
[ad_1]
En noviembre de 2021, en asociación con RStudio PBC, anunciamos la disponibilidad general de RStudio en Amazon SageMaker, el primer IDE de RStudio Workbench completamente administrado de la industria en la nube. Ahora puede traer su licencia actual de RStudio para migrar sus entornos de RStudio autoadministrados a Amazon SageMaker en solo unos pocos pasos.
RStudio es uno de los IDE más populares entre los desarrolladores de R para proyectos de aprendizaje automático (ML) y ciencia de datos. RStudio proporciona herramientas R de código abierto y software profesional de nivel empresarial para que los equipos de ciencia de datos desarrollen y compartan su trabajo en toda la organización. Cuando coloca RStudio sobre SageMaker, no solo obtiene acceso completamente administrado a la infraestructura de AWS, sino que también obtiene acceso nativo a SageMaker.
En esta publicación, examinamos cómo puede usar las funciones de SageMaker a través de RStudio en SageMaker para crear una canalización de SageMaker que compila, procesa, entrena y registra sus modelos R. También estamos explorando el uso de SageMaker para la implementación de nuestro modelo, todo con R.
descripción general de la solución
El siguiente diagrama muestra la arquitectura utilizada en nuestra solución. Todo el código usado en este ejemplo está en el repositorio de GitHub.
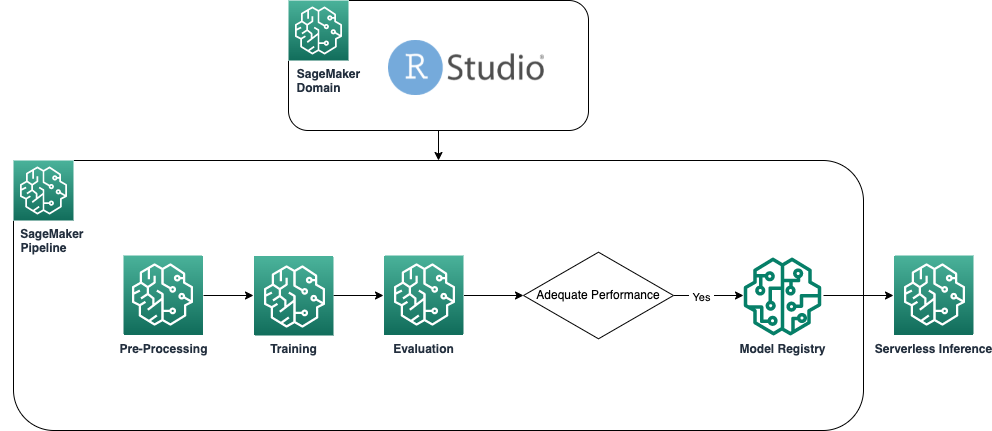
requisitos
Se requiere acceso a RStudio en SageMaker para seguir esta publicación. Si es nuevo en el uso de RStudio en SageMaker, consulte Primeros pasos con RStudio en Amazon SageMaker.
También necesitamos crear contenedores Docker personalizados. Utilizamos AWS CodeBuild para crear estos contenedores, por lo que necesitará algunos permisos adicionales de AWS Identity and Access Management (IAM) que es posible que no tenga de forma predeterminada. Antes de continuar, asegúrese de que el rol de IAM que está utilizando tenga una política de confianza con CodeBuild:
También se requieren los siguientes permisos en el rol de IAM para ejecutar una compilación en CodeBuild y enviar la imagen a Amazon Elastic Container Registry (Amazon ECR):
Cree contenedores R de referencia
Para usar nuestros scripts R para procesar y entrenar trabajos de procesamiento y entrenamiento de SageMaker, necesitamos crear nuestros propios contenedores Docker que contengan el tiempo de ejecución y los paquetes requeridos. La capacidad de usar su propio contenedor, que es parte de la oferta de SageMaker, brinda a los desarrolladores y científicos de datos una gran flexibilidad para usar las herramientas y los marcos de trabajo de su elección prácticamente sin restricciones.
Crearemos dos contenedores Docker habilitados para R: uno para procesar trabajos y otro para entrenar e implementar nuestros modelos. El procesamiento de datos generalmente requiere diferentes paquetes y bibliotecas que el modelado, por lo que aquí tiene sentido separar las dos fases y usar diferentes contenedores.
Para obtener más detalles sobre el uso de contenedores con SageMaker, consulte Uso de contenedores de Docker con SageMaker.
El contenedor utilizado para el procesamiento se define de la siguiente manera:
Para esta publicación usaremos un contenedor simple y relativamente liviano. Según sus necesidades o las necesidades de su organización, es posible que desee preinstalar varios paquetes R más.
El contenedor utilizado para el entrenamiento y la implementación se define de la siguiente manera:
El kernel de RStudio se ejecuta sobre un contenedor de Docker, por lo que no puede compilar e implementar los contenedores directamente en su sesión de Studio mediante los comandos de Docker. En su lugar, puede utilizar la muy útil biblioteca sagemaker-studio-image-build, que básicamente descarga la creación de contenedores en CodeBuild.
Creamos dos registros de Amazon ECR con los siguientes comandos: sagemaker-r-processing y sagemaker-r-train-n-deployy construimos los contenedores correspondientes que usaremos más adelante:
Construya la tubería
Con los contenedores creados y listos, podemos crear la canalización de SageMaker que orquestará el flujo de trabajo de creación de modelos. El código completo está debajo del archivo. pipeline.R en el depósito. La forma más fácil de crear una canalización de SageMaker es usar el SDK de SageMaker, una biblioteca de Python a la que podemos acceder a través del reticulado de la biblioteca. Esto nos da acceso a todas las funcionalidades de SageMaker sin salir de la configuración regional de R.
La tubería que construimos tiene los siguientes componentes:
- paso de preprocesamiento – Este es un trabajo de procesamiento de SageMaker (usando el
sagemaker-r-processingContainer) responsable de preprocesar los datos y dividirlos en conjuntos de datos de prueba y entrenamiento. - paso de entrenamiento – Este es un trabajo de entrenamiento de SageMaker (usando el
sagemaker-r-train-n-deployContainer) encargado de entrenar el modelo. En este ejemplo entrenamos un modelo lineal simple. - paso de evaluación – Este es un trabajo de procesamiento de SageMaker (usando el
sagemaker-r-processingContainer) encargado de realizar la evaluación del modelo. Específicamente en este ejemplo, estamos interesados en el RMSE (Root Mean Square Error) del conjunto de datos de prueba, que queremos usar en el siguiente paso y asignarlo al modelo en sí. - paso condicional – Este es un paso condicional nativo de las canalizaciones de SageMaker que nos permite bifurcar la lógica de la canalización en función de algunos parámetros. En este caso, la canalización se bifurca según el valor de RMSE calculado en el paso anterior.
- Registrar modelo paso – Si el paso condicional anterior es
True, y el rendimiento del modelo es aceptable, el modelo se registra en el registro de modelos. Para obtener más información, consulte Registro e implementación de modelos mediante el registro de modelos.
Primero llame a la función upsert para crear (o actualizar) la canalización y luego llame a la función de inicio para iniciar realmente la ejecución de la canalización:
Examinar la canalización y el registro del modelo.
Una de las mejores cosas de usar RStudio en SageMaker es que la plataforma SageMaker le permite usar la herramienta correcta para el trabajo correcto y cambiar rápidamente entre ellas según lo que necesite hacer.
Una vez que iniciamos la ejecución de la canalización, podemos cambiar a Amazon SageMaker Studio, que nos permite visualizar la canalización y monitorear las ejecuciones actuales y anteriores.
Para ver detalles sobre la canalización que acaba de crear y ejecutar, vaya a la interfaz del IDE de Studio, seleccione Recursos de SageMakerSeleccione tubería en el menú desplegable y seleccione la canalización (en este caso AbalonePipelineUsingR).
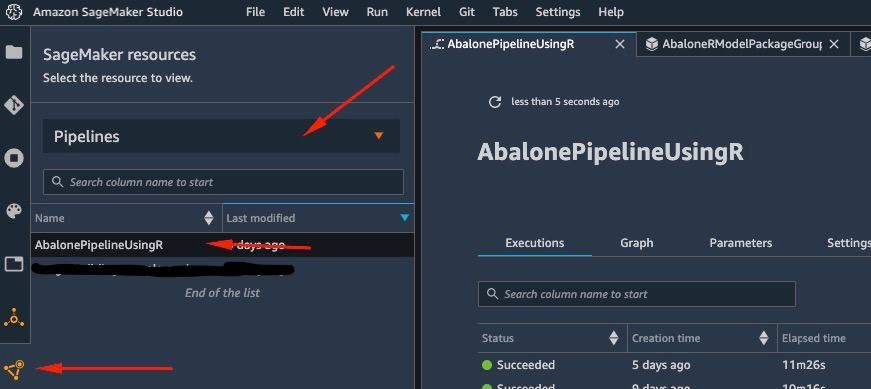
Esto muestra los detalles de la canalización, incluidas todas las ejecuciones actuales y anteriores. Seleccione el último para ver una representación visual de la tubería como se muestra en la captura de pantalla a continuación.
El servicio crea automáticamente el DAG de la canalización en función de las dependencias de datos entre los pasos, así como de las dependencias agregadas personalizadas (no se agregó ninguna en este ejemplo).
Si la ejecución tiene éxito, debería ver que todos los pasos se vuelven verdes.
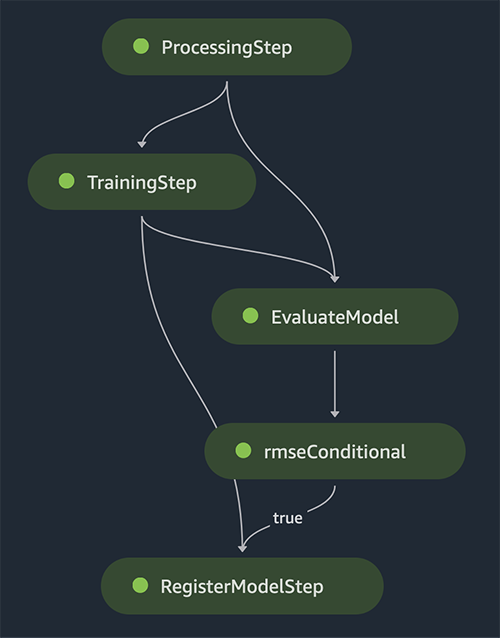
Al seleccionar cada paso, se muestran detalles sobre ese paso, incluidas entradas, salidas, registros y ajustes de configuración inicial. Esto le permite profundizar en la canalización y examinar cualquier paso fallido.
De manera similar, un modelo se almacena en el registro de modelos cuando la canalización termina de ejecutarse. Para acceder a él, en el Recursos de SageMaker Seleccionar área registro de modelo Haga clic en el menú desplegable y seleccione su modelo. Esto abrirá la lista de modelos registrados como se muestra en la siguiente captura de pantalla. Seleccione uno para abrir la página de detalles de esa versión de modelo específica.
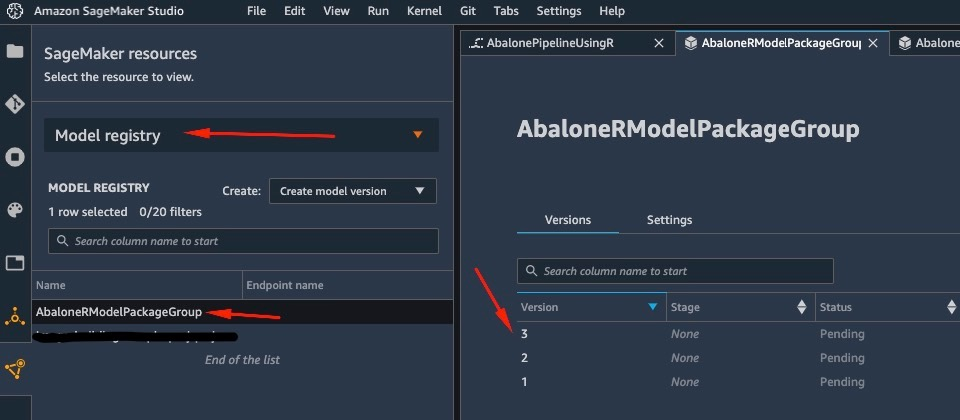
Después de abrir una versión del modelo, seleccione estado actualizado y Autorizar aprobar el modelo.
En este punto, según su caso de uso, puede configurar esta aprobación para desencadenar más acciones, incluida la implementación del modelo según sus requisitos.
Despliegue sin servidor del modelo
Una vez que haya entrenado y registrado un modelo en SageMaker, implementar el modelo en SageMaker es sencillo.
Hay varias formas de implementar un modelo, p. B. inferencia por lotes, puntos finales en tiempo real o puntos finales asincrónicos. Cada método tiene varias configuraciones requeridas, incluida la elección del tipo de instancia deseado y el mecanismo de escalado.
Para este ejemplo, usaremos la característica recientemente anunciada de SageMaker, Serverless Inference (en modo de vista previa en el momento de escribir este artículo) para implementar nuestro modelo R en un punto final sin servidor. Para este tipo de punto final, solo definimos la cantidad de RAM para asignar al modelo para la inferencia y la cantidad máxima de llamadas simultáneas al modelo permitidas. SageMaker se encarga de alojar el modelo y escalarlo automáticamente según sea necesario. Solo se le cobra por los segundos exactos y los datos utilizados por el modelo, sin cargos por tiempo de inactividad.
Puede implementar el modelo en un punto final sin servidor con el siguiente código:
Si ves el error ClientError: An error occurred (ValidationException) when calling the CreateModel operation: Invalid approval status "PendingManualApproval" El modelo que está intentando implementar no ha sido aprobado. Siga los pasos de la sección anterior para aprobar su modelo.
Llame al punto final realizando una solicitud al punto final HTTP que proporcionamos, o utilice el SDK de SageMaker en su lugar. En el siguiente código, llamamos al punto final para algunos datos de prueba:
El punto final al que llamamos era un punto final sin servidor y, como tal, se nos factura por la duración exacta y los datos utilizados. Puede notar que cuando llama por primera vez al terminal, tarda aproximadamente un segundo en responder. Esto se debe a la hora de inicio en frío del extremo sin servidor. Si realiza otra llamada poco después, el modelo devolverá la predicción en tiempo real porque ya está caliente.
Cuando haya terminado de experimentar con el punto final, puede eliminarlo con el siguiente comando:
Conclusión
En esta publicación, recorrimos el proceso de creación de una canalización de SageMaker con R en nuestro entorno de RStudio y mostramos cómo implementar nuestro modelo de R en un extremo sin servidor en SageMaker con el registro del modelo de SageMaker.
Con la combinación de RStudio y SageMaker, ahora puede crear y orquestar flujos de trabajo de ML completos e integrales en AWS utilizando nuestro lenguaje R preferido.
Para profundizar más en esta solución, le recomiendo que consulte el código fuente de esta solución, así como otros ejemplos en GitHub.
Sobre el Autor
 Georgios Schinas es Arquitecto de Soluciones Especializado en IA/ML en la región EMEA. Tiene su sede en Londres y trabaja en estrecha colaboración con clientes en el Reino Unido e Irlanda. Georgios ayuda a los clientes a desarrollar e implementar aplicaciones de aprendizaje automático en producción en AWS con un interés particular en las prácticas de MLOps, lo que permite a los clientes realizar aprendizaje automático a escala. En su tiempo libre le gusta viajar, cocinar y pasar tiempo con amigos y familiares.
Georgios Schinas es Arquitecto de Soluciones Especializado en IA/ML en la región EMEA. Tiene su sede en Londres y trabaja en estrecha colaboración con clientes en el Reino Unido e Irlanda. Georgios ayuda a los clientes a desarrollar e implementar aplicaciones de aprendizaje automático en producción en AWS con un interés particular en las prácticas de MLOps, lo que permite a los clientes realizar aprendizaje automático a escala. En su tiempo libre le gusta viajar, cocinar y pasar tiempo con amigos y familiares.
[ad_2]