
[ad_1]
Amazon SageMaker proporciona un conjunto de algoritmos integrados, modelos preentrenados y plantillas de soluciones preempaquetadas para facilitar que los científicos de datos y los profesionales del aprendizaje automático (ML) comiencen a entrenar e implementar modelos de ML. Estos algoritmos y modelos se pueden utilizar tanto para el aprendizaje supervisado como para el no supervisado. Puede procesar diferentes tipos de datos de entrada, incluidas tablas, imágenes y texto.
La rotación de clientes es un problema al que se enfrentan muchas empresas, desde las telecomunicaciones hasta la banca, donde los clientes suelen perderse frente a los competidores. Lo mejor para una empresa es retener a los clientes existentes en lugar de adquirir nuevos, ya que generalmente cuesta significativamente más adquirir nuevos clientes. Los operadores de telefonía celular tienen registros históricos de clientes que continúan utilizando el servicio o, en última instancia, abandonan el servicio. Podemos usar esta información histórica sobre la rotación de un operador móvil para entrenar un modelo ML. Después de entrenar este modelo, podemos pasar la información de perfil de cualquier cliente (la misma información de perfil que usamos para entrenar el modelo) al modelo y hacer que prediga si ese cliente abandonará o no.
En esta publicación, entrenamos e implementamos cuatro algoritmos de SageMaker lanzados recientemente (LightGBM, CatBoost, TabTransformer y AutoGluon-Tabular) en un conjunto de datos de predicción de rotación. Usamos SageMaker Automatic Model Tuning (una herramienta de ajuste de hiperparámetros) para encontrar los mejores hiperparámetros para cada modelo y comparar su rendimiento con un conjunto de datos de prueba de reserva para seleccionar el óptimo.
También puede usar esta solución como plantilla para buscar una colección de algoritmos tabulares de última generación y usar la optimización de hiperparámetros para encontrar el mejor modelo general. Puede reemplazar fácilmente el conjunto de datos de muestra con el suyo propio para resolver problemas comerciales reales que le interesen. Si desea pasar directamente al código SDK de SageMaker que analizamos en esta publicación, puede consultar el cuaderno de Jupyter de muestra a continuación.
Beneficios de los algoritmos integrados en SageMaker
Al elegir un algoritmo para su tipo específico de problema y datos, usar un algoritmo integrado en SageMaker es la opción más fácil, ya que ofrece los siguientes beneficios clave:
- Codificación baja – Los algoritmos incorporados requieren poca codificación para ejecutar experimentos. Las únicas entradas que debe proporcionar son los datos, los hiperparámetros y los recursos computacionales. Esto le permite ejecutar experimentos más rápido, con menos gastos generales para el seguimiento de los resultados y los cambios de código.
- Implementaciones de algoritmos eficientes y escalables – Los algoritmos incorporados vienen con paralelización en múltiples instancias de cómputo y compatibilidad con GPU para todos los algoritmos aplicables. Si tiene muchos datos para entrenar su modelo, la mayoría de los algoritmos integrados se pueden escalar fácilmente para satisfacer la demanda. Incluso si ya tiene un modelo entrenado previamente, podría ser más fácil usar su equivalente lógico en SageMaker y completar los hiperparámetros que ya conoce, en lugar de migrarlo y escribir un script de entrenamiento usted mismo.
- transparencia – Eres el propietario de los artefactos del modelo resultante. Puede tomar este modelo e implementarlo en SageMaker para varios patrones de inferencia diferentes (vea todos los tipos de implementación disponibles) y fácil escalado y administración de terminales, o puede implementarlo donde lo necesite.
Visualización y preprocesamiento de datos
Primero, recopilamos nuestro conjunto de datos de abandono de clientes. Es un conjunto de datos relativamente pequeño de 5000 registros, y cada registro utiliza 21 atributos para describir el perfil de un cliente de un proveedor de servicios inalámbricos estadounidense desconocido. Los atributos van desde el estado de EE. UU. donde reside el cliente hasta la cantidad de llamadas que ha realizado al servicio de atención al cliente y cuánto se le factura por las llamadas diarias. Estamos tratando de predecir si el cliente abandonará o no, lo cual es un problema de clasificación binaria. A continuación se muestra un subconjunto de estas funciones, etiquetadas como la última columna.

A continuación se presentan algunas ideas para cada columna, específicamente las estadísticas de resumen y el histograma de las características seleccionadas.
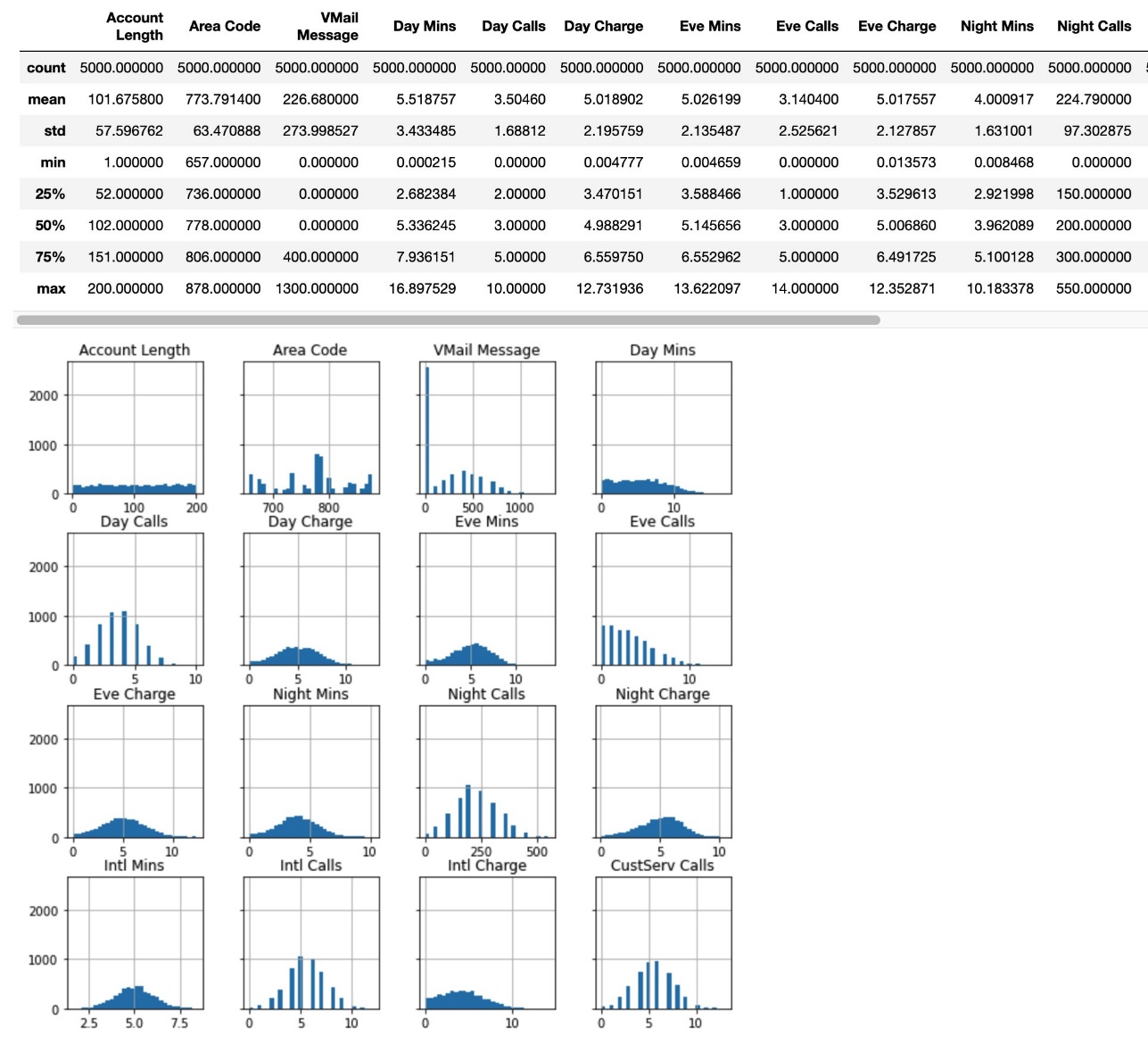
Luego preprocesamos los datos, dividiéndolos en conjuntos de entrenamiento, validación y prueba, y subiendo los datos a Amazon Simple Storage Service (Amazon S3).
Optimización automática de modelos de algoritmos tabulares
Los hiperparámetros controlan cómo funcionan nuestros algoritmos subyacentes y afectan el rendimiento del modelo. Estos hiperparámetros pueden ser la cantidad de capas, la tasa de aprendizaje, la tasa de pérdida de peso y la falla para los modelos basados en redes neuronales, o la cantidad de hojas, iteraciones y la profundidad máxima del árbol para los modelos de conjuntos de árboles. Para seleccionar el mejor modelo, aplicamos la optimización automática del modelo de SageMaker a cada uno de los cuatro algoritmos tabulares de SageMaker entrenados. Todo lo que tiene que hacer es seleccionar los hiperparámetros para ajustar y un rango para examinar cada parámetro. Para obtener más información sobre el ajuste automático de modelos, consulte Ajuste automático de modelos de Amazon SageMaker: uso del aprendizaje automático para el aprendizaje automático o Ajuste automático de modelos de Amazon SageMaker: optimización escalable sin degradado.
Veamos cómo funciona esto en la práctica.
LuzGBM
Comenzamos con la optimización automática del modelo con LightGBM y adaptamos este proceso a los otros algoritmos. Como se explica en Amazon SageMaker JumpStart Models and Algorithms Now Available via API post, se requieren los siguientes artefactos para entrenar un algoritmo preconstruido a través del SDK de SageMaker:
- Su imagen de contenedor específica del marco que contiene todas las dependencias necesarias para el entrenamiento y la inferencia
- Los scripts de entrenamiento e inferencia para el modelo o algoritmo seleccionado
Primero recuperamos aquellos artefactos que dependen de la model_id (lightgbm-classification-model en este caso) y versión:
Luego obtenemos los hiperparámetros predeterminados para LightGBM, configuramos algunos de ellos en valores fijos seleccionados, como el número de rondas de impulso y la métrica de puntuación de datos de validación, y definimos los rangos de valores que queremos buscar para otros. Usamos los parámetros de SageMaker ContinuousParameter y IntegerParameter Por lo tanto:
Finalmente, creamos un SageMaker Estimator, lo ingresamos en un HyperparameterTuner y comenzamos el trabajo de ajuste de hiperparámetros. tuner.fit():
Que max_jobs El parámetro define cuántos trabajos se ejecutarán en total en el trabajo de optimización automática del modelo, y max_parallel_jobs define cuántos trabajos de entrenamiento simultáneos deben iniciarse. También definimos el destino “Maximize” el AUC (área bajo la curva) del modelo. Para profundizar en los parámetros disponibles HyperParameterTunerver HyperparameterTuner.
Consulte el cuaderno de muestra para ver cómo implementamos y evaluamos este modelo en el conjunto de prueba.
gatoboost
El proceso de ajuste de hiperparámetros en el algoritmo CatBoost es el mismo que antes, aunque necesitamos recuperar los artefactos del modelo bajo el ID catboost-classification-model y cambiar la selección de rango de hiperparámetros:
Transformador de pestañas
El proceso de ajuste de hiperparámetros en el modelo TabTransformer es el mismo que antes, aunque necesitamos recuperar los artefactos del modelo bajo el ID. pytorch-tabtransformerclassification-model y cambiar la selección de rango de hiperparámetros.
También estamos cambiando la formación. instance_type a ml.p3.2xlarge. TabTransformer es un modelo derivado recientemente de la investigación de Amazon que utiliza modelos de Transformer para llevar el poder del aprendizaje profundo a los datos tabulares. Para entrenar este modelo de manera eficiente, necesitamos una instancia respaldada por GPU. Para obtener más información, consulte Aprovechar el poder del aprendizaje profundo para datos en tablas.
Mesa AutoGluon
Con AutoGluon, no realizamos ajustes de hiperparámetros. Esto es intencionado, ya que AutoGluon se centra en fusionar varios modelos con una selección razonable de hiperparámetros y apilarlos en varias capas. Al final, esto tiene más rendimiento que entrenar un modelo con la selección perfecta de hiperparámetros y también es computacionalmente más económico. Para obtener más información, consulte AutoGluon Tabular: AutoML sólido y preciso para datos estructurados.
Por eso los estamos cambiando. model_id a autogluon-classification-ensembley fije solo el hiperparámetro de la métrica de evaluación a nuestra puntuación AUC deseada:
en lugar de llamar tuner.fit()nosotros llamamos estimator.fit() para comenzar un solo aprendizaje.
Benchmarking de los modelos entrenados
Después de implementar los cuatro modelos, enviamos el conjunto de prueba completo a cada punto final para la predicción y calculamos las métricas de precisión, F1 y AUC para cada uno (consulte el código en el cuaderno de muestra). Presentamos los resultados en la siguiente tabla con un descargo de responsabilidad importante: los resultados y el rendimiento relativo entre estos modelos dependen del conjunto de datos que utilice para el entrenamiento. Estos resultados son representativos y, si bien la tendencia de ciertos algoritmos a funcionar mejor se basa en factores relevantes (p. ej., AutoGluon combina de manera inteligente las predicciones de los modelos LightGBM y CatBoost entre bastidores), esto podría cambiar el balance de energía en otra distribución de datos de cambio.
| . | LightGBM con optimización automática de modelos | CatBoost con optimización automática de modelos | TabTransformer con optimización automática de modelos | Mesa AutoGluon |
| precisión | 0.8977 | 0.9622 | 0.9511 | 0.98 |
| F1 | 0.8986 | 0.9624 | 0.9517 | 0.98 |
| ABC | 0.9629 | 0.9907 | 0.989 | 0.9979 |
Conclusión
En esta publicación, entrenamos cuatro algoritmos diferentes integrados en SageMaker para resolver el problema de abandono de clientes con poco esfuerzo de programación. Utilizamos la optimización automática del modelo de SageMaker para encontrar los mejores hiperparámetros para entrenar estos algoritmos y comparamos su rendimiento con un conjunto de datos de predicción de abandono seleccionado. Puede usar el cuaderno de muestra adjunto como plantilla y reemplazar el conjunto de datos con el suyo propio para resolver el problema basado en datos tabulares que desee.
Pruebe estos algoritmos en SageMaker y consulte cuadernos de muestra sobre el uso de otros algoritmos integrados disponibles en GitHub.
Sobre los autores
 dr. XinHuang es científico aplicado de los algoritmos integrados de Amazon SageMaker JumpStart y Amazon SageMaker. Se centra en el desarrollo de algoritmos escalables de aprendizaje automático. Sus intereses de investigación son el procesamiento del lenguaje natural, el aprendizaje profundo explicable en datos tabulares y el análisis sólido de la agrupación de espacio-tiempo no paramétrica. Ha publicado numerosos artículos en conferencias ACL, ICDM, KDD y en la revista Royal Statistical Society: Serie A.
dr. XinHuang es científico aplicado de los algoritmos integrados de Amazon SageMaker JumpStart y Amazon SageMaker. Se centra en el desarrollo de algoritmos escalables de aprendizaje automático. Sus intereses de investigación son el procesamiento del lenguaje natural, el aprendizaje profundo explicable en datos tabulares y el análisis sólido de la agrupación de espacio-tiempo no paramétrica. Ha publicado numerosos artículos en conferencias ACL, ICDM, KDD y en la revista Royal Statistical Society: Serie A.
 joao moura es Arquitecto de Soluciones Especialista en AI/ML en Amazon Web Services. Centrado principalmente en casos de uso de NLP, ayuda a los clientes a optimizar la capacitación y la implementación de modelos de aprendizaje profundo. También es un defensor activo de las soluciones de aprendizaje automático de código bajo y el hardware especializado en aprendizaje automático.
joao moura es Arquitecto de Soluciones Especialista en AI/ML en Amazon Web Services. Centrado principalmente en casos de uso de NLP, ayuda a los clientes a optimizar la capacitación y la implementación de modelos de aprendizaje profundo. También es un defensor activo de las soluciones de aprendizaje automático de código bajo y el hardware especializado en aprendizaje automático.
[ad_2]