[ad_1]
Los modelos de visión por computadora se utilizan a diario para una variedad de tareas que van desde el reconocimiento de objetos hasta la reconstrucción de objetos en 3D basada en imágenes. Un tipo desafiante de problema de visión por computadora es el reconocimiento a nivel de instancia (ILR): dada una imagen de un objeto, la tarea es determinar no solo la categoría genérica de un objeto (por ejemplo, un arco), sino también la instancia específica del objeto. objeto objeto («Arc de Triomphe de l’Étoile, París, Francia»).
Hasta ahora, ILR se ha abordado con enfoques de aprendizaje profundo. En primer lugar, se recopiló una gran cantidad de imágenes. Luego, se entrenó un modelo de profundidad para incrustar cada imagen en un espacio de alta dimensión donde imágenes similares tienen representaciones similares. Finalmente, la representación se usó para realizar las tareas de ILR en términos de clasificación (por ejemplo, usando un clasificador plano entrenado sobre la incrustación) o recuperación (por ejemplo, usando una búsqueda de vecino más cercano en el espacio de incrustación) para resolver.
Dado que hay muchos dominios de objetos diferentes en el mundo, p. Por ejemplo, puntos de referencia, productos u obras de arte, capturarlos todos en un solo conjunto de datos y entrenar un modelo que pueda distinguirlos es una tarea bastante desafiante. Para reducir la complejidad del problema a un nivel manejable, el enfoque de la investigación hasta ahora ha sido resolver los ILR para un solo dominio a la vez. Para avanzar en la investigación en esta área, organizamos varios concursos de Kaggle centrados en el reconocimiento y la recuperación de imágenes históricas. En 2020, Amazon se unió al esfuerzo y avanzamos más allá del dominio pionero y nos expandimos a los dominios del arte y el reconocimiento de instancias de productos. El siguiente paso es generalizar la tarea ILR a múltiples dominios.
Es por eso que nos complace anunciar el Desafío de incrustación de imágenes universales de Google, organizado por Kaggle en asociación con Google Research y Google Lens. En este desafío, les pedimos a los participantes que creen un único modelo universal de incrustación de imágenes que pueda representar objetos de múltiples dominios a nivel de instancia. Creemos que esto es clave para las aplicaciones de búsqueda visual del mundo real, como B. expandir las exhibiciones culturales en un museo, organizar colecciones de fotografías, comercio visual y más.
 |
| fotos1 de instancias de objetos de algunos de los dominios representados en el conjunto de datos: ropa y accesorios, muebles y artículos para el hogar, juguetes, automóviles, puntos de referencia, vajillas, obras de arte e ilustraciones. |
Grados de variación en diferentes dominios
Para representar objetos de una gran cantidad de dominios, necesitamos un modelo para aprender muchas subtareas específicas del dominio (por ejemplo, filtrar diferentes tipos de ruido o enfocarse en un detalle específico), que es solo de una colección semántica y visualmente diversa de latas. Ser imágenes aprendidas. Tratar con cada grado de variación presenta un nuevo desafío tanto para la adquisición de imágenes como para el entrenamiento de modelos.
El primer tipo de variación se deriva del hecho de que mientras algunos dominios contienen objetos que son únicos en el mundo (monumentos, obras de arte, etc.), otros contienen objetos que pueden tener muchas copias (ropa, muebles, productos empaquetados, alimentos, etc). Dado que un punto de referencia siempre se coloca en el mismo lugar, el contexto ambiental puede ser útil para el reconocimiento. Por el contrario, un producto como un teléfono, incluso de un modelo y color en particular, puede tener millones de instancias físicas y, por lo tanto, aparecer en muchos contextos ambientales.
Otro desafío surge del hecho de que un solo objeto puede tener un aspecto diferente según el ángulo de visión, las condiciones de iluminación, la oclusión o las deformaciones (por ejemplo, un vestido que lleva una persona puede tener un aspecto muy diferente al de una percha). Para que un modelo aprenda la invariancia de todos estos modos visuales, todos deben capturarse de los datos de entrenamiento.
Además, las similitudes entre los objetos difieren entre dominios. Para que una representación sea significativa, por ejemplo, en el espacio del producto, debe poder distinguir detalles muy finos entre productos de aspecto similar de dos marcas diferentes. Sin embargo, en el ámbito de la comida, el mismo plato (por ejemplo, espaguetis a la boloñesa) cocinado por dos chefs puede parecer bastante diferente, pero la capacidad del modelo para distinguir los espaguetis a la boloñesa de otros platos puede ser suficiente para que el modelo sea útil. Además, un modelo de visión de alta calidad debe mapear representaciones similares a representaciones más similares visualmente de un plato.
| dominio | punto de referencia | vestir | ||||
| imagen |
.jpg)
|
.jpg)
|
||||
| nombre de instancia | edificio Empire State2 | Maillots de ciclismo con el logo de Android3 | ||||
| ¿Qué objetos físicos pertenecen a la clase de instancia? | Única autoridad en el mundo | Muchas instancias físicas; puede diferir en tamaño o patrón (por ejemplo, un chal estampado cortado de manera diferente) | ||||
| ¿Cuáles son las posibles vistas del objeto? | Variación de la apariencia solo en función de las condiciones de disparo (por ejemplo, iluminación o ángulo de visión); número limitado de vistas externas comunes; Posibilidad de muchas vistas interiores | apariencia maleable (por ejemplo, desgastada o no); número limitado de vistas comunes: frontal, posterior, lateral | ||||
| ¿Qué es el entorno y es útil para el reconocimiento? | El contexto circundante no varía mucho excepto los ciclos diarios y anuales; puede ser útil para comprobar el objeto de interés | El contexto ambiental puede cambiar dramáticamente debido a diferencias en el entorno, ropa o accesorios adicionales que oscurecen parcialmente la ropa de interés (por ejemplo, una chaqueta o bufanda). | ||||
| ¿Cuáles pueden ser casos complicados que no pertenecen a la clase de instancia? | Réplicas de puntos de referencia (por ejemplo, la Torre Eiffel en Las Vegas), recuerdos | Misma prenda hecha de diferente material o diferente color; partes visualmente muy similares con una pequeña característica distintiva (por ejemplo, un pequeño logotipo de marca); diferentes prendas usadas por el mismo modelo | ||||
| Variación entre dominios para puntos de referencia y ropa de ejemplo. |
Aprenda representaciones multidominio
Habiendo creado una colección de imágenes que cubren una variedad de dominios, el próximo desafío es entrenar un modelo único y universal. Algunas funciones y tareas, como Los datos como la representación de colores son útiles en muchas áreas, por lo que agregar datos de entrenamiento de cualquier área probablemente ayudará al modelo a mejorar su discriminación de colores. Otras funciones pueden ser más específicas para los dominios seleccionados, por lo que agregar más datos de entrenamiento de otros dominios puede degradar el rendimiento del modelo. Por ejemplo, mientras que para los gráficos 2D puede ser muy útil que el modelo aprenda a encontrar duplicados cercanos, esto puede degradar el rendimiento de la ropa, donde se deben detectar las instancias deformadas y ocluidas.
La gran variedad de posibles objetos de entrada y tareas a aprender requiere nuevos enfoques para la selección, enriquecimiento, limpieza y ponderación de los datos de entrenamiento. Es posible que se requieran nuevos enfoques para el entrenamiento y ajuste de modelos e incluso arquitecturas novedosas.
Desafío de incrustación de imágenes universales
Para motivar a la comunidad investigadora a asumir estos desafíos, estamos organizando el Desafío de incrustación de imágenes universales de Google. El desafío se lanzó en Kaggle en julio y se extenderá hasta octubre, con premios en efectivo por un total de $50,000. Se invitará a los equipos ganadores a presentar sus métodos en el Taller de detección de nivel de instancia en ECCV 2022.
Los participantes se evalúan frente a una tarea de recuperación en un conjunto de datos de aproximadamente 5000 imágenes de consulta de prueba y aproximadamente 200 000 imágenes de índice de las que se recuperan imágenes similares. A diferencia de ImageNet, que incluye etiquetas categóricas, las imágenes de este conjunto de datos están etiquetadas a nivel de instancia.
Los datos de evaluación del Desafío consisten en imágenes de las siguientes categorías: Ropa y accesorios, Productos empacados, Muebles y artículos para el hogar, Juguetes, Automóviles, Puntos de referencia, Escaparates, Vajilla, Obras de arte, Memes e Ilustraciones.
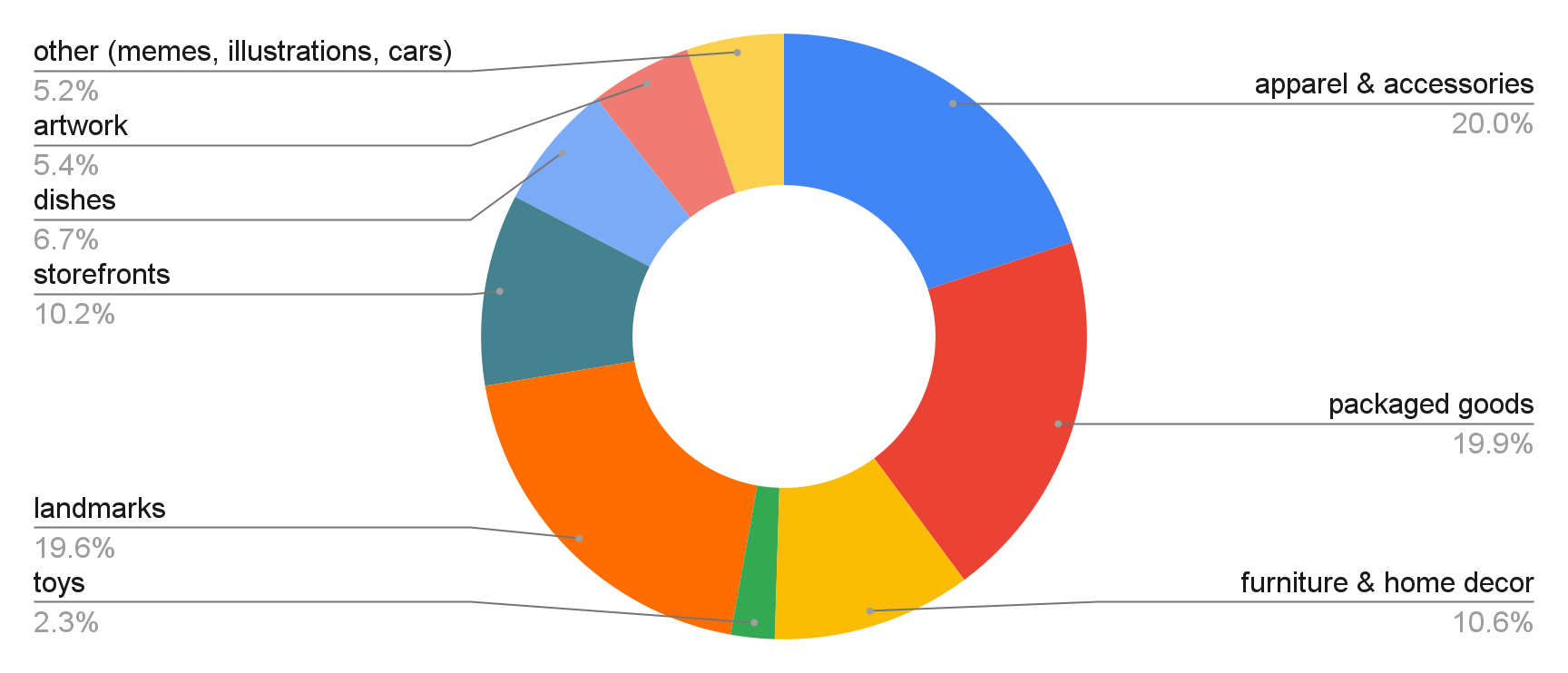 |
| Distribución de dominios a partir de imágenes de consulta. |
Invitamos a los investigadores y entusiastas del aprendizaje automático a participar en el Desafío de incrustación de imágenes universales de Google y a asistir al taller de Detección a nivel de instancia en ECCV 2022. Esperamos que el desafío y el taller promuevan las últimas técnicas para representar múltiples dominios.
conocimiento
Los principales colaboradores de este proyecto son Andre Araujo, Boris Bluntschli, Bingyi Cao, Kaifeng Chen, Mário Lipovský, Grzegorz Makosa, Mojtaba Seyedhosseini y Pelin Dogan Schönberger. Agradecemos a Sohier Dane, Will Cukierski y Maggie Demkin por su ayuda en la organización del Desafío Kaggle, así como a los coorganizadores de nuestro taller ECCV, Tobias Weyand, Bohyung Han, Shih-Fu Chang, Ondrej Chum, Torsten Sattler, Giorgos Tolias, Xu Zhang, Noa García, Guangxing Han, Pradeep Natarajan y Sanqiang Zhao. Además, agradecemos a Igor Bonaci, Tom Duerig, Vittorio Ferrari, Victor Gomes, Futang Peng y Howard Zhou por brindar comentarios, ideas y apoyo en varios puntos a lo largo de este proyecto.
1 Crédito de la foto: Chris Schrier, CC-BY; Petri Krohn, licencia de documentación libre GNU; Drazen Nesic, CC0; Marco Verch Fotógrafo Profesional, CCBY; Grendelkhan, CCBY; Bobby Mikul, CC0; Vincent van Gogh, CC0; pxhere.com, CC0; Casa inteligente perfeccionada, CC-BY. ↩
2 Crédito: Bobby Mikul, CC0. ↩
3 Crédito: Chris Schrier, CC-BY. ↩
[ad_2]