
[ad_1]
La inteligencia artificial (IA) y el aprendizaje automático (ML) ahora se consideran esenciales para mejorar las soluciones en cualquier segmento del mercado a través de su capacidad para aprender y mejorar continuamente la experiencia y los resultados. A medida que estas soluciones se vuelven más populares, existe una necesidad cada vez mayor de aprendizaje y personalización seguros. Sin embargo, el coste de entrenar la IA para tareas específicas de aplicaciones es el mayor desafío del mercado.
El único desafío en el mercado de la IA para ampliar es el costo de implementar la IA. Si nos fijamos en GPT-3, ¡una sola sesión de entrenamiento cuesta semanas y 6 millones de dólares! Por lo tanto, cada vez que se introduce un nuevo modelo o un cambio, el recuento comienza de nuevo desde cero y hay que volver a entrenar el modelo actual, lo que resulta bastante caro. Varias cosas afectan el entrenamiento de estos modelos, como por ejemplo: B. Deriva, pero la necesidad de reentrenamiento para adaptarse ciertamente ayudaría a gestionar el costo del reentrenamiento.
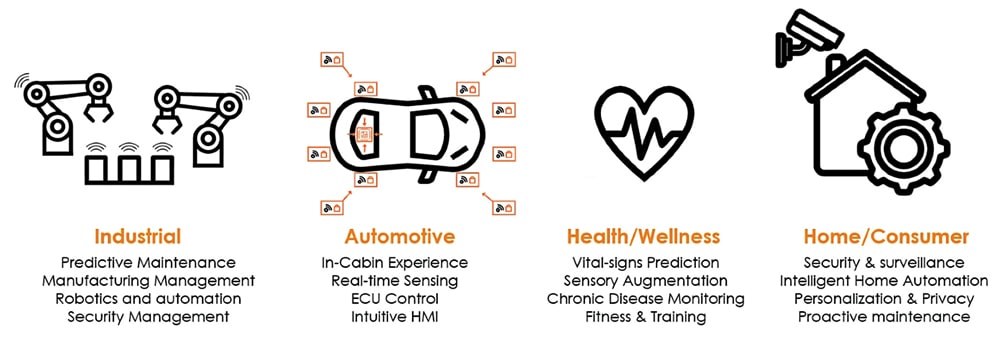
Pensemos en la industria manufacturera, que espera perder alrededor de 50.000 millones de dólares al año por problemas de mantenimiento evitables. Hay costos de inactividad porque el mantenimiento no se realizó a tiempo. Otra estadística asombrosa muestra la pérdida de productividad en Estados Unidos debido a que la gente no va a trabajar, ya que el costo de las enfermedades crónicas prevenibles es de 1,1 billones de dólares. Esto es sólo la pérdida de productividad, no los costos de atención médica.
Esto podría haberse reducido significativamente con una vigilancia sanitaria digital más potente y menos costosa. Por lo tanto, se requiere IA en tiempo real cerca del dispositivo para detectar, predecir y solucionar problemas y planificar el mantenimiento de forma proactiva.
La IA funciona con datos, por lo que hay que considerar la cantidad de datos generados por todos los dispositivos. Consideremos sólo un coche. Un solo coche genera más de un terabyte de datos al día. Imagínese cuánto cuesta aprender de ello. ¿Imaginas cuántos coches hay que generan datos como este? ¿Qué le está haciendo a la red? Si bien no todos esos datos van a la nube, muchos de ellos se almacenan en algún lugar.
Estas son algunas de las oportunidades o problemas que la IA puede resolver, pero también los desafíos que impiden que la IA brinde esas soluciones. Las preguntas reales se pueden formular de la siguiente manera:
• ¿Cómo reducimos la latencia para mejorar la capacidad de respuesta del sistema?
• ¿Cómo podemos escalar realmente estos dispositivos? ¿Cómo podemos hacerlos rentables?
• ¿Cómo se garantiza la privacidad y la seguridad?
• ¿Cómo lidiar con la congestión de la red debido a la gran cantidad de datos generados?
La solución
Una variedad de factores afectan la latencia de un sistema. La capacidad del hardware, la latencia de la red y el uso de grandes cantidades de datos también son problemáticos. Estos dispositivos integran IA y también tienen capacidades de autoaprendizaje basadas en un procesamiento innovador de datos de series temporales para análisis predictivos. El mantenimiento predictivo es un factor importante en cualquier industria manufacturera, ya que la mayoría de las industrias ahora dependen de líneas de montaje robóticas. La experiencia en la cabina, por ejemplo, aprovecha un entorno similar habilitado por IA, incluso para el funcionamiento automatizado de vehículos autónomos (AV). Captar la predicción de los signos vitales y analizar datos médicos es un caso de uso importante para la salud y el bienestar. También en el ámbito de la seguridad y la vigilancia se utilizan actualmente cámaras de vigilancia con IA para una vigilancia continua.
«Cuantos más dispositivos inteligentes se fabriquen, mayor será el crecimiento de la inteligencia general».
La solución a la latencia radica en un modelo informático de IA distribuido, que es un componente sólido con la capacidad de incorporar dispositivos de IA de vanguardia para tener la capacidad de ejecutar el procesamiento de IA requerido. Más importante aún, para permitir una adaptación segura, necesitamos la capacidad de aprender en el dispositivo, lo que se puede lograr mediante el diseño de estos sistemas basado en eventos.
Esto reduce la cantidad de datos y evita enviar datos confidenciales a la nube, reduciendo la congestión de la red y la computación en la nube y mejorando la seguridad. Además, se brindan respuestas en tiempo real, lo que permite tomar medidas oportunas. Comprar estos dispositivos es tentador para muchas personas porque no se trata sólo del rendimiento sino también de cómo hacerlos rentables.
Los dispositivos neuronales generalmente se entrenan de dos maneras: usando datos alimentados por máquinas o usando picos, que imitan la funcionalidad de las redes neuronales con picos. Esto supone una carga para el sistema.
Un sistema neuronal, por otro lado, requiere una arquitectura que pueda acelerar todo tipo de redes neuronales, ya sea una red neuronal convolucional (CNN), una red neuronal profunda (DNN), una red neuronal de picos (SNN) o incluso la secuencia de Vision Transformers. predicción.
Por lo tanto, el uso de una arquitectura sin estado en sistemas distribuidos puede ayudar a reducir la carga en los servidores y el tiempo que le toma al sistema almacenar y recuperar datos. La arquitectura sin estado permite que las aplicaciones sigan siendo receptivas y escalables con una cantidad mínima de servidores, ya que no requiere que las aplicaciones mantengan registros de las sesiones.
El uso de controladores Direct Media Access (DMA) también puede mejorar la capacidad de respuesta. Este dispositivo de hardware permite que los dispositivos de entrada y salida accedan a la memoria directamente con menos participación del procesador. Es como dividir el trabajo entre las personas para aumentar la velocidad general, y eso es lo que está sucediendo aquí.
La plataforma Akida IP de Intel Movidius Myriad BraiChip también utiliza DMA de manera similar. También cuenta con un administrador de tiempo de ejecución que gestiona todas las operaciones del procesador neuronal de forma totalmente transparente, al que también se puede acceder a través de una sencilla API.
Otras características de estas plataformas incluyen el procesamiento de múltiples pasadas, en el que se procesan múltiples capas simultáneamente, lo que hace que el procesamiento sea muy eficiente. Una capacidad del dispositivo es la integración con un espacio más pequeño para crear menos nodos en una configuración y cambiar de la ejecución paralela a la ejecución secuencial. Eso significa latencia.
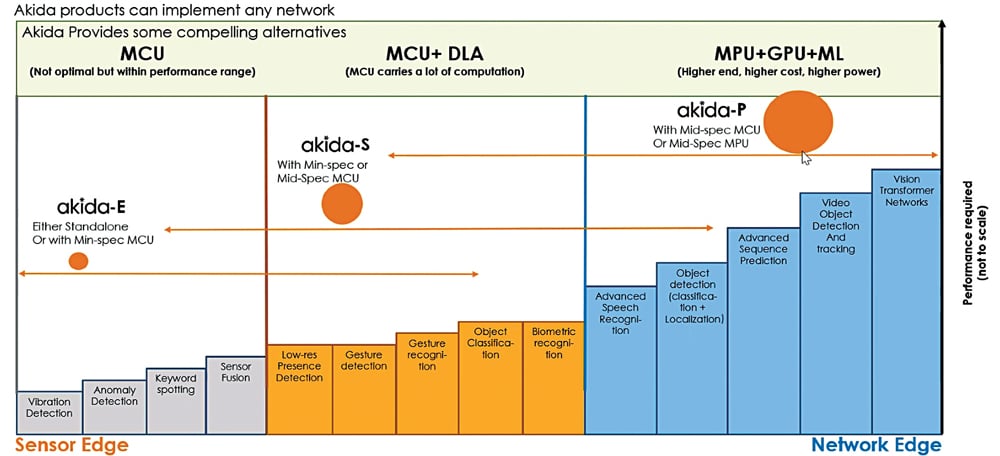
Sin embargo, una gran parte de esta latencia proviene de que la CPU se involucra cada vez que llega un turno. Dado que el dispositivo procesa varias capas al mismo tiempo y el DMA gestiona todas las actividades por sí mismo, las latencias se reducen significativamente.
Imagine un AV en el que los datos de diferentes sensores deben procesarse al mismo tiempo. El TDA4VM de Texas Instruments Inc. cuenta con un acelerador de aprendizaje profundo en chip dedicado que permite al vehículo detectar su entorno recopilando datos de entre cuatro y seis cámaras, un radar, un lidar e incluso un sensor ultrasónico. Asimismo, la plataforma IP de Akida puede ejecutar simultáneamente redes más grandes en una configuración más pequeña.
visión del mercado
Estos dispositivos tienen una gran variedad de usos en el mercado. Como se denominan dispositivos basados en eventos, tienen un alcance. Por ejemplo, las unidades de procesamiento de tensores (TPU) de Google, que son circuitos integrados de aplicaciones específicas (ASIC), están diseñadas para acelerar las cargas de trabajo de aprendizaje profundo en su plataforma en la nube. Los TPU ofrecen hasta 180 teraflops de rendimiento y se han utilizado para entrenar modelos de aprendizaje automático a gran escala como AlphaGo AI de Google.
Asimismo, el procesador de red neuronal Nervana de Intel es un acelerador de IA diseñado para ofrecer un alto rendimiento para cargas de trabajo de aprendizaje profundo. El procesador presenta una arquitectura ASIC personalizada optimizada para redes neuronales, adoptada por empresas como Facebook, Alibaba y Tencent.
El acelerador de IA del motor de procesamiento neuronal Snapdragon de Qualcomm está diseñado para su uso en dispositivos móviles y otras aplicaciones informáticas de vanguardia. Cuenta con un diseño de hardware personalizado optimizado para cargas de trabajo de aprendizaje automático y puede ofrecer hasta 3 terflops de rendimiento, lo que lo hace adecuado para tareas de inferencia de IA en el dispositivo.
Varias otras empresas ya han invertido mucho en el desarrollo y producción de procesadores neuronales, que también se están adaptando al mercado, en una variedad de industrias. A medida que la IA, las redes neuronales y el aprendizaje automático se generalicen, se espera que el mercado de procesadores neuronales siga creciendo.
En resumen, el futuro de los procesadores neuronales en el mercado es brillante, aunque muchos factores pueden afectar su crecimiento y desarrollo, incluidos nuevos desarrollos tecnológicos, regulaciones gubernamentales e incluso las preferencias de los clientes.
Este artículo se basa en una entrevista con el director de marketing de BrainChip, Nandan Nayampally, y fue transcrito y curado por Jay Soni, un entusiasta de la electrónica de EFY.
Nandan Nayampally es director de marketing de BrainChip
[ad_2]