
[ad_1]
Si buscó en amazon.com un artículo que desea comprar, utilizó los servicios de búsqueda de Amazon. En Amazon Search, somos responsables de la experiencia de búsqueda y descubrimiento de nuestros clientes en todo el mundo. Detrás de escena, indexamos nuestro catálogo global de productos, implementamos flotas de AWS altamente escalables y utilizamos aprendizaje automático (ML) avanzado para hacer coincidir productos relevantes e interesantes con cada solicitud de cliente.
Nuestros científicos entrenan regularmente miles de modelos ML para mejorar la calidad de los resultados de búsqueda. Apoyar experimentos a gran escala presenta sus propios desafíos, particularmente cuando se trata de mejorar la productividad de los científicos que entrenan estos modelos ML.
En esta publicación, compartimos cómo creamos un sistema de administración de trabajos de capacitación de Amazon SageMaker que permite a nuestros científicos eliminar y olvidar miles de experimentos y recibir notificaciones cuando sea necesario. Ahora pueden concentrarse en tareas de alto valor y corregir errores algorítmicos, ahorrando el 60 % de su tiempo.
El reto
En Amazon Search, nuestros científicos resuelven problemas de recuperación de información experimentando y ejecutando numerosos trabajos de entrenamiento de modelos de ML en SageMaker. Para mantenerse al día con la innovación de nuestro equipo, la complejidad de nuestros modelos y la cantidad de asignaciones de capacitación han aumentado con el tiempo. Con los trabajos de capacitación de SageMaker, podemos reducir el tiempo y el costo de la capacitación y el ajuste de estos modelos a escala sin tener que administrar la infraestructura.
Como todo en proyectos de ML tan grandes, los trabajos de capacitación pueden fallar debido a una variedad de factores. Esta publicación se centra en los cuellos de botella de capacidad y las interrupciones debido a errores de algoritmo.
Diseñamos una arquitectura con un sistema de gestión de trabajos para tolerar y reducir la probabilidad de que un trabajo falle por falta de capacidad o errores de algoritmo. Permite a los científicos eliminar y olvidar miles de trabajos de capacitación, volver a intentarlos automáticamente en caso de fallas transitorias y recibir notificaciones de éxito o falla si es necesario.
descripción general de la solución
En el siguiente diagrama de solución, usamos los trabajos de capacitación de SageMaker como la unidad básica de nuestra solución. Es decir, un trabajo representa el entrenamiento integral de un modelo de ML.
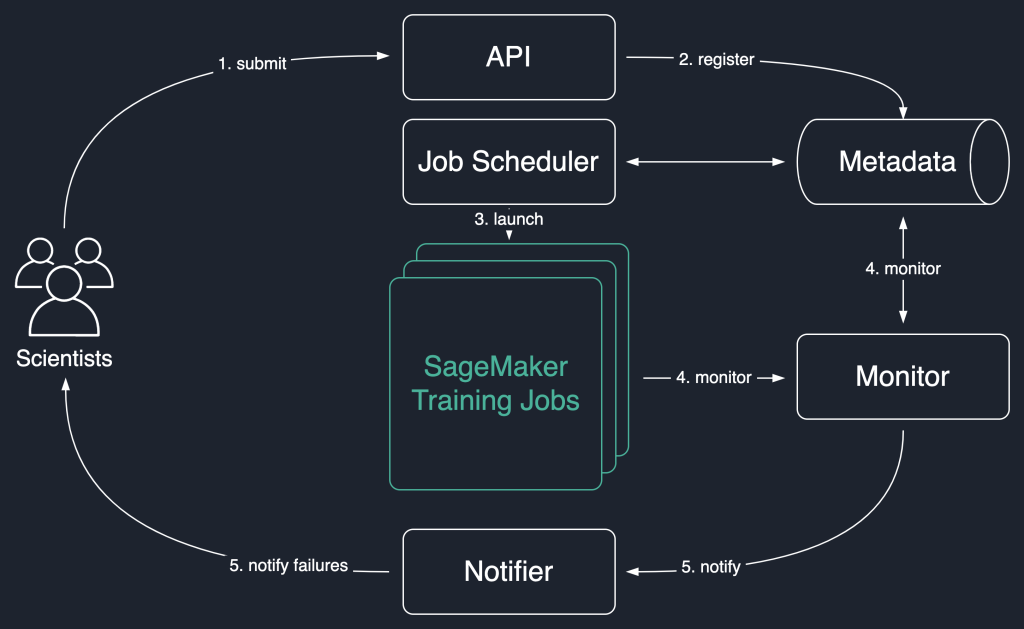
El flujo de trabajo de alto nivel de esta solución se ve así:
- Los científicos llaman a una API para enviar un nuevo trabajo al sistema.
- El trabajo está registrado en el
NewEstado en un almacén de metadatos. - Un programador de trabajos sondea de forma asíncrona
Newtrabajos del almacén de metadatos, analiza su entrada e intenta iniciar trabajos de entrenamiento de SageMaker para cada uno. Su estado cambia aLaunchedoFaileddependiendo del éxito. - Un monitor verifica el progreso de los trabajos a intervalos regulares e informa sobre su progreso
Completed,FailedoInProgressEstado en el almacén de metadatos. - Se le pide a un reportero que informe
CompletedyFailedtrabajos para científicos.
Al mantener el historial de trabajos en el almacenamiento de metadatos, nuestro equipo también puede realizar análisis de tendencias y monitorear el progreso del proyecto.
Esta solución de programación de trabajos utiliza componentes sin servidor acoplados libremente basados en AWS Lambda, Amazon DynamoDB, Amazon Simple Notification Service (Amazon SNS) y Amazon EventBridge. Esto garantiza la escalabilidad horizontal, lo que permite a nuestros científicos lanzar miles de trabajos con una sobrecarga operativa mínima. El siguiente diagrama ilustra la arquitectura sin servidor.
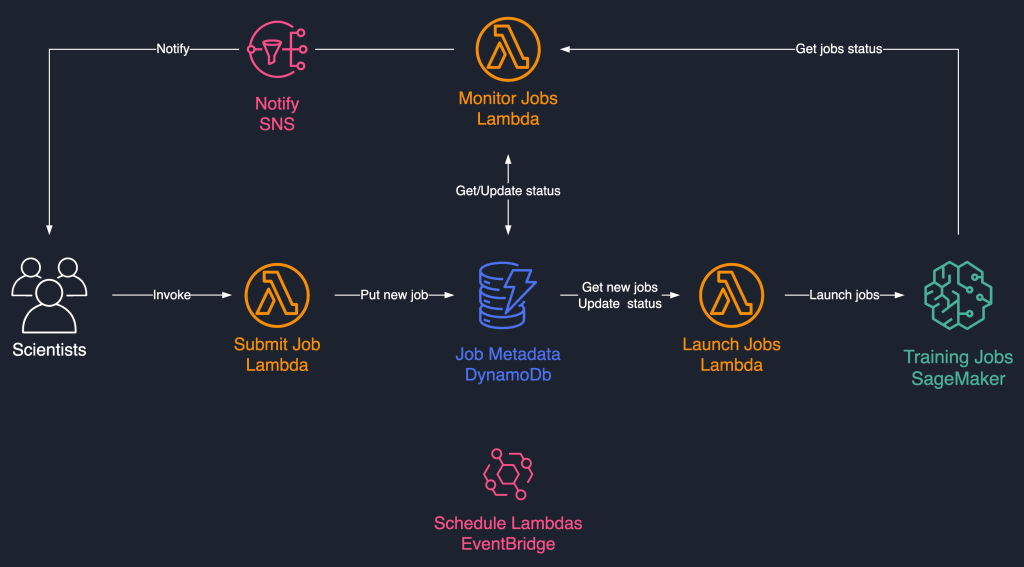
En las siguientes secciones, entramos en más detalles sobre cada servicio y sus componentes.
DynamoDB como almacén de metadatos para la ejecución de trabajos
La facilidad de uso y la escalabilidad de DynamoDB hicieron que conservar los metadatos del trabajo en una tabla de DynamoDB fuera una opción natural. Esta solución almacena múltiples atributos de trabajos enviados por científicos, lo que ayuda con el seguimiento del progreso y la orquestación del flujo de trabajo. Los principales atributos son los siguientes:
- Identificación del trabajo – Una identificación de trabajo única. Esto puede ser generado automáticamente o proporcionado por el científico.
- estado del trabajo – El estado del trabajo.
- Argumentos de trabajo – Otros argumentos necesarios para crear un puesto de formación, como B. la ruta de entrada en Amazon S3, el URI de la imagen de entrenamiento y más. Para obtener una lista completa de los parámetros necesarios para crear un trabajo de entrenamiento, consulte CreateTrainingJob.
Lambda para la lógica central
Utilizamos tres funciones Lambda basadas en contenedores para orquestar el flujo de trabajo del trabajo:
- Enviar orden – Los científicos llaman a esta función cuando necesitan comenzar nuevos trabajos. Actúa como una API por conveniencia. También puede presentarlo con Amazon API Gateway si es necesario. Esta función registra los trabajos en la tabla de DynamoDB.
- iniciar trabajos – Esta función sondea regularmente
Newtrabajos de la tabla de DynamoDB y los inicia con el comando CreateTrainingJob de SageMaker. En el caso de errores temporales, p.ResourceLimitExceededyCapacityErrorpara instrumentar la resiliencia en el sistema. Luego actualiza el estado del pedido comoLaunchedoFaileddependiendo del éxito. - monitorear trabajos – Esta función realiza un seguimiento periódico del progreso del trabajo mediante el comando DescribeTrainingJob y actualiza la tabla de DynamoDB en consecuencia. consulta
FailedJobs de los metadatos y evalúa si deben volver a enviarse o marcarse como fallidos definitivamente. También publica notificaciones a los científicos cuando sus trabajos llegan a un estado final.
EventBridge para la planificación
Usamos EventBridge para ejecutar las funciones Lambda Start Jobs y Monitor Jobs según un cronograma. Para obtener más información, consulte Tutorial: programación de funciones de AWS Lambda con EventBridge.
De manera alternativa, puede usar Amazon DynamoDB Streams para los disparadores. Para obtener más información, consulte Transmisiones de DynamoDB y activadores de AWS Lambda.
Notificaciones con Amazon SNS
Nuestros científicos reciben una notificación por correo electrónico a través de Amazon SNS cuando sus trabajos alcanzan un estado final (Failed después de un número máximo de repeticiones), Completedo Stopped.
Conclusión
En esta publicación, compartimos cómo Amazon Search hace que las cargas de entrenamiento del modelo ML sean más resistentes al programarlas y repetirlas en caso de cuellos de botella de capacidad o errores de algoritmo. Utilizamos funciones de Lambda junto con una tabla de DynamoDB como almacén central de metadatos para organizar todo el flujo de trabajo.
Tal sistema de programación permite a los científicos enviar sus trabajos y olvidarse de ellos. Esto ahorra tiempo y les permite concentrarse en escribir mejores modelos.
Para continuar con su proceso de aprendizaje, puede visitar Awesome SageMaker y encontrar todos los recursos relevantes y actualizados necesarios para trabajar con SageMaker en un solo lugar.
Sobre los autores
 luochao wang es ingeniero de software en Amazon Search. Se enfoca en sistemas distribuidos escalables y herramientas de automatización en la nube para acelerar el ritmo de la innovación científica para aplicaciones de aprendizaje automático.
luochao wang es ingeniero de software en Amazon Search. Se enfoca en sistemas distribuidos escalables y herramientas de automatización en la nube para acelerar el ritmo de la innovación científica para aplicaciones de aprendizaje automático.
 Ishan Bhatt es ingeniero de software en el equipo de Amazon Prime Video. Trabaja principalmente en el espacio MLOps y tiene experiencia en el desarrollo de productos MLOps con Amazon SageMaker durante los últimos 4 años.
Ishan Bhatt es ingeniero de software en el equipo de Amazon Prime Video. Trabaja principalmente en el espacio MLOps y tiene experiencia en el desarrollo de productos MLOps con Amazon SageMaker durante los últimos 4 años.
 Abhinandan Patni es ingeniero de software sénior en Amazon Search. Se centra en la creación de sistemas y herramientas para la formación de aprendizaje profundo distribuido escalable y la inferencia en tiempo real.
Abhinandan Patni es ingeniero de software sénior en Amazon Search. Se centra en la creación de sistemas y herramientas para la formación de aprendizaje profundo distribuido escalable y la inferencia en tiempo real.
 Eiman Elnahrawy es ingeniero principal de software en Amazon Search y lidera los esfuerzos para acelerar, escalar y automatizar el aprendizaje automático. Su experiencia abarca múltiples áreas, incluido el aprendizaje automático, los sistemas distribuidos y la personalización.
Eiman Elnahrawy es ingeniero principal de software en Amazon Search y lidera los esfuerzos para acelerar, escalar y automatizar el aprendizaje automático. Su experiencia abarca múltiples áreas, incluido el aprendizaje automático, los sistemas distribuidos y la personalización.
 Sofian Hamiti es un arquitecto de soluciones de IA/ML en AWS. Ayuda a los clientes de todas las industrias a acelerar su viaje de IA/ML ayudándolos a diseñar y poner en funcionamiento soluciones de aprendizaje automático de extremo a extremo.
Sofian Hamiti es un arquitecto de soluciones de IA/ML en AWS. Ayuda a los clientes de todas las industrias a acelerar su viaje de IA/ML ayudándolos a diseñar y poner en funcionamiento soluciones de aprendizaje automático de extremo a extremo.
 dr. Romi Datta es gerente sénior de administración de productos en el equipo de Amazon SageMaker y responsable de la capacitación, el procesamiento y la tienda de características. Ha estado en AWS durante más de 4 años y ha ocupado varios puestos sénior de gestión de productos en SageMaker, S3 e IoT. Antes de AWS, trabajó en varios puestos de gestión de productos, ingeniería y liderazgo operativo en IBM, Texas Instruments y Nvidia. Tiene una maestría y un doctorado. en Ingeniería Eléctrica e Informática de la Universidad de Texas en Austin y un MBA de la Escuela de Negocios Booth de la Universidad de Chicago.
dr. Romi Datta es gerente sénior de administración de productos en el equipo de Amazon SageMaker y responsable de la capacitación, el procesamiento y la tienda de características. Ha estado en AWS durante más de 4 años y ha ocupado varios puestos sénior de gestión de productos en SageMaker, S3 e IoT. Antes de AWS, trabajó en varios puestos de gestión de productos, ingeniería y liderazgo operativo en IBM, Texas Instruments y Nvidia. Tiene una maestría y un doctorado. en Ingeniería Eléctrica e Informática de la Universidad de Texas en Austin y un MBA de la Escuela de Negocios Booth de la Universidad de Chicago.
 R. J. es ingeniero en el equipo de Search M5 que lidera los esfuerzos para construir sistemas de aprendizaje profundo a gran escala para capacitación e inferencia. Fuera del trabajo, explora diferentes cocinas y practica deportes de raqueta.
R. J. es ingeniero en el equipo de Search M5 que lidera los esfuerzos para construir sistemas de aprendizaje profundo a gran escala para capacitación e inferencia. Fuera del trabajo, explora diferentes cocinas y practica deportes de raqueta.
[ad_2]