[ad_1]
Los métodos actuales de aprendizaje por refuerzo profundo (RL) pueden entrenar agentes artificiales especializados que se destacan en la toma de decisiones en varias tareas individuales en entornos específicos como Go o StarCraft. Sin embargo, se ha avanzado poco para extender estos resultados a agentes generalistas que no solo serían capaces de realizar muchas tareas diferentes, sino también en una variedad de entornos con realizaciones potencialmente diferentes.
Si observamos los avances recientes en el procesamiento del lenguaje natural, el procesamiento de imágenes y los modelos generativos (como PaLM, Imagen y Flamingo), vemos que los avances en la construcción de modelos de propósito general a menudo se logran escalando modelos basados en Transformer y entrenándolos. en conjuntos de datos grandes y semánticamente diversos. Es natural preguntarse si se puede usar una estrategia similar para construir agentes generalistas para la toma de decisiones secuenciales. ¿Estos modelos también pueden permitir una rápida adaptación a nuevas tareas, similar a PaLM y Flamingo?
Como primer paso para responder a estas preguntas, examinamos cómo crear un agente generalista para jugar muchos videojuegos simultáneamente en nuestro artículo reciente, Transformadores de decisiones de juegos múltiples. Nuestro modelo entrena a un agente que puede jugar 41 juegos de Atari simultáneamente con un rendimiento similar al humano y también puede sintonizarse rápidamente con nuevos juegos. Este enfoque mejora las pocas alternativas existentes para el aprendizaje de agentes multijuego, como
 |
| Un Multi-Game Decision Transformer (MGDT) puede jugar múltiples juegos en el nivel de habilidad deseado a partir del entrenamiento en una variedad de trayectorias que abarcan todos los niveles de habilidad. |
No optimices para obtener devoluciones, solo pide optimización
en el aprendizaje por refuerzo, premio se refiere a las señales de incentivos relevantes para la realización de una tarea, y devolver se refiere a acumulativo Recompensas en un curso de interacciones entre un agente y su entorno. Los agentes convencionales de aprendizaje por refuerzo profundo (DQN, SimPLe, Dreamer, etc.) están capacitados en él Optimice las decisiones para obtener la mejor rentabilidad. En cada paso de tiempo, un agente observa el entorno (algunos también consideran las interacciones que han tenido lugar en el pasado) y decide qué acciones tomar para ayudarse a sí mismo a generar un mayor rendimiento en futuras interacciones.
En este trabajo, usamos Decision Transformers como nuestro enfoque principal para capacitar a un agente de RL. Un transformador de decisión es un modelo de secuencia que predice acciones futuras considerando interacciones pasadas entre un agente y el entorno y (lo más importante) uno deseado. devolver lograr en futuras interacciones. En lugar de aprender una política para lograr un alto ROI, como en el aprendizaje de refuerzo tradicional, Decision Transformers mapea diferentes experiencias, que van desde el nivel de experto hasta el de novato, y el ROI correspondiente durante la capacitación. La idea es que capacitar a un agente en una variedad de experiencias (desde el nivel de principiante hasta el de experto) expone al modelo a una gama más amplia de variaciones del juego, lo que a su vez les ayuda a extraer reglas de juego útiles que les permitan jugar en todas las circunstancias para tener éxito. . Por lo tanto, durante la inferencia, Decision Transformer puede lograr cualquier valor de retorno en el rango que vio durante el entrenamiento, incluido el retorno óptimo.
Pero, ¿cómo saber si un rendimiento es óptimo y estable en un entorno determinado? Las aplicaciones anteriores de Decision Transformers se basaban en definiciones personalizadas del rendimiento deseado para cada tarea individual, lo que requería definir manualmente un rango plausible e informativo de valores escalares que son señales razonablemente interpretables para cada juego específico, una tarea que no es trivial y bastante inescalable es . En su lugar, para abordar este problema, modelamos una distribución de tamaños de devolución basada en interacciones previas con el entorno durante el entrenamiento. En el momento de la inferencia, simplemente agregamos un sesgo de optimización que aumenta la probabilidad de generar acciones asociadas con mayores rendimientos.
Para capturar de manera más completa los patrones espacio-temporales de las interacciones agente-entorno, también modificamos la arquitectura del Transformador de decisiones para considerar las manchas de imagen en lugar de una representación de imagen global. Los parches permiten que el modelo se centre en la dinámica local, lo que ayuda a modelar la información específica del juego con más detalle.
Juntas, estas partes forman la columna vertebral de Multi-Game Decision Transformers:
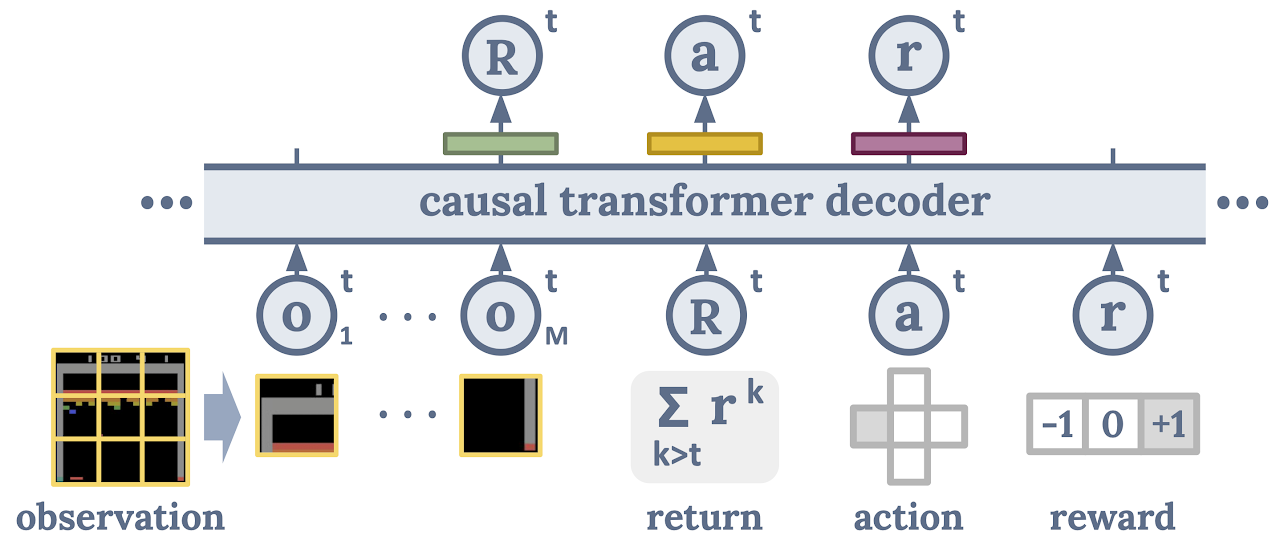 |
| Cada imagen de observación se divide en un conjunto METRO Parches de píxeles que están etiquetados O. Regresar Racción ay recompensa Correcto sigue estos parches de imagen en cada secuencia de entrada aleatoria. Se entrena a un Transformador de decisión para predecir la siguiente entrada (excepto las manchas de imagen) para establecer la causalidad. |
Entrena un Transformador de decisiones multijuego para jugar 41 juegos simultáneamente
Estamos entrenando a un agente de Decision Transformer con una gran (~ 1B) y amplia gama de experiencias de juego de 41 juegos de Atari. En nuestros experimentos, este agente, al que llamamos Multi-Game Decision Transformer (MGDT), supera significativamente el aprendizaje por refuerzo y los métodos de clonación de comportamiento existentes, casi al doble, al aprender a jugar 41 juegos simultáneamente y logra una competencia casi humana (100% en la figura siguiente corresponde al nivel de juego humano). Estos resultados se aplican cuando se comparan métodos de capacitación en entornos en los que es necesario aprender una política a partir de conjuntos de datos estáticos (fuera de línea) y aquellos en los que se pueden recopilar nuevos datos a partir de la interacción con el entorno (en línea).
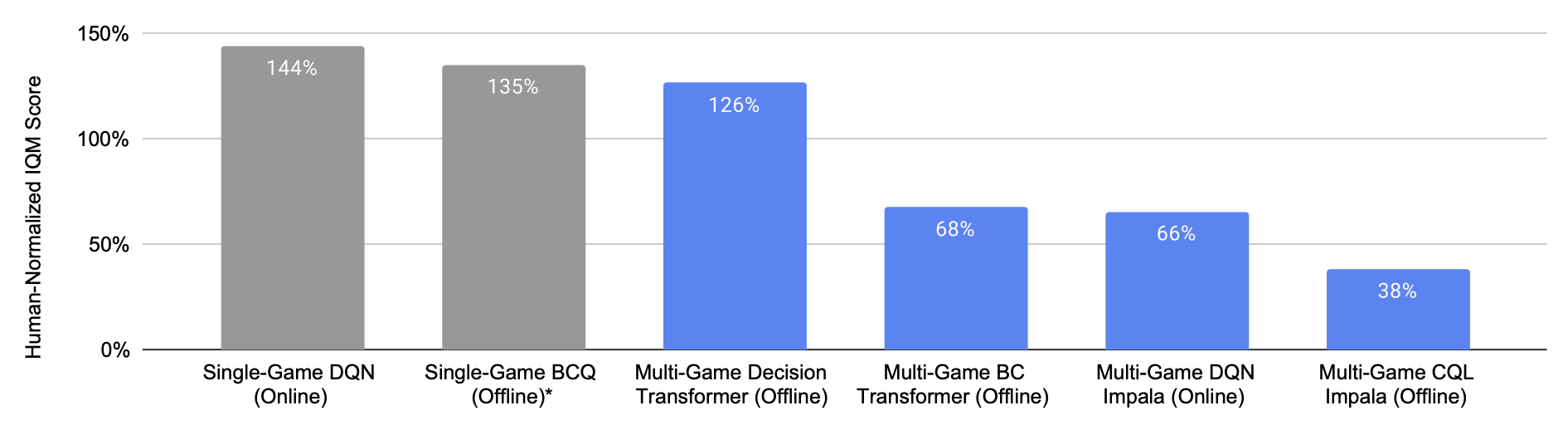 |
| Cada barra es una puntuación combinada de 41 juegos, con un 100 % que indica un rendimiento a nivel humano. Cada barra azul es de un modelo entrenado en 41 juegos simultáneamente, mientras que cada barra gris es de 41 agentes especializados. Multi-Game Decision Transformer logra un rendimiento a nivel humano, significativamente mejor que otros agentes de multijuegos, incluso comparable a los agentes especializados. |
Este resultado muestra que Decision Transformers es ideal para agentes con múltiples tareas, múltiples entornos y múltiples formas de realización.
Un trabajo concurrente, A Generalist Agent, muestra un resultado similar, mostrando que los grandes modelos de secuencia basados en Transformer son muy buenos para almacenar el comportamiento experto en muchos más entornos. Además, su trabajo y el nuestro tienen resultados bien complementarios: muestran que es posible entrenar en una variedad de entornos más allá de los juegos de Atari, mientras que nosotros mostramos que es posible y útil entrenar en una variedad de experiencias.
Además del rendimiento mostrado anteriormente, hemos encontrado empíricamente que MGDT entrenado con una variedad de experiencias se desempeña mejor que MDGT entrenado solo con demostraciones de nivel experto o simplemente con la clonación de comportamientos de demostración.
Escala el tamaño del modelo para múltiples juegos para obtener un mejor rendimiento
Podría decirse que la escalabilidad se ha convertido en la principal fuerza impulsora detrás de muchos avances recientes en el aprendizaje automático y, por lo general, se logra aumentando la cantidad de parámetros en un modelo basado en transformadores. Nuestra observación con Multi-Game Decision Transformers es similar: el rendimiento aumenta de manera predecible con un tamaño de modelo más grande. En particular, su rendimiento no parece haber tocado techo todavía y, en comparación con otros sistemas de aprendizaje, las ganancias de rendimiento son más significativas a medida que aumenta el tamaño del modelo.
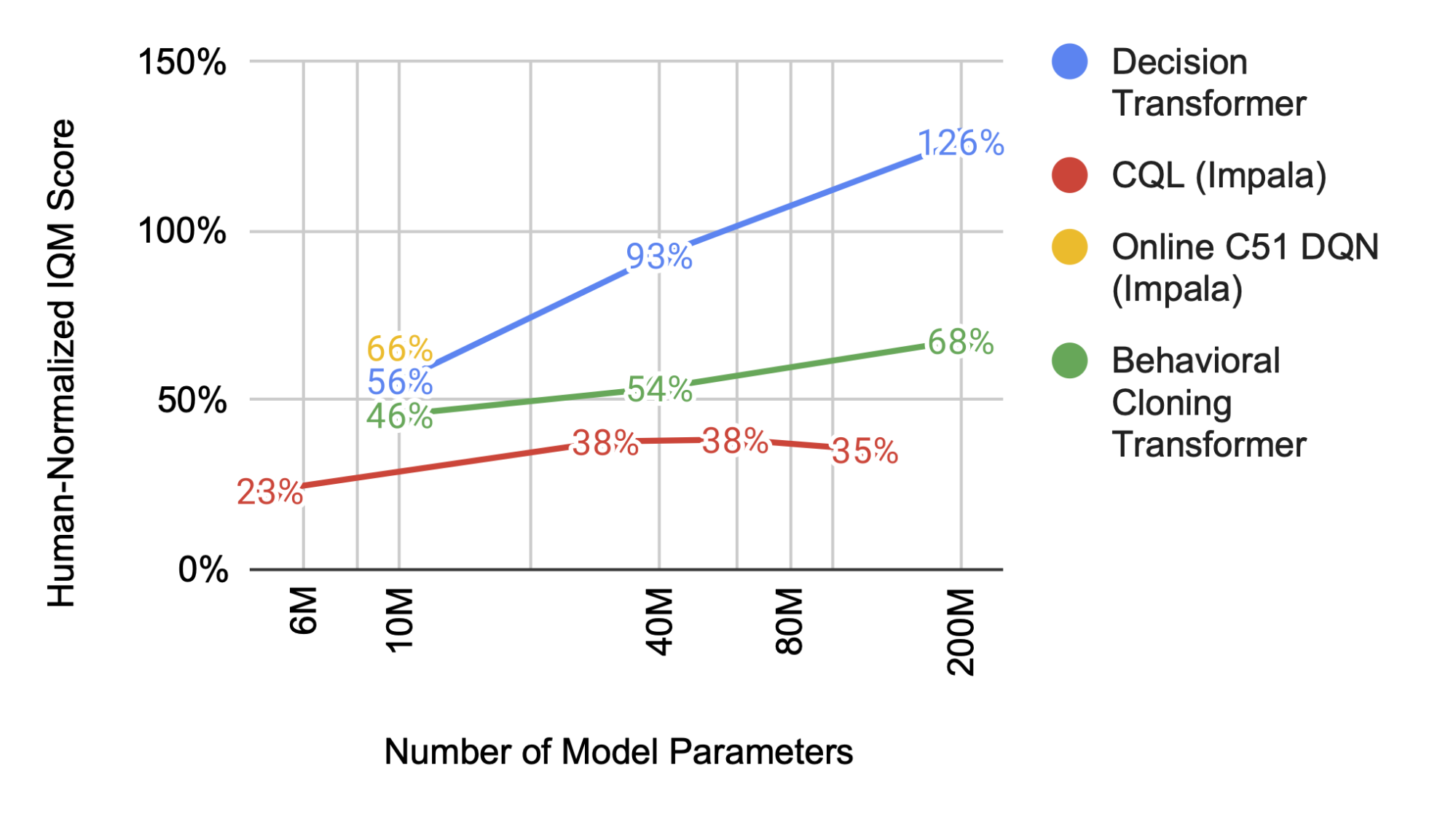 |
| El rendimiento de Multi-Game Decision Transformer (mostrado por la línea azul) aumenta de forma predecible con un tamaño de modelo más grande, mientras que otros modelos no lo hacen. |
Los transformadores de decisión multijuego preentrenados aprenden rápidamente
Otro beneficio de los MGDT es que pueden aprender a jugar un juego nuevo con muy pocas demostraciones de juego (no todas deben ser de nivel experto). En este sentido, los MGDT se pueden considerar como modelos preentrenados que se pueden ajustar rápidamente a pequeñas cantidades de nuevos datos de juego. En comparación con otros métodos populares de preentrenamiento, muestra claramente beneficios constantes para obtener puntajes más altos.
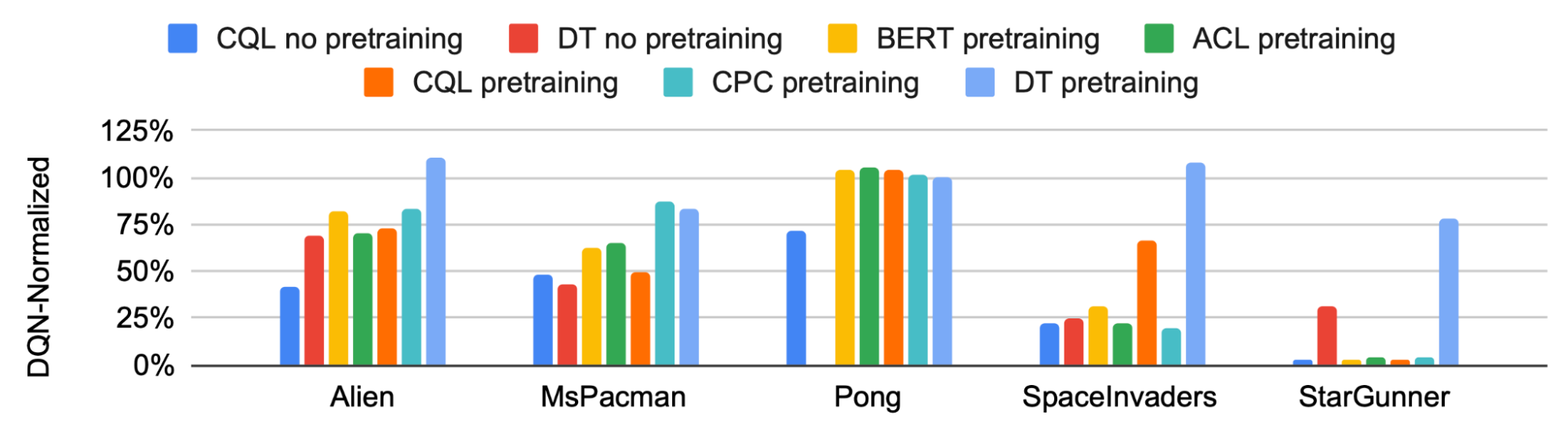 |
| El preentrenamiento del transformador de decisiones de juegos múltiples (el preentrenamiento DT, que se muestra en azul claro) muestra ventajas constantes sobre otros modelos comunes cuando se adapta a nuevas tareas. |
¿Hacia dónde mira el agente?
Además de la evaluación cuantitativa, es instructivo (y divertido) visualizar el comportamiento del agente. Al examinar las cabezas atencionales, encontramos que el modelo MGDT constantemente pone énfasis en su campo de visión en áreas de imágenes observadas que contienen entidades significativas del juego. Visualizamos la atención del modelo mientras predice la próxima acción para varios juegos y descubrimos que se preocupa constantemente por entidades como el avatar en pantalla del agente, el espacio libre del agente, los objetos que no son agentes y las características ambientales clave. Por ejemplo, en un entorno interactivo, tener un modelo mundial preciso requiere saber cómo y cuándo enfocarse en objetos conocidos (p. ej., obstáculos existentes actualmente) y anticipar y/o planificar futuras incógnitas (p. ej., espacio negativo). Esta asignación diferencial de atención a muchos componentes clave de cada entorno mejora en última instancia el rendimiento.
 |
| Aquí podemos ver cuánto peso le da el modelo a cada elemento clave de la escena del juego. El rojo más claro indica más énfasis en esta mancha de píxeles. |
El futuro de los agentes generalistas a gran escala
Este trabajo es un paso importante para demostrar la capacidad de entrenar agentes de propósito general en muchos entornos, encarnaciones y estilos de comportamiento. Hemos demostrado el beneficio de una mayor escala de potencia y el potencial de escalar aún más. Estos resultados parecen indicar una generalización similar a otros dominios como la visión y el lenguaje: esperamos explorar el gran potencial de escalar datos y aprender de diferentes experiencias.
Esperamos futuras investigaciones para desarrollar agentes poderosos para configuraciones de múltiples entornos y múltiples encarnaciones. Nuestros puntos de control de código y modelo estarán disponibles aquí pronto.
Gracias
Nos gustaría agradecer a todos los demás autores del artículo, incluidos Igor Mordatch, Ofir Nachum Menjiao Yang, Lisa Lee, Daniel Freeman, Sergio Guadarrama, Ian Fischer, Eric Jang y Henryk Michalewski.
[ad_2]