
[ad_1]
TLDR: Te sugerimos robustez certificada asimétrica Problema que requiere robustez certificada para una sola clase y refleja escenarios adversarios del mundo real. Esta configuración enfocada nos permite introducir clasificadores de características convexas que producen radios certificados cerrados y deterministas del orden de milisegundos.

Figura 1. Ilustración de clasificadores convexos de características y su certificación para entradas de clases sensibles. Esta arquitectura crea un mapa de características continuo de Lipschitz $\varphi$ con una función convexa aprendida $g$. Dado que $g$ es convexo, su plano tangente en $\varphi(x)$ lo subestima globalmente, lo que lleva a bolas de normas certificadas en el espacio de características. El lipschitzness de $\varphi$ da como resultado certificados escalados correspondientemente en el espacio de entrada original.
A pesar de su uso generalizado, los clasificadores de aprendizaje profundo son extremadamente vulnerables ejemplos controvertidos: Pequeñas perturbaciones de imágenes imperceptibles para los humanos que engañan a los modelos de aprendizaje automático para que clasifiquen incorrectamente la entrada modificada. Esta debilidad afecta significativamente la confiabilidad de los procesos críticos para la seguridad que involucran el aprendizaje automático. Se han propuesto muchas defensas empíricas contra la interferencia adversaria, pero a menudo fueron derrotadas posteriormente por estrategias de ataque más fuertes. Por lo tanto nos centramos en clasificadores robustos probadosque proporcionan una garantía matemática de que su predicción para una bola normal $\ell_p$ permanece constante alrededor de una entrada.
Los métodos tradicionales de robustez certificada tienen una serie de desventajas, que incluyen el no determinismo, la ejecución lenta, el escalamiento deficiente y la certificación frente a una sola norma de ataque. Sostenemos que estos problemas pueden resolverse refinando el problema de robustez certificada para adaptarlo mejor a situaciones prácticas adversas.
El problema de la robustez certificada asimétrica
Los clasificadores certificablemente robustos actuales producen certificados para insumos que pertenecen a cualquier clase. Para muchas aplicaciones adversas del mundo real, esto es innecesariamente amplio. Considere el caso de alguien que redacta un correo electrónico de phishing mientras intenta eludir los filtros de spam. Este adversario siempre intentará engañar al filtro de spam haciéndole creer que su correo electrónico no deseado es inofensivo, nunca al revés. En otras palabras, El atacante simplemente intenta generar falsos negativos desde el clasificador.. Configuraciones similares incluyen detección de malware, señalización de noticias falsas, detección de bots en redes sociales, filtrado de reclamos de seguros médicos, detección de fraude financiero, detección de sitios web de phishing y más.
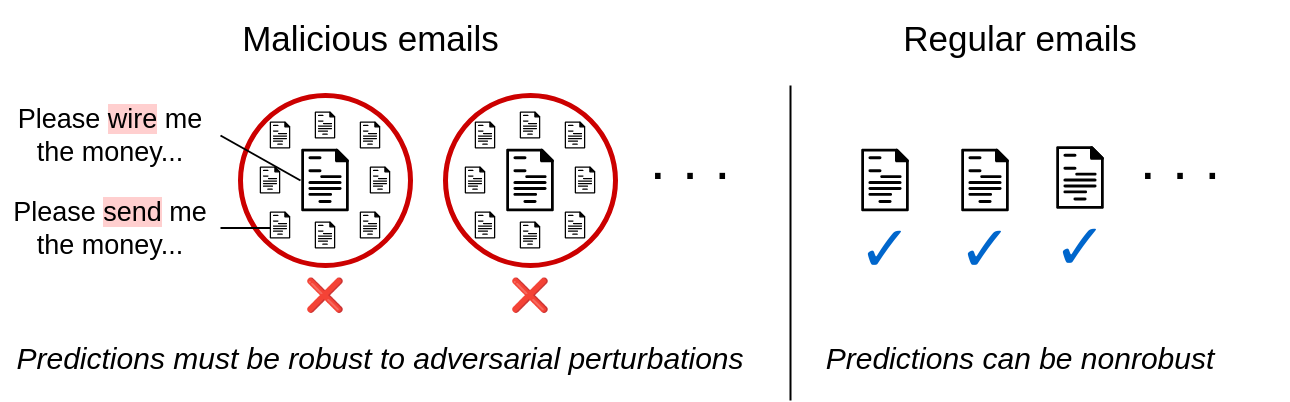
Figura 2. Robustez asimétrica en el filtrado de correo electrónico. Las situaciones prácticas de confrontación a menudo solo requieren solidez certificada para una clase.
Todas estas aplicaciones incluyen una configuración de clasificación binaria con un clase sensible que un adversario está tratando de evitar (por ejemplo, la clase de “correo electrónico no deseado”). Esto motiva el problema de robustez certificada asimétricaEl objetivo es proporcionar predicciones demostrablemente sólidas para las entradas de la clase sensible y al mismo tiempo mantener una precisión alta y limpia para todas las demás entradas. Proporcionamos un planteamiento del problema más formal en el texto principal.
Clasificadores convexos de características
Te sugerimos Característica de redes neuronales convexas. para abordar el problema de la robustez asimétrica. Esta arquitectura crea un mapa de características continuo de Lipschitz simple ${\varphi: \mathbb{R}^d \to \mathbb{R}^q}$ con una entrada aprendida Red neuronal convexa (ICNN) ${g: \ mathbb {R }^q \to \mathbb {R}}$ (Figura 1). Las ICNN imponen la convexidad desde el logit de entrada al de salida componiendo no linealidades ReLU con matrices de peso no negativas. Dado que una región de decisión binaria de ICNN consta de un conjunto convexo y su complemento, agregamos el mapa de características precompuesto $\varphi$ para habilitar regiones de decisión no convexas.
Los clasificadores convexos de características permiten el cálculo rápido de radios de clase sensibles certificados para todas las normas $\ell_p$. Partiendo del hecho de que las funciones convexas no son suficientemente aproximadas globalmente por cada plano tangente, podemos obtener un radio certificado en el espacio de características intermedio. Este radio luego se transfiere al espacio de entrada usando Lipschitzness. La configuración asimétrica es crucial aquí porque esta arquitectura solo produce certificados para la clase logit positiva $g(\varphi(x)) > 0$.
La fórmula resultante del radio certificado por la norma $\ell_p$ es particularmente elegante:
\[r*p(x) = \frac{ \color{blue}{g(\varphi(x))} } { \mathrm{Lip}\_p(\varphi) \color{red}{\| \nabla g(\varphi(x)) \| *{p,\*}}}.\]
Los términos no constantes son fáciles de interpretar: el radio aumenta proporcionalmente a la Confianza del clasificador y viceversa Sensibilidad del clasificador.. Evaluamos estos certificados en una variedad de conjuntos de datos y logramos certificados $\ell_1$ competitivos, así como certificados $\ell_2$ y $\ell_{\infty}$ comparables, aunque otros métodos generalmente se adaptan a un estándar específico y requieren pedidos de magnitud más tiempo de ejecución.
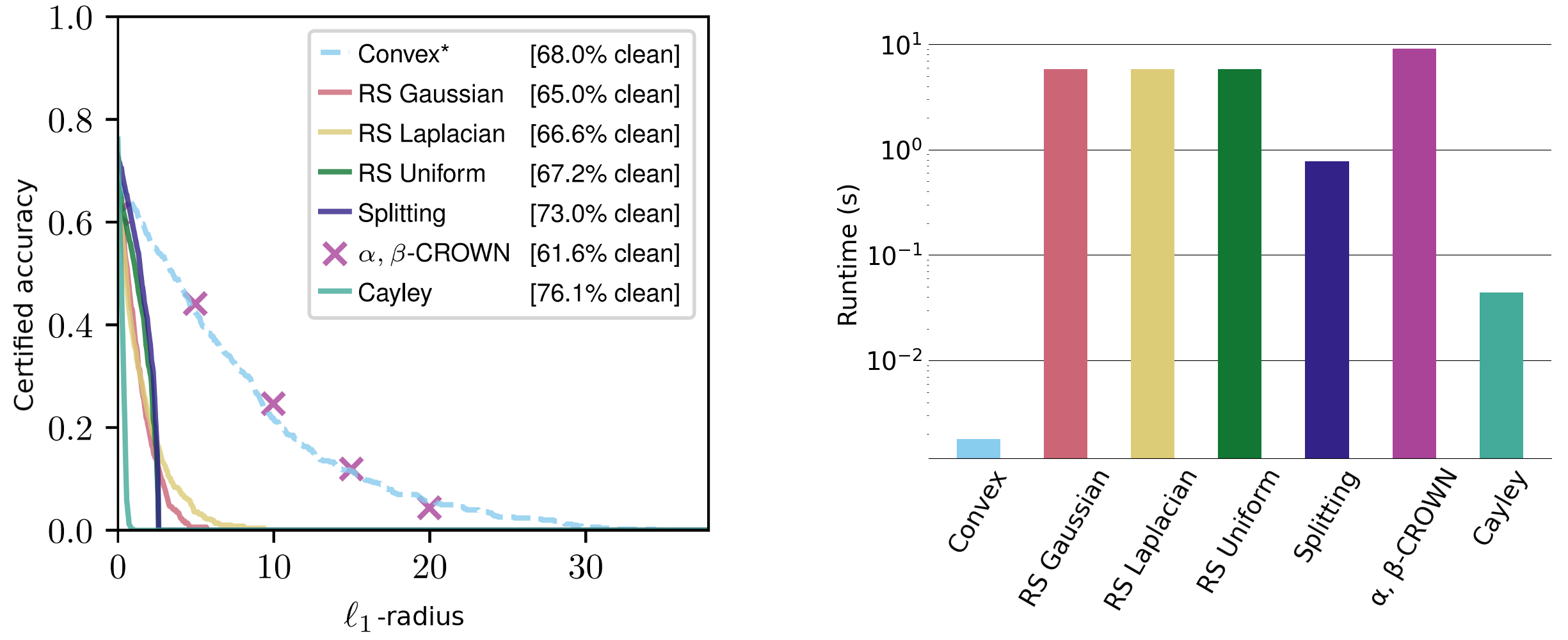
Figura 3. Radios de clases sensibles certificados en el conjunto de datos de gatos versus perros CIFAR-10 para la norma $\ell_1$. Los tiempos de viaje de la derecha se promedian sobre radios $\ell_1$, $\ell_2$ y $\ell_{\infty}$ (tenga en cuenta la escala logarítmica).
Nuestros certificados se aplican a cualquier norma $\ell_p$, son de forma cerrada y deterministas, y requieren solo un paso hacia adelante y hacia atrás por entrada. Estos se pueden calcular en el orden de milisegundos y escalar bien con el tamaño de la red. A modo de comparación: los métodos actuales, como el suavizado aleatorio y la propagación limitada por intervalos, normalmente requieren varios segundos para certificar incluso redes pequeñas. Los métodos de suavizado aleatorio también son inherentemente no deterministas, ya que los certificados sólo son válidos con un alto grado de probabilidad.
Promesa teórica
Si bien los resultados iniciales son prometedores, nuestro trabajo teórico sugiere que existe un importante potencial sin explotar en las ICNN, incluso sin un mapa de características. Aunque las ICNN binarias se limitan al aprendizaje de regiones de decisión convexas, demostramos que existe una ICNN que logra una precisión de entrenamiento perfecta en el conjunto de datos de gato versus perro CIFAR-10.
Hecho. Hay un clasificador convexo de entrada que logra una precisión de entrenamiento perfecta en el conjunto de datos de perros y gatos CIFAR-10.
Sin embargo, nuestra arquitectura sin un mapa de características solo logra una precisión de entrenamiento del 73,4%. Si bien el rendimiento del entrenamiento no implica una generalización del conjunto de pruebas, este resultado sugiere que las ICNN son, al menos teóricamente, capaces de lograr el paradigma moderno de aprendizaje automático de sobreajuste al conjunto de datos de entrenamiento. Por lo tanto planteamos el siguiente problema abierto para el campo.
Problema abierto. Aprenda un clasificador convexo de entrada que logra una precisión de entrenamiento perfecta en el conjunto de datos de perros y gatos CIFAR-10.
Diploma
Esperamos que el marco de robustez asimétrica inspire arquitecturas novedosas que sean certificables en este entorno más enfocado. Nuestro clasificador convexo de características es una arquitectura de este tipo y proporciona radios rápidos y certificados de manera determinista para cualquier norma $\ell_p$. También presentamos el problema abierto de sobreajustar el conjunto de datos de entrenamiento de perros y gatos CIFAR-10 con una ICNN, lo que creemos que es teóricamente posible. Para obtener más información, consulte nuestro artículo y código base de NeurIPS.
[ad_2]