
[ad_1]

CIFRAS (sumas de árboles codiciosos rápidamente interpretables): Un método para crear modelos interpretables mediante el crecimiento simultáneo de un conjunto de árboles de decisión que compiten entre sí.
Los avances recientes en el aprendizaje automático han dado como resultado modelos predictivos cada vez más complejos, a menudo a expensas de la interpretabilidad. A menudo necesitamos interpretabilidad, especialmente en aplicaciones de alto riesgo como B. en la toma de decisiones clínicas; Los modelos interpretables ayudan con todo tipo de cosas, p. B. en la identificación de errores, el uso del conocimiento del dominio y la predicción rápida.
En esta publicación de blog, cubriremos FIGS, una nueva forma de personalizar un modelo interpretable que toma la forma de una suma de árboles. Los experimentos del mundo real y los resultados teóricos demuestran que los FIG pueden adaptarse de manera efectiva a una variedad de estructuras de datos y lograr un rendimiento de vanguardia en múltiples entornos sin comprometer la interpretabilidad.
¿Cómo funciona FIG?
Intuitivamente, FIG funciona extendiendo CART, un algoritmo codicioso típico para hacer crecer un árbol de decisiones, para dar cuenta del crecimiento de un total de arboles simultaneamente (ver figura 1). En cada iteración, FIGS puede extender cualquier árbol existente que ya haya iniciado, o iniciar un nuevo árbol; elige con avidez la regla que reduce más la varianza total no explicada (o un criterio de partición alternativo). Para mantener los árboles sincronizados entre sí, cada árbol está hecho para predecir sobras permanecen después de sumar las predicciones de todos los demás árboles (consulte el documento para obtener más detalles).
FIGS es intuitivamente similar a los enfoques de conjunto, como el aumento de gradiente/bosque aleatorio, pero lo más importante es que, dado que todos los árboles crecen para competir entre sí, el modelo puede adaptarse mejor a la estructura subyacente de los datos. La cantidad de árboles y el tamaño/forma de cada árbol provienen automáticamente de los datos en lugar de establecerse manualmente.

Figura 1. Alta intuición de cómo FIGS se ajusta a un modelo.
un ejemplo con FIGS
Usar FIG es extremadamente fácil. Se puede instalar fácilmente a través del paquete imodels (pip install imodels) y luego se puede usar de la misma manera que los modelos estándar de scikit-learn: solo importa un clasificador o regresor y usa el fit y predict métodos. Aquí hay un ejemplo completo para usar en un conjunto de datos clínicos de muestra donde el objetivo es el riesgo de lesión de la columna cervical (CSI).
from imodels import FIGSClassifier, get_clean_dataset
from sklearn.model_selection import train_test_split
# prepare data (in this a sample clinical dataset)
X, y, feat_names = get_clean_dataset('csi_pecarn_pred')
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.33, random_state=42)
# fit the model
model = FIGSClassifier(max_rules=4) # initialize a model
model.fit(X_train, y_train) # fit model
preds = model.predict(X_test) # discrete predictions: shape is (n_test, 1)
preds_proba = model.predict_proba(X_test) # predicted probabilities: shape is (n_test, n_classes)
# visualize the model
model.plot(feature_names=feat_names, filename='out.svg', dpi=300)
Esto da como resultado un modelo simple: solo contiene 4 divisiones (ya que especificamos que el modelo no debe tener más de 4 divisiones (max_rules=4). Las predicciones se hacen dejando caer una muestra en cada árbol y resumir los valores de ajuste de riesgo obtenidos de las hojas resultantes de cada árbol. Este modelo es altamente interpretable ya que un médico ahora puede (i) hacer predicciones fácilmente utilizando las 4 características relevantes y (ii) verificar el modelo para asegurarse de que sea consistente con su experiencia. Tenga en cuenta que este modelo es solo para fines ilustrativos y logra una precisión de ~84%.

Figura 2. Modelo simple aprendido de FIG para predecir el riesgo de lesión de la columna cervical.
Si queremos un modelo más flexible, también podemos eliminar el límite en el número de reglas (cambiando el código a model = FIGSClassifier()), resultando en un modelo más grande (ver Fig. 3). Tenga en cuenta que el número de árboles y su equilibrio están determinados por la estructura de los datos; solo se puede especificar el número total de reglas.

Fig. 3. Modelo aprendido de FIG ligeramente más grande para predecir el riesgo de lesión de la columna cervical.
¿Qué tan bien se desempeña FIG?
En muchos casos en los que se desea la interpretabilidad, p. al modelar las reglas de decisión clínica, FIG puede lograr un rendimiento de vanguardia. Por ejemplo, la Fig. 4 muestra varios conjuntos de datos en los que los FIG funcionan de manera excelente, especialmente cuando se limitan a usar muy pocas divisiones generales.
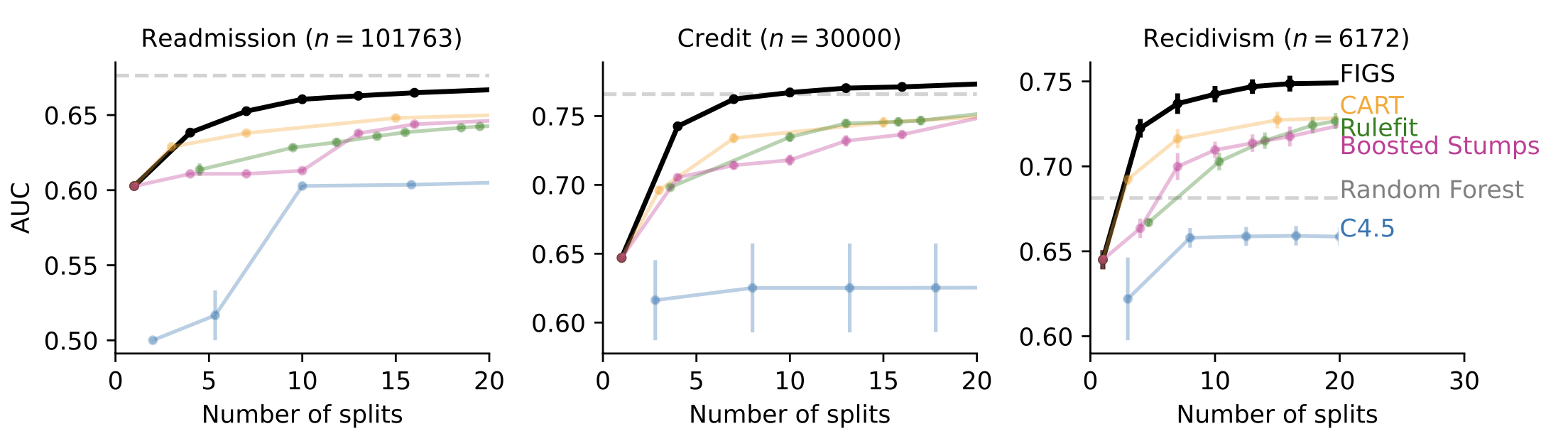
Figura 4. FIG predice bien con muy pocas divisiones.
¿Por qué a la FIG le va bien?
Los FIG están motivados por la observación de que los árboles de decisión individuales a menudo tienen divisiones que se repiten en diferentes ramas, lo que puede ocurrir cuando hay una estructura aditiva en los datos. Tener varios árboles ayuda a evitar esto al separar los componentes aditivos en árboles separados.
Conclusión
En general, el modelado interpretable ofrece una alternativa al modelado de caja negra tradicional y, en muchos casos, puede proporcionar mejoras masivas en eficiencia y transparencia sin sacrificar el rendimiento.
Esta publicación se basa en dos documentos: FIGS y G-FIGS: todo el código está disponible a través del paquete imodels. Este es un esfuerzo de colaboración con Keyan Nasseri, Abhineet Agarwal, James Duncan, Omer Ronen y Aaron Kornblith.
[ad_2]