[ad_1]

Muchas emocionantes aplicaciones contemporáneas de la informática y el aprendizaje automático (ML) manipulan conjuntos de datos multidimensionales que abarcan un solo sistema de coordenadas grande, z o escaneo 3D. En esta configuración, incluso un solo conjunto de datos puede requerir terabytes o petabytes de almacenamiento de datos. Trabajar con tales conjuntos de datos también es un desafío, ya que los usuarios pueden leer y escribir datos a intervalos irregulares y en diferentes escalas, y a menudo están interesados en realizar análisis con varias máquinas trabajando en paralelo.
Hoy presentamos TensorStore, una biblioteca de software de C++ y Python de código abierto que se utiliza para almacenar y manipular norte-Datos de dimensión que:
- Proporciona una API unificada para leer y escribir múltiples formatos de matriz, incluidos Zarr y N5.
- Admite de forma nativa múltiples sistemas de almacenamiento, incluido Google Cloud Storage, sistemas de archivos locales y de red, servidores HTTP y almacenamiento en memoria.
- Admite el almacenamiento en caché de lectura/reescritura y las transacciones con sólidas garantías de atomicidad, aislamiento, consistencia y durabilidad (ACID).
- Admite el acceso seguro y eficiente desde múltiples procesos y máquinas a través de la concurrencia optimista.
- Proporciona una API asíncrona para habilitar el acceso de alto rendimiento incluso al almacenamiento remoto de alta latencia.
- Proporciona vistas virtuales y operaciones de indexación avanzadas y totalmente componibles.
TensorStore ya se ha utilizado para resolver desafíos técnicos clave en la computación científica (por ejemplo, administrar y procesar grandes conjuntos de datos en neurociencia, como datos de microscopía electrónica 3D a escala peta y videos «4D» de actividad neuronal). TensorStore también se ha utilizado en la creación de modelos de aprendizaje automático a gran escala como PaLM al abordar el problema de la gestión de los parámetros del modelo (puntos de control) durante el entrenamiento distribuido.
API familiar para acceso y manipulación de datos
TensorStore proporciona una API de Python simple para cargar y manipular grandes matrices de datos. En el siguiente ejemplo, creamos un objeto TensorStore que representa una imagen 3D de un cerebro de mosca de 56 billones de vóxeles y accedemos a un pequeño parche de 100×100 de los datos como una matriz NumPy:
>>> import tensorstore as ts
>>> import numpy as np
# Create a TensorStore object to work with fly brain data.
>>> dataset = ts.open({
... 'driver':
... 'neuroglancer_precomputed',
... 'kvstore':
... 'gs://neuroglancer-janelia-flyem-hemibrain/v1.1/segmentation/',
... }).result()
# Create a 3-d view (remove singleton 'channel' dimension):
>>> dataset_3d = dataset[ts.d['channel'][0]]
>>> dataset_3d.domain
{ "x": [0, 34432), "y": [0, 39552), "z": [0, 41408) }
# Convert a 100x100x1 slice of the data to a numpy ndarray
>>> slice = np.array(dataset_3d[15000:15100, 15000:15100, 20000])
Fundamentalmente, no se accede a ningún dato real ni se almacena en la memoria hasta que se solicita el segmento específico de 100×100; Por lo tanto, los conjuntos de datos subyacentes de cualquier tamaño se pueden cargar y editar sin tener que almacenar todo el conjunto de datos en la memoria, usando una sintaxis de indexación y edición en gran parte idéntica a las operaciones estándar de NumPy. TensorStore también brinda un amplio soporte para funciones de indexación avanzadas, incluidas transformaciones, alineación, transmisión y vistas virtuales (conversión de tipo de datos, reducción de resolución, matrices generadas de forma diferida sobre la marcha).
El siguiente ejemplo muestra cómo se puede usar TensorStore para crear una matriz Zarr y cómo su API asíncrona permite un mayor rendimiento:
>>> import tensorstore as ts
>>> import numpy as np
>>> # Create a zarr array on the local filesystem
>>> dataset = ts.open({
... 'driver': 'zarr',
... 'kvstore': 'file:///tmp/my_dataset/',
... },
... dtype=ts.uint32,
... chunk_layout=ts.ChunkLayout(chunk_shape=[256, 256, 1]),
... create=True,
... shape=[5000, 6000, 7000]).result()
>>> # Create two numpy arrays with example data to write.
>>> a = np.arange(100*200*300, dtype=np.uint32).reshape((100, 200, 300))
>>> b = np.arange(200*300*400, dtype=np.uint32).reshape((200, 300, 400))
>>> # Initiate two asynchronous writes, to be performed concurrently.
>>> future_a = dataset[1000:1100, 2000:2200, 3000:3300].write(a)
>>> future_b = dataset[3000:3200, 4000:4300, 5000:5400].write(b)
>>> # Wait for the asynchronous writes to complete
>>> future_a.result()
>>> future_b.result()
Escalado seguro y de alto rendimiento
Procesar y analizar grandes conjuntos de datos numéricos requiere importantes recursos computacionales. Esto generalmente se logra a través de la paralelización en numerosos núcleos de CPU o aceleradores distribuidos en muchas máquinas. Por lo tanto, un objetivo fundamental de TensorStore era permitir el procesamiento paralelo de conjuntos de datos únicos que fuera seguro (es decir, evitar la corrupción o las inconsistencias debido a patrones de acceso paralelo) y de alto rendimiento (es decir, leer y escribir en TensorStore no es un cuello de botella durante el cálculo) . . De hecho, cuando se probó en los centros de datos de Google, vimos una escala casi lineal del rendimiento de lectura y escritura a medida que aumentaba la cantidad de CPU:
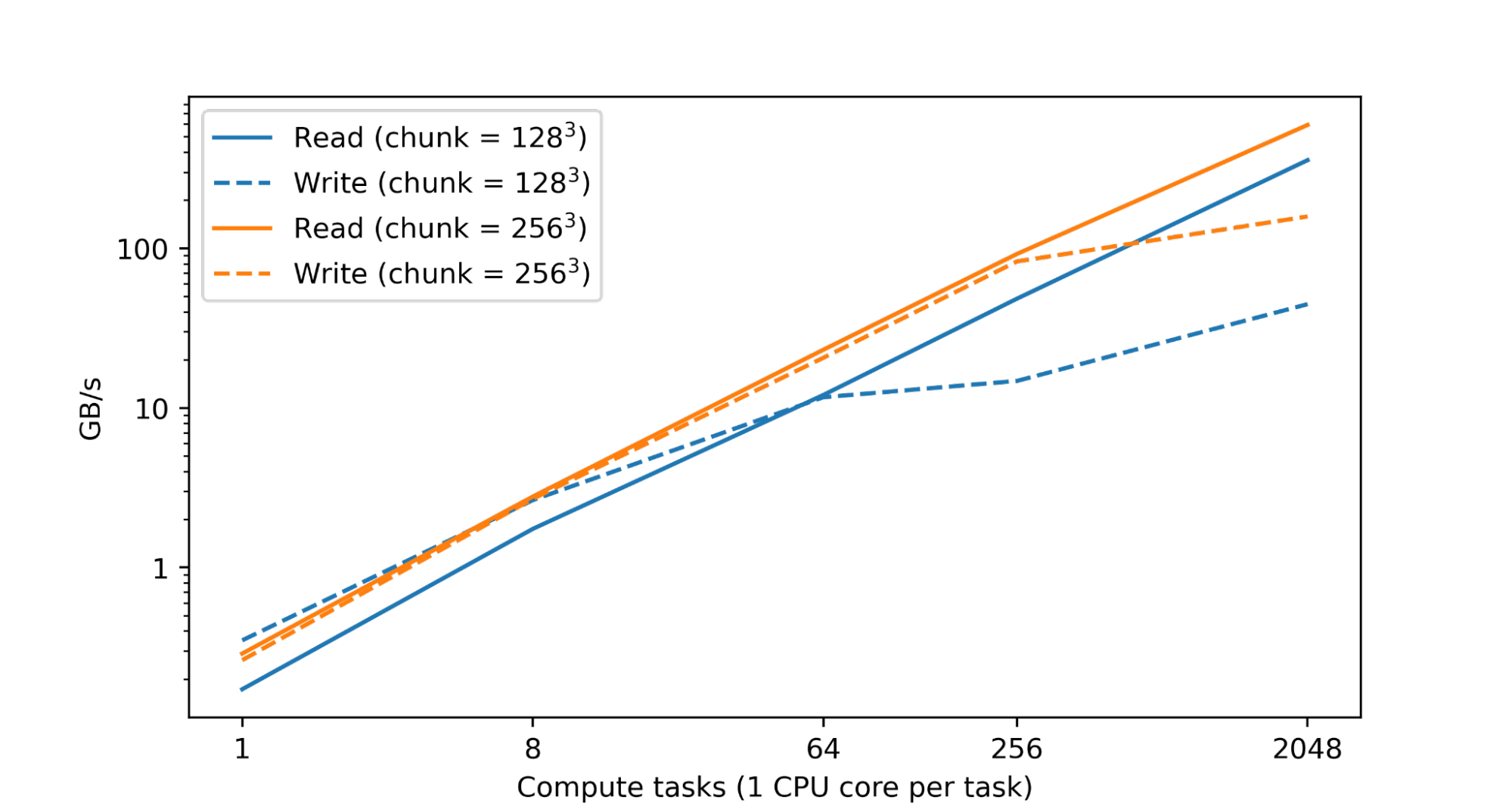 |
| Rendimiento de lectura y escritura para un conjunto de datos de TensorStore en formato Zarr que reside en Google Cloud Storage (GCS) y al que accede simultáneamente una cantidad variable de tareas informáticas de un solo núcleo en los centros de datos de Google. Tanto el rendimiento de lectura como el de escritura escalan casi linealmente con la cantidad de tareas informáticas. |
El rendimiento se logra implementando operaciones centrales en C++, haciendo un uso extensivo de subprocesos múltiples para operaciones como codificación/descodificación y E/S de red, y dividiendo grandes conjuntos de datos en unidades mucho más pequeñas a través de fragmentación para permitir la lectura y escritura eficiente de subconjuntos de la para habilitar todo el conjunto de datos. TensorStore también ofrece almacenamiento en memoria caché configurable (que reduce las interacciones más lentas del sistema de almacenamiento para los datos a los que se accede con frecuencia) y una API asíncrona que permite que una operación de lectura o escritura continúe en segundo plano mientras un programa maneja otras tareas.
La seguridad de las operaciones paralelas cuando muchas máquinas acceden al mismo conjunto de datos se logra mediante el uso de concurrencia optimista, que mantiene la compatibilidad con varios niveles de almacenamiento subyacentes (incluidas las plataformas de almacenamiento en la nube como GCS y los sistemas de archivos locales) sin afectar significativamente el rendimiento. TensorStore también ofrece sólidas garantías ACID para todas las operaciones individuales realizadas en un solo tiempo de ejecución.
Para que la computación distribuida con TensorStore sea compatible con muchos flujos de trabajo de procesamiento de datos existentes, también hemos integrado TensorStore con bibliotecas de computación paralela como Apache Beam (código de muestra) y Dask (código de muestra).
Caso de uso: modelos de lenguaje
Un nuevo desarrollo emocionante en ML es la aparición de modelos de lenguaje más avanzados como PaLM. Estas redes neuronales contienen cientos de miles de millones de parámetros y exhiben algunas habilidades sorprendentes para comprender y generar lenguaje natural. Estos modelos también amplían los límites de la infraestructura informática; En particular, entrenar un modelo de lenguaje como PaLM requiere miles de TPU trabajando en paralelo.
Un desafío que surge durante este proceso de entrenamiento es la lectura y escritura eficiente de los parámetros del modelo. La capacitación se distribuye en muchas máquinas separadas, pero los parámetros deben guardarse periódicamente en un solo objeto («punto de control») en un sistema de almacenamiento persistente sin ralentizar todo el proceso de capacitación. Los trabajos de entrenamiento individuales también deben poder leer solo el conjunto específico de parámetros con los que están tratando para evitar la sobrecarga que se requeriría para cargar todo el conjunto de parámetros del modelo (que puede ser de cientos de gigabytes).
TensorStore ya se ha utilizado para abordar estos desafíos. Se ha aplicado para administrar puntos de control asociados con modelos a gran escala («multipod») entrenados con JAX (ejemplo de código) y se ha integrado en marcos como T5X (ejemplo de código) y Pathways. El paralelismo de modelos se usa para distribuir el conjunto de parámetros completo, que puede consumir más de un terabyte de memoria, en cientos de TPU. Los puntos de control se almacenan en formato Zarr mediante TensorStore, con una estructura de fragmentos elegida para permitir que la partición se lea y escriba de forma independiente para cada TPU.
 |
| Al almacenar un punto de control, cada parámetro del modelo se escribe con TensorStore en formato Zarr mediante una cuadrícula de bloques que subdivide aún más la cuadrícula utilizada para dividir el parámetro entre las TPU. Las máquinas host escriben en paralelo los bloques Zarr para cada una de las particiones asignadas a las TPU adjuntas a ese host. Con la API asíncrona de TensorStore, la capacitación continúa mientras los datos aún se escriben en el almacenamiento persistente. Al reanudar desde un punto de control, cada host lee solo los fragmentos que componen las particiones asignadas a ese host. |
Caso de uso: mapeo cerebral en 3D
El campo de la conectómica de resolución de sinapsis tiene como objetivo mapear el cableado de los cerebros humanos y animales al nivel detallado de las conexiones sinápticas individuales. Esto requiere obtener imágenes del cerebro a una resolución extremadamente alta (nanómetros) en campos de visión de hasta milímetros o más, lo que genera conjuntos de datos tan grandes como petabytes. En el futuro, estos conjuntos de datos podrían expandirse a exabytes si los científicos consideran mapear cerebros completos de ratones o primates. Pero incluso los conjuntos de datos actuales plantean desafíos importantes en términos de almacenamiento, manipulación y procesamiento; En particular, incluso una sola muestra de cerebro puede requerir millones de gigabytes con un sistema de coordenadas (espacio de píxeles) de cientos de miles de píxeles en cada dimensión.
Usamos TensorStore para resolver desafíos computacionales relacionados con grandes conjuntos de datos conectómicos. Específicamente, TensorStore ha administrado algunos de los conjuntos de datos de Connectomic más grandes y de mayor acceso, con Google Cloud Storage como el sistema de almacenamiento de objetos subyacente. Por ejemplo, se aplicó al conjunto de datos de la corteza humana «h01», que es una imagen 3D con resolución nanométrica del tejido cerebral humano. Los datos de imagen sin procesar son 1,4 petabytes (aprox. 500 000 * 350 000 * 5000 píxeles) y se asocian además con contenido adicional, como segmentaciones 3D y anotaciones que se encuentran en el mismo sistema de coordenadas. Los datos sin procesar se almacenan en fragmentos individuales de 128 x 128 x 16 píxeles en formato precomputado de Neuroglancer, que está optimizado para la visualización interactiva basada en la web y se puede manipular fácilmente desde TensorStore.
Empezado
Para comenzar a usar la API Python de TensorStore, puede instalar el paquete PyPI de tensorstore con:
pip install tensorstore
Consulte los tutoriales y la documentación de la API para obtener detalles de uso. Consulte las instrucciones de instalación para conocer otras opciones de instalación y usar la API de C++.
Gracias
Gracias a Tim Blakely, Viren Jain, Yash Katariya, Jan-Matthis Luckmann, Michał Januszewski, Peter Li, Adam Roberts, Brain Williams y Hector Yee de Google Research, así como a Davis Bennet, Stuart Berg, Eric Perlman, Stephen Plaza, y Juan Nunez-Iglesias de la comunidad científica en general por sus valiosos comentarios sobre el diseño, las primeras pruebas y la depuración.
[ad_2]