[ad_1]
En los últimos años, hemos visto avances significativos en la aplicación del aprendizaje automático a la robótica. Sin embargo, los sistemas robóticos de hoy en día solo pueden ejecutar comandos muy cortos y codificados como «recoger una manzana» porque tienden a funcionar mejor con tareas y recompensas claras. Les cuesta aprender tareas a largo plazo y pensar en objetivos abstractos, como B. Un mensaje de usuario como «Acabo de hacer ejercicio, ¿puedes traerme un refrigerio saludable?»
Mientras tanto, los avances recientes en el entrenamiento del modelo de lenguaje (LM) han dado como resultado sistemas que pueden realizar una variedad de tareas de comprensión y generación de lenguaje con resultados impresionantes. Sin embargo, estos modelos de lenguaje no están anclados en el mundo físico debido a la naturaleza de su proceso de formación: un modelo de lenguaje generalmente no interactúa con su entorno ni observa el resultado de sus respuestas. Esto puede dar lugar a que se generen instrucciones que pueden ser ilógicas, poco prácticas o inseguras para un robot en un contexto físico. Por ejemplo, cuando se le pregunta: «Derramé mi bebida, ¿puede ayudarme?», el modelo de lenguaje GPT-3 responde: «Podría intentar usar una aspiradora», una sugerencia que puede ser insegura o imposible de hacer para el robot. Si le hace la misma pregunta al modelo de lenguaje FLAN, se disculpa por el derrame con «Lo siento, no quise revelarlo», lo cual no es una respuesta muy útil. Entonces nos preguntamos, ¿existe una forma efectiva de combinar modelos de lenguaje avanzado con algoritmos de aprendizaje robótico para aprovechar ambos?
En Do As I Can, Not As I Say: Grounding Language in Robotic Affordances, presentamos un enfoque novedoso, desarrollado en colaboración con Everyday Robots, que utiliza el conocimiento avanzado del modelo de lenguaje para permitir que un agente físico como un robot obedezca textos de alto nivel. instrucciones para tareas basadas en la física, mientras que el modelo de lenguaje se basa en tareas que son factibles en un contexto específico del mundo real. Evaluamos nuestro método, al que llamamos PaLM-SayCan, colocando robots en un entorno de cocina real y asignándoles tareas de lenguaje natural. Observamos resultados altamente interpretables para tareas complejas y abstractas de duración prolongada, como «Acabo de hacer ejercicio, por favor tráeme un refrigerio y una bebida para recuperarme». el modelo de lenguaje es defectuoso casi a la mitad en comparación con las líneas de base sin conexión a tierra. También nos complace publicar una configuración de simulación de robot donde la comunidad de investigación puede probar este enfoque.
| En PaLM-SayCan, el robot actúa como las «manos y los ojos» del modelo de lenguaje, mientras que el modelo de lenguaje proporciona conocimiento semántico de alto nivel sobre la tarea. |
Un diálogo entre usuario y robot, facilitado por el modelo de lenguaje
Nuestro enfoque utiliza el conocimiento contenido en modelos de lenguaje (Say) para determinar y evaluar acciones útiles para instrucciones de alto nivel. También utiliza una función de suministro (Can) que permite la conexión a tierra en el mundo real y determina qué acciones se pueden realizar en un entorno determinado. Usando el modelo de lenguaje PaLM, lo llamamos PaLM-SayCan.
 |
| Nuestro enfoque selecciona habilidades en función de lo que el modelo lingüístico evalúa como útil para la enseñanza de alto nivel y lo que el modelo de oferta evalúa como posible. |
Nuestro sistema puede verse como un diálogo entre el usuario y el robot facilitado por el modelo de lenguaje. El usuario comienza dando una instrucción de que el modelo de lenguaje se convierte en una secuencia de pasos para que el robot los lleve a cabo. Esta secuencia se filtra usando las capacidades del robot para determinar el plan más factible dado su estado y entorno actual. El modelo determina la probabilidad de que una determinada habilidad progrese con éxito para completar la instrucción multiplicando dos probabilidades: (1) puesta a tierra de tareas (es decir, una descripción del idioma de la habilidad) y (2) puesta a tierra mundial (es decir, viabilidad de la habilidad en el estado actual).
Hay otras ventajas de nuestro enfoque en términos de su seguridad e interpretabilidad. En primer lugar, al permitir que el LM evalúe diferentes opciones en lugar de generar el resultado más probable, restringimos de manera efectiva el LM para generar solo una de las respuestas preseleccionadas. Además, el usuario puede comprender fácilmente el proceso de toma de decisiones al observar el idioma por separado y las calificaciones de asequibilidad en lugar de un solo problema.
| PaLM-SayCan también es interpretable: en cada paso podemos ver las principales opciones que considera en función de su puntaje de idioma (azul), puntaje de accesibilidad (rojo) y puntaje combinado (verde). |
Directrices de formación y funciones de valor
Cada habilidad en el conjunto de habilidades del agente se define como una guía con una breve descripción de lenguaje (por ejemplo, «Levanta la lata») representada como inserciones y una función de oferta que representa la probabilidad de completar la habilidad desde el estado actual del robot. Para aprender las funciones de disponibilidad, usamos funciones de recompensa dispersas establecidas en 1.0 para una ejecución exitosa y 0.0 en caso contrario.
Utilizamos la clonación de comportamiento (BC) basada en imágenes para entrenar las políticas relacionadas con el lenguaje y el aprendizaje por refuerzo (RL) basado en diferencias temporales (TD) para entrenar las funciones de valor. Para entrenar las pautas, recopilamos datos de 68 000 demostraciones realizadas por 10 robots durante 11 meses y agregamos 12 000 episodios exitosos filtrados de un conjunto de episodios autónomos de pautas aprendidas. Luego aprendimos las funciones de valor condicionado por el lenguaje usando MT-Opt en el simulador de Everyday Robots. El simulador complementa nuestra flota de robots reales con una versión simulada de las habilidades y el entorno transformado con RetinaGAN para reducir la brecha entre la simulación y la realidad. Impulsamos el rendimiento de las políticas de simulación utilizando demostraciones para lograr los éxitos iniciales y luego mejoramos continuamente el rendimiento de RL a través de la recopilación de datos en línea en la simulación.
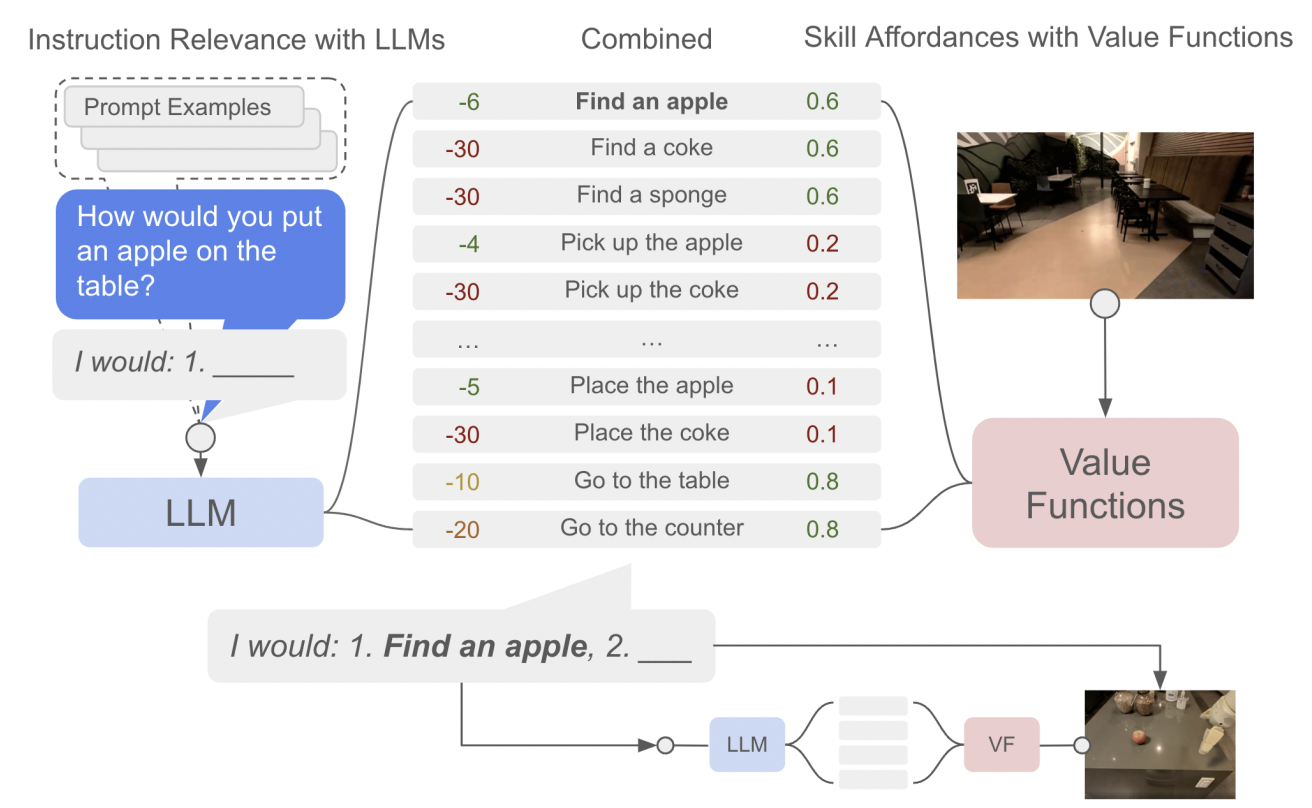 |
| Dada una instrucción de alto nivel, nuestro enfoque combina las probabilidades del modelo de lenguaje con las probabilidades de la función de valor (VF) para elegir la próxima habilidad a ejecutar. Este proceso se repite hasta que la instrucción principal se completa correctamente. |
Desempeño en instrucciones abstractas, complejas y extendidas temporalmente
Para probar nuestro enfoque, usamos robots de Everyday Robots combinados con PaLM. Colocamos los robots en un entorno de cocina de objetos compartidos y los evaluamos con 101 instrucciones para probar su rendimiento en diferentes estados del entorno y del robot, la complejidad del lenguaje de instrucción y el horizonte temporal. Estas instrucciones están diseñadas específicamente para demostrar la ambigüedad y la complejidad del lenguaje, en lugar de hacer preguntas simples y convincentes que permitan preguntas como «Acabo de hacer ejercicio, ¿cómo me darías un refrigerio y una bebida para recuperarme?». en lugar de «¿Puedes traerme agua y una manzana?»
Usamos dos métricas para evaluar el desempeño del sistema: (1) el tasa de éxito del planindicando si el robot seleccionó las habilidades correctas para la instrucción, y (2) el Tasa de éxito de ejecución, que indica si la instrucción se ejecutó correctamente. Comparamos dos modelos de lenguaje, PaLM y FLAN (un modelo de lenguaje más pequeño ajustado para responder instrucciones) con y sin asequibilidad y las políticas subyacentes, que se realizan directamente con lenguaje natural (clonación de comportamiento en la tabla a continuación). Los resultados muestran que el sistema que utiliza PaLM con Affordance Grounding (PaLM-SayCan) selecciona la secuencia correcta de habilidades el 84 % de las veces y las ejecuta con éxito el 74 % de las veces, lo que reduce los errores en un 50 % en comparación con FLAN y se reduce. en comparación con PaLM sin conexión a tierra del robot. Esto es particularmente emocionante porque por primera vez podemos ver cómo una mejora en los modelos de lenguaje conduce a una mejora similar en la robótica. Este resultado apunta a un futuro potencial en el que la robótica puede aprovechar la ola de avances que hemos observado en los modelos de lenguaje y acercar estos subcampos de investigación.
| algoritmo | Planificar | Realizar | ||
| Palma SayCan | 84% | 74% | ||
| palmera | 67% | – | ||
| PIE SayCan | 70% | 61% | ||
| PASTEL | 38% | – | ||
| clonación conductual | 0% | 0% |
| PaLM-SayCan reduce a la mitad los errores en comparación con PaLM sin ofertas y en comparación con FLAN en 101 tareas. |
| En combinación con PaLM, SayCan mostró una planificación exitosa para el 84 % de las 101 instrucciones de prueba. |
Si desea obtener más información sobre este proyecto de los propios investigadores, mire el video a continuación:
Conclusión y trabajo futuro
Estamos entusiasmados con los avances que hemos visto con PaLM-SayCan, un enfoque general e interpretable para usar el conocimiento de los modelos de lenguaje que permite que un robot siga instrucciones de texto de alto nivel para realizar tareas físicas. Nuestros experimentos en una variedad de tareas de robots reales demuestran la capacidad de planificar y completar instrucciones de lenguaje natural abstractas a largo plazo con una alta tasa de éxito. Creemos que la interpretabilidad de PaLM-SayCan permite una interacción segura del usuario en el mundo real con los robots. A medida que exploramos direcciones futuras para este trabajo, esperamos obtener una mejor comprensión de cómo la información recopilada de la experiencia del mundo real del robot podría usarse para mejorar el modelo de lenguaje, y en qué medida el lenguaje natural proporciona la ontología correcta para programar robots. . Tenemos una configuración de simulación de robot de código abierto que esperamos proporcione a los investigadores un recurso valioso para futuras investigaciones que combinen el aprendizaje de robots con modelos de lenguaje avanzado. La comunidad de investigación puede visitar la página y el sitio web de GitHub del proyecto para obtener más información.
Gracias
Agradecemos a nuestros coautores Michael Ahn, Anthony Brohan, Noah Brown, Yevgen Chebotar, Omar Cortes, Byron David, Chelsea Finn, Kelly Fu, Keerthana Gopalakrishnan, Alex Herzog, Daniel Ho, Jasmine Hsu, Julian Ibarz, Alex Irpan, Eric Jang , Rosario Jauregui Ruano, Kyle Jeffrey, Sally Jesmonth, Nikhil J. Joshi, Ryan Julian, Dmitry Kalashnikov, Yuheng Kuang, Kuang-Huei Lee, Sergey Levine, Yao Lu, Linda Luu, Carolina Parada, Peter Pastor, Jornell Quiambao, Kanishka Rao , Jarek Rettinghouse, Diego Reyes, Pierre Sermanet, Nicolas Sievers, Clayton Tan, Alexander Toshev, Vincent Vanhoucke, Fei Xia, Ted Xiao, Peng Xu, Sichun Xu, Mengyuan Yan y Andy Zeng. También nos gustaría agradecer a Yunfei Bai, Matt Bennice, Maarten Bosma, Justin Boyd, Bill Byrne, Kendra Byrne, Noah Constant, Pete Florence, Laura Graesser, Rico Jonschkowski, Daniel Kappler, Hugo Larochelle, Benjamin Lee, Adrian Li, Suraj Nair , Krista Reymann, Jeff Seto, Dhruv Shah, Ian Storz, Razvan Surdulescu y Vincent Zhao por su ayuda y apoyo en varios aspectos del proyecto. Y nos gustaría agradecer a Tom Small por crear muchas de las animaciones en esta publicación.
[ad_2]