[ad_1]
Un aspecto importante de la visión humana es nuestra capacidad para comprender formas 3D a partir de las imágenes 2D que observamos. Lograr este tipo de entendimiento utilizando sistemas de visión artificial ha sido un desafío fundamental en el campo. Muchos enfoques exitosos se basan en vista múltiple Datos en los que dos o más imágenes de la misma escena están disponibles desde diferentes perspectivas, lo que facilita mucho la inferencia de la forma 3D de los objetos en las imágenes.
Sin embargo, hay muchas situaciones en las que sería útil conocer la estructura 3D a partir de una sola imagen, pero este problema es generalmente difícil o imposible de resolver. Por ejemplo, no es necesariamente posible notar la diferencia entre una imagen de una Por supuesto Playa y una imagen de un cartel plano de la misma playa. Sin embargo, es posible estimar la estructura 3D en función de qué tipo de objetos 3D son comunes y cómo se ven estructuras similares desde diferentes perspectivas.
En «LOLNeRF: Learn from One Look» presentado en CVPR 2022, proponemos un marco que aprende a modelar la estructura y apariencia 3D de colecciones de vista única Fotos. LOLNeRF solo aprende la estructura 3D típica de una clase de objetos, como automóviles, rostros humanos o gatos vistas individuales de un objeto, nunca el mismo objeto dos veces. Construimos nuestro enfoque combinando Optimización latente generativa (Glándula campos de radiación neural (NeRF) para lograr resultados de vanguardia para la síntesis de vistas novedosas y resultados competitivos para la estimación de profundidad.
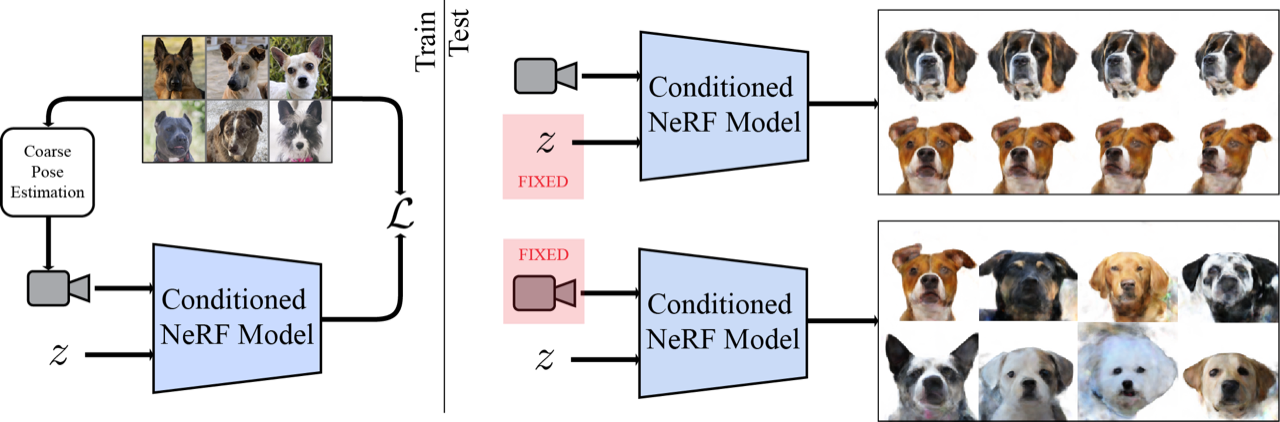 |
| Aprendemos un modelo de objetos 3D mediante la reconstrucción de una gran colección de imágenes de vista única utilizando una red neuronal condicionada en vectores latentes. p.ej (Izquierda). Esto permite sacar un modelo 3D de la imagen y renderizarlo desde nuevos ángulos. Sosteniendo la cámara, podemos interpolar o muestrear nuevas identidades (A la derecha). |
Combinación de GLO y NeRF
GLO es un método general que aprende a reconstruir un conjunto de datos (por ejemplo, un conjunto de imágenes 2D) mediante el aprendizaje de una red neuronal (decodificador) y una tabla de códigos (latentes), que también es una entrada para los decodificadores. Cada uno de estos códigos latentes recrea un solo elemento (como una imagen) del conjunto de datos. Debido a que los códigos latentes tienen menos dimensiones que los propios elementos de datos, la red se ve obligada a hacerlo. generalizarAprenda una estructura común en los datos (por ejemplo, la forma general de los hocicos de los perros).
NeRF es una técnica que puede reconstruir muy bien un objeto 3D estático a partir de imágenes 2D. Representa un objeto con una red neuronal que genera color y densidad para cada punto en el espacio 3D. Los valores de color y densidad se acumulan a lo largo de los rayos, un rayo por cada píxel en una imagen 2D. Luego, estos se combinan utilizando la representación de volumen de gráficos por computadora estándar para calcular un color de píxel final. Es importante destacar que todas estas operaciones son diferenciables, lo que permite una supervisión de extremo a extremo. Al obligar a cada píxel renderizado (de la representación 3D) a que coincida con el color de los píxeles reales (2D), la red neuronal crea una representación 3D que se puede renderizar desde cualquier punto de vista.
Combinamos NeRF con GLO asignando a cada objeto un código latente y concatenándolo con entradas NeRF estándar para darle la capacidad de reconstruir varios objetos. Después de GLO, optimizamos estos códigos latentes junto con los pesos de la red durante el entrenamiento para reconstruir las imágenes de entrada. A diferencia de NeRF estándar, que requiere múltiples vistas del mismo objeto, solo monitoreamos nuestro método con vistas individuales cualquier objeto (pero varios ejemplos de este tipo de objeto). Dado que NeRF es inherentemente 3D, podemos renderizar el objeto desde cualquier ángulo. La combinación de NeRF con GLO le da la oportunidad de aprender estructuras 3D comunes a través de instancias solo desde vistas individuales mientras conserva la capacidad de recrear instancias específicas del registro.
estimación de la cámara
Para que NeRF funcione, necesita conocer la posición exacta de la cámara en relación con el objeto de cada imagen. A menos que esto se haya medido cuando se tomó la fotografía, generalmente se desconoce. En su lugar, usamos MediaPipe Face Mesh para extraer cinco puntos de referencia de las imágenes. Cada una de estas predicciones 2D corresponde a un punto semánticamente consistente en el objeto (por ejemplo, la punta de la nariz o las esquinas de los ojos). Luego, podemos derivar un conjunto de ubicaciones canónicas 3D para los puntos semánticos junto con estimaciones de las poses de la cámara para cada imagen, de modo que la proyección de los puntos canónicos en las imágenes sea lo más consistente posible con los puntos de referencia 2D.
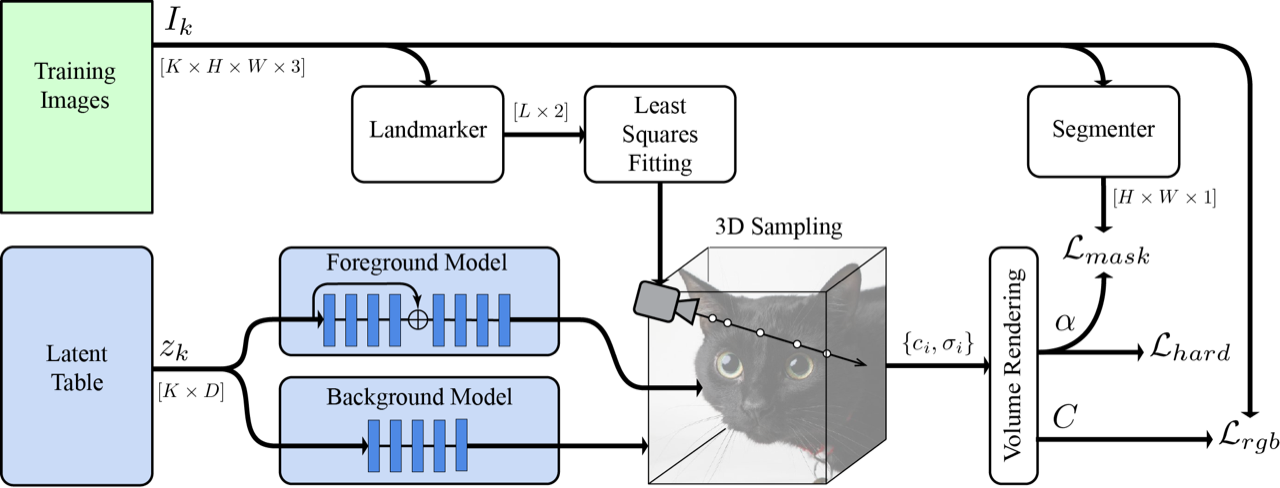 |
| Entrenamos una tabla por imagen de códigos latentes junto con un modelo NeRF. La salida está sujeta a pérdidas de dureza, máscara y RGB por rayo. Las cámaras se derivan de un ajuste de puntos de referencia predichos a puntos clave 3D canónicos. |
Pérdidas de máscara y superficie dura
NeRF estándar es eficaz para reproducir con precisión las imágenes, pero en nuestro caso de vista única, tiende a producir imágenes que se ven borrosas cuando se ven fuera del eje. Para ello, presentamos una novela superficie dura Pérdida que favorece la densidad para asumir transiciones bruscas de las zonas exteriores a las interiores, reduciendo el desenfoque. Básicamente, esto le dice a la red que cree superficies «sólidas» y no semitransparentes como las nubes.
También obtuvimos mejores resultados al dividir la red en redes separadas de primer plano y de fondo. Supervisamos esta división con una máscara de MediaPipe Selfie Segmenter y una pérdida para fomentar la especialización de la red. Esto permite que la red de primer plano se especialice solo en el objeto de interés y no se «distraiga» con el fondo, aumentando su calidad.
Resultados
Sorprendentemente, descubrimos que ajustar solo cinco puntos clave brinda estimaciones de cámara lo suficientemente precisas para entrenar un modelo para gatos, perros o rostros humanos. Esto significa que puede crear una nueva imagen desde cualquier otro ángulo desde una sola vista de sus amados gatos, Schnitzel, Widget y compañía.
 |
| arriba: Muestra de imágenes de gatos de AFHQ. abajo: una síntesis de nuevas vistas 3D creadas por LOLNeRF. |
Conclusión
Hemos desarrollado una técnica que es eficaz para reconocer estructuras 3D a partir de imágenes 2D individuales. Vemos un gran potencial en LOLNeRF para una variedad de aplicaciones y actualmente estamos investigando posibles casos de uso.
 |
| Interpolación de identidades de gatos a partir de la interpolación lineal de códigos latentes aprendidos para varios ejemplos en AFHQ. |
liberación de código
Reconocemos el potencial de abuso y la importancia de actuar con responsabilidad. Con este fin, solo publicaremos el código con fines de reproducibilidad, pero no publicaremos modelos generativos entrenados.
Gracias
Nos gustaría agradecer a Andrea Tagliasacchi, Kwang Moo Yi, Viral Carpenter, David Fleet, Danica Matthews, Florian Schroff, Hartwig Adam y Dmitry Lagun por su continua ayuda en la construcción de esta tecnología.
[ad_2]