[ad_1]
Los videos son una fuente omnipresente de contenido multimedia que toca muchos aspectos de la vida diaria de las personas. Cada vez más, las aplicaciones de video del mundo real, como subtítulos de video, análisis de contenido de video y respuesta a preguntas de video (VideoQA), se basan en modelos que pueden combinar contenido de video con texto o lenguaje natural. Sin embargo, VideoQA es particularmente desafiante ya que requiere información semántica, como objetos en una escena, e información temporal, por ejemplo, cómo se mueven e interactúan las cosas, las cuales deben verse en el contexto de una pregunta de lenguaje natural que contiene una intención específica. . Además, dado que los videos tienen muchos cuadros, procesarlos para aprender información espacio-temporal puede ser computacionalmente intensivo. No obstante, comprender toda esta información permite que los modelos respondan preguntas complejas; por ejemplo, en el siguiente video, una pregunta sobre el segundo ingrediente que se vierte en el tazón requiere la identificación de objetos (los ingredientes), acciones (verter) y cronológico. Orden (Segundo). .
 |
| Una pregunta de entrada de ejemplo para la tarea VideoQA «¿Cuál es el segundo ingrediente que se vierte en el tazón?», que requiere una comprensión más profunda de las entradas tanto visuales como de texto. El video es un ejemplo del conjunto de datos 50 Salads, utilizado bajo la licencia Creative Commons. |
Para abordar esto, en Video Question Answering with Iterative Video-Text Co-Tokenization, presentamos un nuevo enfoque para el aprendizaje de video-texto, llamado Co-tokenización iterativa, que es capaz de fusionar eficientemente información espacial, temporal y lingüística para VideoQA. Este enfoque es un flujo múltiple en el que se procesan videos a diferentes escalas, cada uno con modelos de columna vertebral independientes, para producir presentaciones de video que capturan diferentes características, p. B. las de alta resolución espacial o de larga duración. Luego, el modelo aplica el motor de co-tokenización para aprender representaciones eficientes al fusionar las transmisiones de video con el texto. Este modelo es altamente eficiente, utiliza solo 67 Giga-FLOP (GFLOP), que es al menos un 50 % menos que los enfoques anteriores, al tiempo que ofrece un mejor rendimiento que los modelos alternativos de última generación.
Co-tokenización iterativa de video-texto
El objetivo principal del modelo es generar funciones tanto de video como de texto (es decir, la pregunta del usuario) y juntos permitir que sus respectivas entradas interactúen. Un segundo objetivo es hacer esto de manera eficiente, lo cual es muy importante para los videos, ya que contienen de decenas a cientos de fotogramas como entrada.
El modelo aprende a descomponer las entradas comunes de video-voz en un conjunto más pequeño de tokens que representan ambas modalidades juntas y de manera eficiente. Al tokenizar, usamos ambas modalidades para producir una representación compacta común, que se alimenta a una capa de transformador para producir la representación del siguiente nivel. Un desafío aquí, que también es típico del aprendizaje intermodal, es que el cuadro de video a menudo no se corresponde directamente con el texto que lo acompaña. Abordamos esto agregando dos niveles lineales de aprendizaje que unifican las dimensiones de las características visuales y de texto antes de la tokenización. De esta manera, permitimos que tanto el video como el texto determinen cómo se aprenden los tokens de video.
Además, un solo paso de tokenización no permite una mayor interacción entre las dos modalidades. Para hacer esto, usamos esta nueva representación de funciones para interactuar con las funciones de entrada de video y crear otro conjunto de funciones tokenizadas que luego se alimentan a la siguiente capa de Transformador. Este proceso iterativo permite la creación de nuevas características o tokens que representan un refinamiento continuo de la representación conjunta de ambas modalidades. En el paso final, las características se introducen en un decodificador que produce la salida de texto.
Como es habitual con VideoQA, entrenamos previamente el modelo antes de optimizarlo en cada conjunto de datos de VideoQA. En este trabajo, usamos los videos anotados automáticamente con texto basado en el reconocimiento de voz, usando el conjunto de datos HowTo100M en lugar de un entrenamiento previo en un gran conjunto de datos de VideoQA. Estos datos de preentrenamiento más débiles aún permiten que nuestro modelo aprenda funciones de teletexto.
 |
| Visualización del enfoque iterativo de co-tokenización de video-texto. Las entradas de video de transmisión múltiple que son versiones de la misma entrada de video (por ejemplo, un video de alta resolución y baja velocidad de cuadros y un video de baja resolución y alta velocidad de cuadros) se fusionan de manera eficiente con la entrada de texto para producir un Respuesta del decodificador basado en texto. En lugar de procesar las entradas directamente, el modelo iterativo de co-tokenización de video-texto aprende una cantidad reducida de tokens útiles de las entradas de video-voz fusionadas. Este proceso se realiza de forma iterativa, lo que permite que la tokenización de características actual influya en la selección de tokens en la siguiente iteración, refinando así la selección. |
Respuesta eficiente a preguntas en video
Aplicamos el algoritmo iterativo de co-tokenización de voz de video a tres puntos de referencia principales de VideoQA, MSRVTT-QA, MSVD-QA e IVQA, y mostramos que este enfoque logra mejores resultados que otros modelos de última generación a la vez que tiene un tamaño modesto. Además, el aprendizaje iterativo de co-tokenización da como resultado un ahorro computacional significativo para las tareas de aprendizaje de teletexto. El proceso consume solo 67 GigaFLOP (GFLOPS), que es una sexta parte de los 360 GFLOPS necesarios cuando se usa el popular modelo de video 3D ResNet junto con texto, y es más del doble de eficiente que el modelo X3D. Esto conduce a resultados altamente precisos que superan los métodos más modernos.
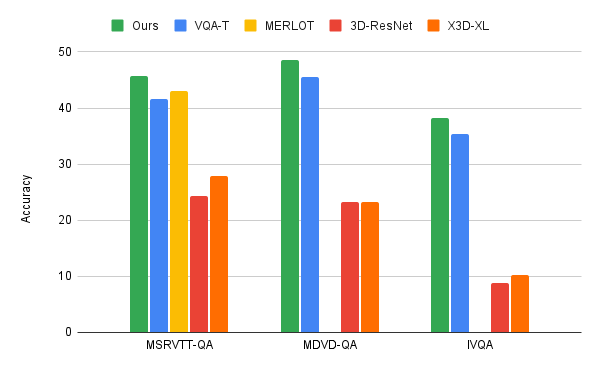 |
| Comparación de nuestro enfoque iterativo de co-tokenización con métodos anteriores como MERLOT y VQA-T y líneas de base con ResNet-3D o X3D-XL únicos. |
Entradas de video de transmisión múltiple
Para VideoQA o una variedad de otras tareas que involucran entradas de video, encontramos que la entrada de transmisión múltiple es importante para responder con mayor precisión a las preguntas sobre las relaciones espaciales y temporales. Nuestro enfoque utiliza tres secuencias de video con diferentes resoluciones y frecuencias de cuadro: una secuencia de video de entrada de baja resolución y alta frecuencia de cuadro (a 32 cuadros por segundo y con una resolución espacial de 64 x 64, a la que nos referimos como 32 x 64 x 64); un video de alta resolución y baja velocidad de cuadros (8x224x224); y uno intermedio (16x112x112). A pesar de la cantidad aparentemente mayor de información que se procesará con tres flujos, obtenemos modelos muy eficientes debido al enfoque iterativo de co-tokenización. Al mismo tiempo, estos flujos adicionales permiten extraer la información más relevante. Por ejemplo, como se muestra en la imagen a continuación, las preguntas sobre una actividad temporal específica dan como resultado activaciones más altas en la entrada de video de baja resolución pero alta velocidad de cuadros, mientras que las preguntas sobre la actividad general pueden responderse con la entrada de alta resolución en muy pocos cuadros. Otra ventaja de este algoritmo es que la tokenización cambia según las preguntas que se hagan.
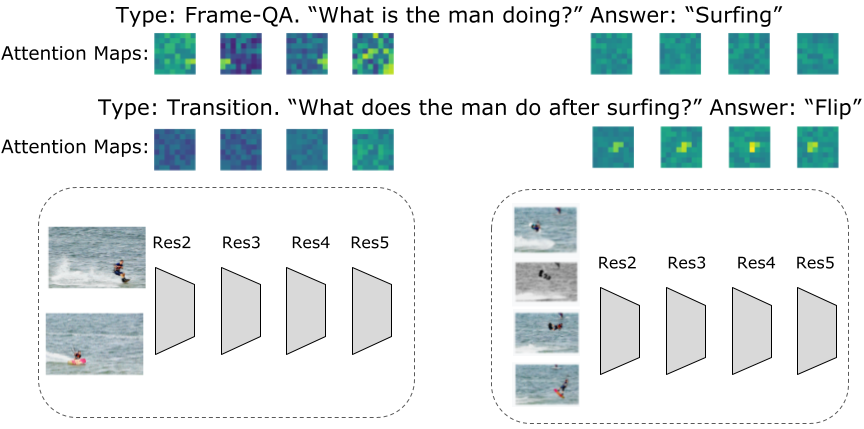 |
| Visualización de los mapas de atención aprendidos durante la co-tokenización de video-texto por turno. Las tarjetas de atención difieren según la pregunta que se haga para el mismo video. Por ejemplo, si la pregunta es sobre la actividad general (por ejemplo, navegar en la imagen de arriba), entonces los mapas de atención de las entradas de mayor resolución y menor velocidad de fotogramas son más activos y parecen dar cuenta de más información global. Por otro lado, si la pregunta es más específica, p. B. lo que sucede después de un evento, los mapas de funciones están más localizados y tienden a estar activos en la entrada de video de alta velocidad de cuadros. Además, vemos que las entradas de video de baja resolución y alta velocidad de cuadros brindan más información sobre la actividad en el video. |
Conclusión
Presentamos un nuevo enfoque para el aprendizaje de idiomas por video que se centra en el aprendizaje colaborativo a través de las modalidades de teletexto. Abordamos la importante y desafiante tarea de responder preguntas en video. Nuestro enfoque es altamente eficiente y preciso, superando los modelos actuales de última generación y siendo más eficiente. Nuestro enfoque da como resultado tamaños de modelo modestos y puede generar mejoras adicionales con modelos y datos más grandes. Esperamos que este trabajo provoque más investigación sobre el aprendizaje del lenguaje visual para permitir una interacción más fluida con los medios basados en la visión.
Gracias
Este trabajo está dirigido por AJ Pierviovanni, Kairo Morton, Weicheng Kuo, Michael Ryoo y Anelia Angelova. Agradecemos a nuestros colaboradores en esta investigación y a Soravit Changpinyo por sus valiosos comentarios y sugerencias, y a Claire Cui por sus sugerencias y apoyo. También agradecemos a Tom Small por las visualizaciones.
[ad_2]