
[ad_1]
Hoy en día, los modelos de IA generativa cubren una amplia gama de tareas, desde resúmenes de texto hasta preguntas y respuestas, pasando por la generación de imágenes y vídeos. Para mejorar la calidad del resultado, se utilizan enfoques como el aprendizaje n-corto, la ingeniería rápida, la generación aumentada de recuperación (RAG) y el ajuste fino. Al realizar ajustes, puede ajustar estos modelos de IA generativa para lograr un mejor rendimiento en las tareas específicas de su dominio.
Con Amazon SageMaker, ahora puede ejecutar un trabajo de capacitación de SageMaker simplemente anotando su código Python con @remote decorador. El SDK de Python de SageMaker traduce automáticamente su entorno de espacio de trabajo existente y todo el código y conjuntos de datos de procesamiento de datos asociados en un trabajo de capacitación de SageMaker que se ejecuta en la plataforma de capacitación. Esto tiene la ventaja de escribir el código de una manera más natural y orientada a objetos y al mismo tiempo aprovechar las funciones de SageMaker para ejecutar trabajos de capacitación con cambios mínimos en un clúster remoto.
En esta publicación, mostramos cómo refinar un Falcon-7B Foundation Models (FM) usando el decorador @remote del SDK de Python de SageMaker. La biblioteca PEFT (Parameter Efficient Fine Tuning) de Hugging Face y las técnicas de cuantificación de Bitsandbytes también se utilizan para respaldar el ajuste fino. El código presentado en este blog también se puede utilizar para ajustar otros FM como Llama-2 13b.
Las representaciones de precisión total de este modelo pueden ser difíciles de encajar en la memoria de una o incluso varias unidades de procesamiento de gráficos (GPU), o incluso pueden requerir una instancia más grande. Por lo tanto, para refinar este modelo sin aumentar costos, utilizamos la técnica conocida como LLM cuantificados con adaptadores de bajo rango (QLoRA). QLoRA es un enfoque de ajuste eficiente que reduce el uso de memoria de los LLM mientras mantiene un muy buen rendimiento.
Beneficios de usar @remote decorador
Antes de continuar, comprendamos cómo Remote Decorator mejora la productividad del desarrollador cuando trabaja con SageMaker:
- @remote decorador activa un trabajo de entrenamiento directamente usando código Python nativo, sin llamar explícitamente a los estimadores de SageMaker ni a los canales de entrada de SageMaker.
- Barrera de entrada baja para desarrolladores que entrenan modelos en SageMaker.
- No es necesario cambiar entre entornos de desarrollo integrados (IDE). Continúe escribiendo código en el IDE de su elección y accediendo a los trabajos de capacitación de SageMaker.
- No necesitas saber nada sobre contenedores. Continuar implementando dependencias en un
requirements.txty ponerlos a disposición del decorador remoto.
requisitos
Se requiere una cuenta de AWS con un rol de AWS Identity and Access Management (AWS IAM) y tiene permisos para administrar los recursos creados como parte de la solución. Para obtener más información, consulte Creación de una cuenta de AWS.
En esta publicación estamos utilizando Amazon SageMaker Studio con el Data Science 3.0 imagen y un ml.t3.medium Instancia de inicio rápido. Sin embargo, puede utilizar cualquier entorno de desarrollo integrado (IDE) de su elección. Todo lo que necesita hacer es configurar correctamente sus credenciales de AWS Command Line Interface (AWS CLI). Para obtener más información, consulte Configurar la AWS CLI.
El Falcon 7B se utiliza para realizar ajustes ml.g5.12xlarge Esta publicación usa la instancia. Asegúrese de que haya suficiente capacidad en la cuenta de AWS para esta instancia.
Deberá clonar este repositorio de Github para replicar la solución que se muestra en esta publicación.
Descripción general de la solución
- Instale los requisitos previos para ajustar el modelo Falcon 7B
- Configurar configuraciones de decorador remoto
- Preprocesar el conjunto de datos de preguntas frecuentes de los servicios de AWS
- Optimice Falcon-7B en las preguntas frecuentes sobre servicios de AWS
- Pruebe los modelos de ajuste con preguntas de muestra sobre los servicios de AWS
1. Instale los requisitos previos para ajustar el modelo Falcon 7B
Inicie el cuaderno falcon-7b-qlora-remote-decorator_qa.ipynb en SageMaker Studio seleccionando Imago como Data Science Y núcleo como Python 3. Instale todas las bibliotecas necesarias enumeradas en el requirements.txt. Algunas de las bibliotecas deben instalarse en la propia instancia del portátil. Realice otras operaciones necesarias para procesar conjuntos de datos y activar un trabajo de capacitación de SageMaker.
2. Establecer configuraciones de decorador remoto
Cree un archivo de configuración que especifique todas las configuraciones relacionadas con el trabajo de capacitación de Amazon SageMaker. El decorador @remote lee este archivo mientras se ejecuta el trabajo de entrenamiento. Este archivo contiene configuraciones como dependencias, imagen de entrenamiento, instancia y la función de ejecución que se utilizará para el trabajo de entrenamiento. Para obtener una referencia detallada de todas las configuraciones admitidas por el archivo de configuración, consulte Configurar y usar la configuración predeterminada con SageMaker Python SDK.
No es obligatorio utilizar este config.yaml Archivo para poder trabajar con el decorador @remote. Esta es solo una forma más limpia de proporcionar todas las configuraciones al decorador @remote. Esto mantiene los parámetros relacionados con SageMaker y AWS fuera del código y elimina un esfuerzo único para configurar el archivo de configuración que utilizan todos los miembros del equipo. Todas las configuraciones también podrían proporcionarse directamente en los argumentos del decorador, pero esto reduce la legibilidad y la mantenibilidad de los cambios a largo plazo. Además, un administrador puede crear el archivo de configuración y compartirlo con todos los usuarios de un entorno.
Preprocesar el conjunto de datos de preguntas frecuentes de los servicios de AWS
El siguiente paso es cargar y preprocesar el conjunto de datos para prepararlo para el trabajo de entrenamiento. Primero veamos el conjunto de datos:
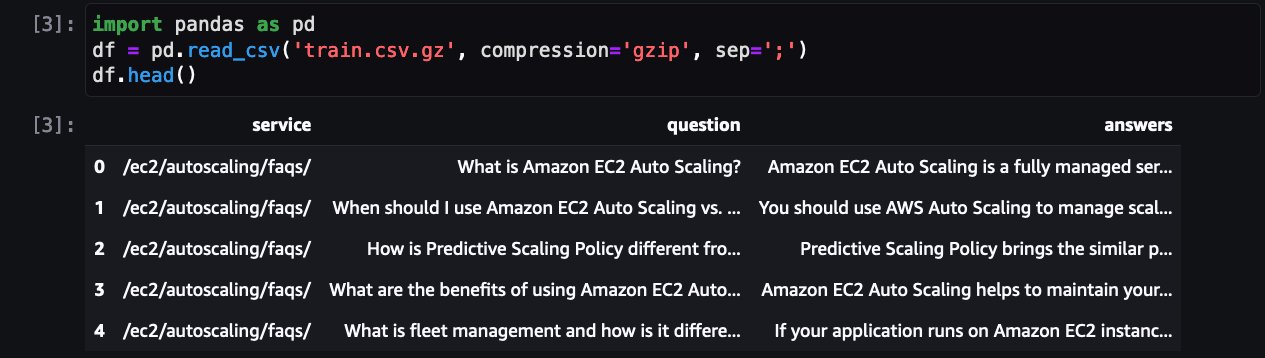
Muestra preguntas frecuentes sobre uno de los servicios de AWS. Además de QLoRA, bitsanbytes se utiliza para convertir a precisión de 4 bits, para cuantificar LLM congelado a 4 bits y conectarle adaptadores LoRA.
Cree una plantilla de mensaje para convertir cada ejemplo de preguntas frecuentes a un formato de mensaje:
El siguiente paso es convertir las entradas (texto) en ID de token. Esto se hace a través de un tokenizador de Transformers Hugging Face.
Solo úsalo ahora prompt_template Función para convertir todas las preguntas frecuentes a formato de solicitud y configurar conjuntos de datos de entrenamiento y prueba.

4. Ajuste el Falcon-7B en las preguntas frecuentes sobre servicios de AWS
Ahora puedes preparar el guión de entrenamiento y definir la función de entrenamiento. train_fn y configure @remote decorador en la función.
La función de entrenamiento hace lo siguiente:
- tokeniza y segmenta el conjunto de datos
- configuración
BitsAndBytesConfigque especifica que el modelo debe cargarse en 4 bits pero convertirse durante el cálculobfloat16. - Cargar el modelo
- Encuentre módulos de destino y actualice las matrices requeridas utilizando el método de utilidad
find_all_linear_names - Crear lora Configuraciones que determinan el ranking de las matrices de actualización (
s), factor de ampliación, factor de reducción (lora_alpha), los módulos para aplicar las matrices de actualización LoRA (target_modules), probabilidad de falla para las capas Lora (lora_dropout),task_typeetc. - Comience con capacitación y evaluación
Y llama a eso train_fn()
El trabajo de optimización se ejecutaría en el clúster de capacitación de Amazon SageMaker. Espere a que se complete el trabajo de ajuste.
5. Pruebe los modelos de ajuste utilizando preguntas de muestra sobre los servicios de AWS.
Ahora es el momento de hacer algunas pruebas en el modelo. Primero carguemos el modelo:
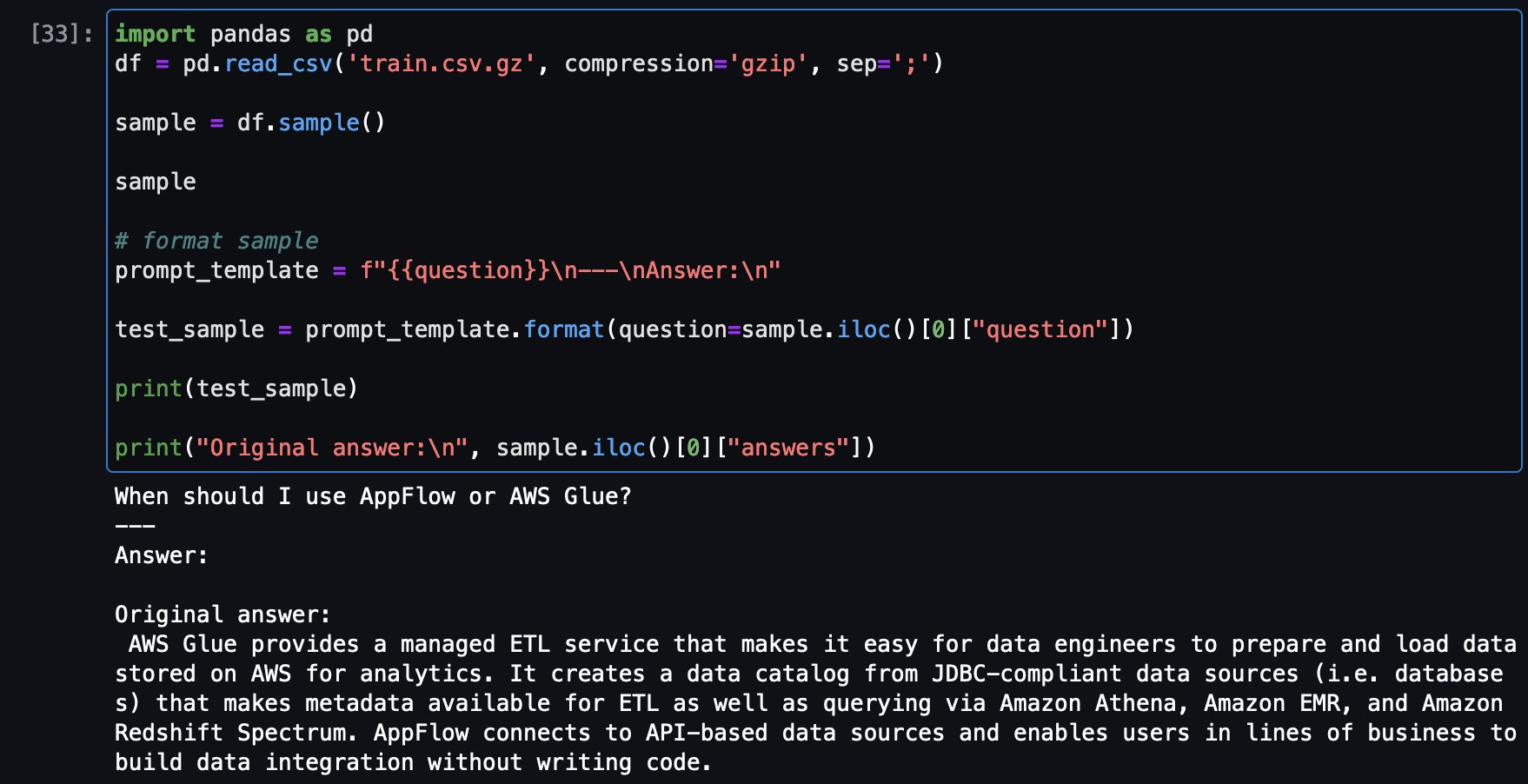
Ahora cargue una pregunta de muestra del conjunto de datos de entrenamiento para ver la respuesta original, luego haga la misma pregunta desde el modelo optimizado para ver la respuesta en comparación.
A continuación se muestra un ejemplo de una pregunta del conjunto de capacitación y la respuesta original:
Ahora se hace la misma pregunta sobre el modelo Falcon 7B sintonizado:
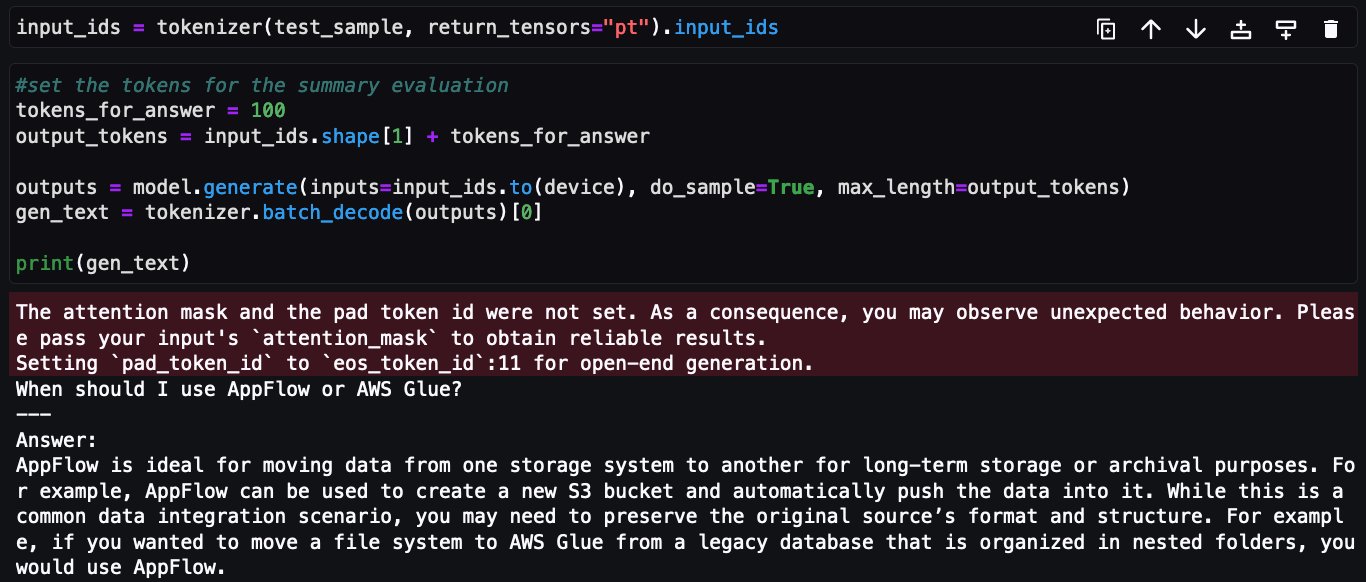
Esto completa la implementación del ajuste de Falcon-7B en el conjunto de datos de preguntas frecuentes para los servicios de AWS utilizando el decorador @remote del SDK de Python de Amazon SageMaker.
Limpiar
Para limpiar sus recursos, siga estos pasos:
- Cierre las instancias de Amazon SageMaker Studio para evitar costos adicionales.
- Limpie su directorio de Amazon Elastic File System (Amazon EFS) eliminando el directorio de caché de Hugging Face:
Diploma
En esta publicación, le mostramos cómo usar de manera efectiva las funciones del decorador @remote para ajustar el modelo Falcon 7B usando QLoRA y Hugging Face PEFT. bitsandbtyes sin realizar cambios significativos en el cuaderno de capacitación y aprovechar las funciones de Amazon SageMaker para ejecutar trabajos de capacitación en un clúster remoto.
Todo el código de ajuste fino de Falcon-7B que se muestra en esta publicación está disponible en el repositorio de GitHub. El repositorio también contiene un cuaderno que muestra el ajuste de Llama-13B.
Como siguiente paso, le recomendamos que pruebe la funcionalidad del decorador @remote y la API del SDK de Python y los utilice en el entorno y el IDE de su elección. Hay ejemplos adicionales disponibles en el repositorio de ejemplos de Amazon Sagemaker para que pueda comenzar rápidamente. También puedes consultar las siguientes publicaciones:
Sobre los autores
 Bruno Pistone es un arquitecto de soluciones especializado en IA/ML para AWS con sede en Milán. Trabaja con grandes clientes, ayudándolos a comprender en profundidad sus necesidades técnicas y a desarrollar soluciones de inteligencia artificial y aprendizaje automático que aprovechen al máximo la nube de AWS y el aprendizaje automático de Amazon. Su experiencia incluye: aprendizaje automático de un extremo a otro, industrialización del aprendizaje automático e inteligencia artificial generativa. Le gusta pasar tiempo con sus amigos, explorar nuevos lugares y viajar a nuevos destinos.
Bruno Pistone es un arquitecto de soluciones especializado en IA/ML para AWS con sede en Milán. Trabaja con grandes clientes, ayudándolos a comprender en profundidad sus necesidades técnicas y a desarrollar soluciones de inteligencia artificial y aprendizaje automático que aprovechen al máximo la nube de AWS y el aprendizaje automático de Amazon. Su experiencia incluye: aprendizaje automático de un extremo a otro, industrialización del aprendizaje automático e inteligencia artificial generativa. Le gusta pasar tiempo con sus amigos, explorar nuevos lugares y viajar a nuevos destinos.
 vikesh pandey es arquitecto de soluciones de aprendizaje automático en AWS y ayuda a clientes financieros a diseñar y crear soluciones generativas de inteligencia artificial y aprendizaje automático. Fuera del trabajo, a Vikesh le gusta probar diferentes platos y hacer ejercicio al aire libre.
vikesh pandey es arquitecto de soluciones de aprendizaje automático en AWS y ayuda a clientes financieros a diseñar y crear soluciones generativas de inteligencia artificial y aprendizaje automático. Fuera del trabajo, a Vikesh le gusta probar diferentes platos y hacer ejercicio al aire libre.
[ad_2]