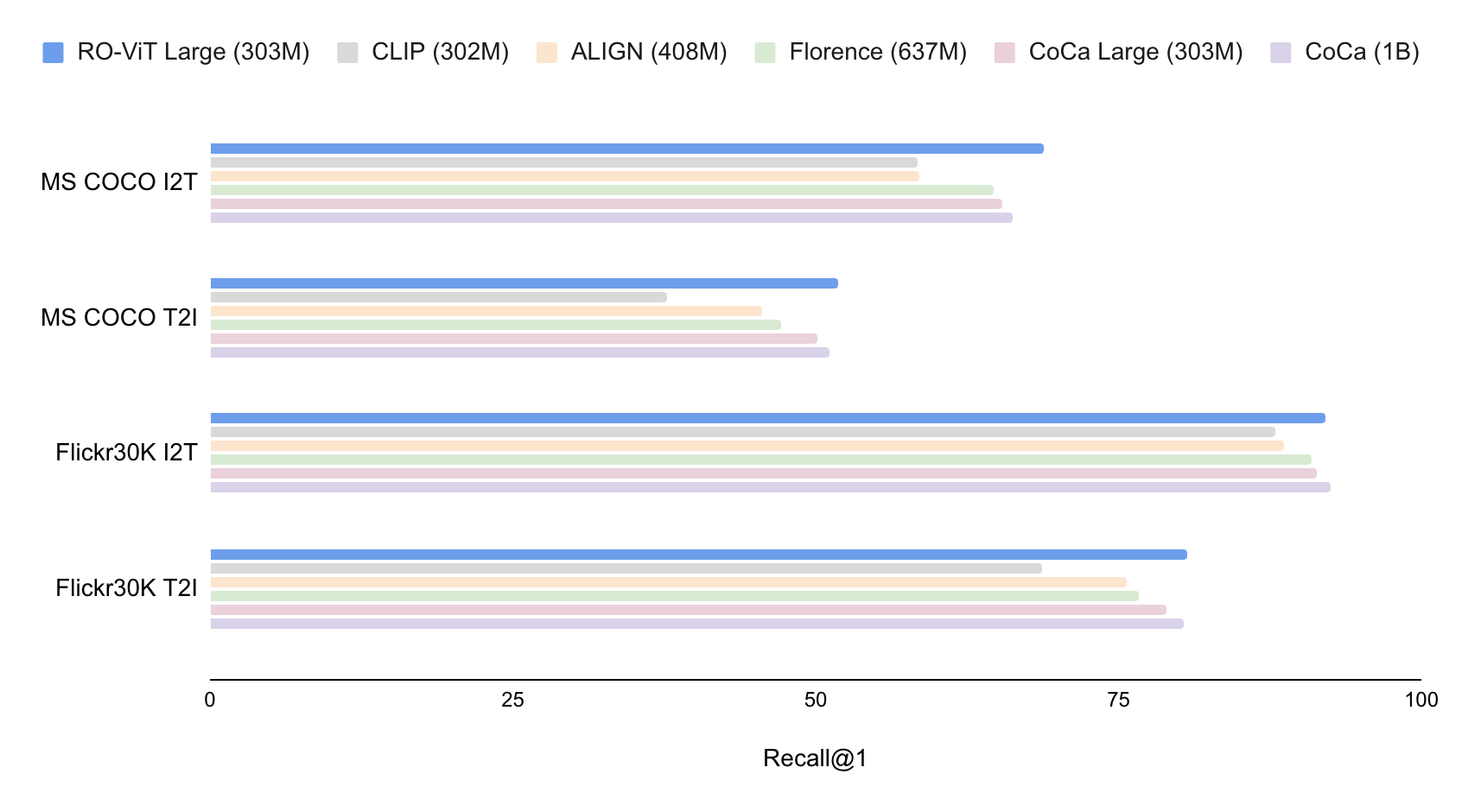 |
| Demostramos la recuperación de texto de imagen de disparo cero en los puntos de referencia de MS COCO y Flickr30K y la comparamos con métodos de codificador dual. Informamos sobre Recall@1 (primer retiro) sobre tareas de recuperación de imagen a texto (I2T) y texto a imagen (T2I). RO-ViT supera al CoCa de última generación con la misma columna vertebral. |
 |
| Reconocimiento RO-ViT de vocabulario abierto en LVIS. En aras de la claridad, solo mostramos las categorías novedosas. RO-ViT reconoce muchas categorías novedosas que nunca vio durante el entrenamiento de reconocimiento: «pecera», «sombrero», «caqui», «gárgola». |
Visualización de incrustaciones de posiciones.
Visualizamos y comparamos las incorporaciones de posiciones aprendidas de RO-ViT con la línea de base. Cada mosaico es la similitud coseno entre las incrustaciones de posición de un parche y todos los demás parches. Por ejemplo, el mosaico en la esquina superior izquierda (marcado en rojo) visualiza la similitud entre la posición incrustada de la ubicación (fila=1, columna=1) y las incrustaciones de posición de todas las demás ubicaciones en 2D. El brillo del parche indica qué tan cerca están las incrustaciones de posiciones aprendidas de diferentes ubicaciones. RO-ViT forma grupos más distintos en diferentes ubicaciones de parches, mostrando patrones globales simétricos alrededor del parche central.
 |
| Cada mosaico muestra la similitud del coseno entre la posición incrustada del parche (en la posición de fila-columna especificada) y las posiciones incrustadas de todos los demás parches. Se utiliza la columna vertebral ViT-B/16. |
Diploma
Presentamos RO-ViT, un marco de preentrenamiento contrastivo de imagen y texto para cerrar la brecha entre el preentrenamiento a nivel de imagen y el ajuste fino del reconocimiento de vocabulario abierto. Nuestros métodos son simples, escalables y se pueden aplicar fácilmente a todos los marcos contrastivos con un mínimo esfuerzo computacional y sin aumentar los parámetros. RO-ViT logra puntos de referencia de reconocimiento de vocabulario abierto LVIS de última generación y puntos de referencia de recuperación de texto de imagen, lo que demuestra que la representación aprendida no solo es beneficiosa a nivel de región, sino que también es extremadamente efectiva a nivel de imagen. Esperamos que este estudio pueda respaldar la investigación sobre el reconocimiento de vocabulario abierto desde la perspectiva del entrenamiento previo con imágenes y texto, que puede ser útil tanto en tareas a nivel regional como a nivel de imágenes.
gracias
Dahun Kim, Anelia Angelova y Weicheng Kuo hicieron este trabajo y ahora están en Google DeepMind. Nos gustaría agradecer a nuestros colegas de Google Research por sus consejos y útiles debates.
[ad_2]