
[ad_1]
Los modelos de lenguajes grandes (LLM) han captado la imaginación y la atención de desarrolladores, científicos, tecnólogos, emprendedores y ejecutivos de diversas industrias. Estos modelos se pueden utilizar para responder preguntas, resúmenes, traducciones y más en aplicaciones como agentes conversacionales para atención al cliente, creación de contenido para marketing y asistentes de codificación.
Recientemente, Meta lanzó Llama 2 tanto para investigadores como para empresas comerciales, uniéndose a la lista de otros LLM, incluidos MosaicML MPT y Falcon. En esta publicación, aprenderá cómo optimizar Llama 2 en AWS Trainium, un acelerador diseñado específicamente para la capacitación LLM, para reducir el tiempo y los costos de capacitación. Revisamos los scripts de ajuste proporcionados por AWS Neuron SDK (usando NeMo Megatron-LM), las diversas configuraciones que utilizamos y los resultados de rendimiento que vimos.
Sobre el modelo Llama 2
Al igual que su predecesor Llama 1 y otros modelos como GPT, Llama 2 utiliza la arquitectura decodificadora pura del Transformer. Viene en tres tamaños: 7 mil millones, 13 mil millones y 70 mil millones de parámetros. En comparación con Llama 1, Llama 2 duplica la longitud del contexto de 2000 a 4000 y utiliza atención de consultas agrupadas (solo para 70B). Los modelos preentrenados de Llama 2 se entrenaron con 2 billones de tokens y los modelos ajustados se entrenaron con más de 1 millón de anotaciones humanas.
Entrenamiento distribuido de Llama 2
Para admitir Llama 2 con longitudes de secuencia de 2000 y 4000, implementamos el script usando NeMo Megatron para Trainium, que admite paralelismo de datos (DP), paralelismo tensorial (TP) y paralelismo de canalización (PP). Más específicamente, con la nueva implementación de algunas funciones como Untie Word Embedding, Rotary Embedding, RMSNorm y activación Swiglu, utilizamos el script genérico GPT Neuron Megatron-LM para respaldar el script de entrenamiento de Llama 2.
Nuestro procedimiento de capacitación de alto nivel es el siguiente: Para nuestro entorno de capacitación, utilizamos un clúster de múltiples instancias administrado por el sistema distribuido de programación y capacitación SLURM bajo el marco NeMo.
Primero, descargue el modelo Llama 2 y los conjuntos de datos de entrenamiento y procéselos usando el tokenizador Llama 2. Por ejemplo, para utilizar el conjunto de datos RedPajama, utilice el siguiente comando:
Para obtener instrucciones detalladas sobre la descarga de modelos y el preprocesamiento de argumentos de script, consulte Descargar el conjunto de datos y el tokenizador de LlamaV2.
A continuación, compila el modelo:
Después de compilar el modelo, comience el trabajo de entrenamiento con el siguiente script, ya optimizado con la mejor configuración e hiperparámetros para Llama 2 (incluido en el código de muestra):
Finalmente, monitoreamos TensorBoard para seguir el progreso del entrenamiento:
Para obtener el código de muestra completo y los scripts que mencionamos, consulte el tutorial de Llama 7B y el código NeMo en Neuron SDK para seguir pasos más detallados.
Experimentos de ajuste
Refinamos el modelo 7B utilizando los conjuntos de datos OSCAR (Open Super-large Crawled ALMAnaCH corpus) y QNLI (NLI de respuesta a preguntas) en un entorno Neuron 2.12 (PyTorch). Para cada longitud de secuencia de 2000 y 4000, optimizamos algunas configuraciones, como: batchsize Y gradient_accumulation, para la eficiencia del entrenamiento. Como estrategia de ajuste, adoptamos un ajuste completo de todos los parámetros (alrededor de 500 pasos), que se puede extender al entrenamiento previo con pasos más largos y conjuntos de datos más grandes (por ejemplo, 1T RedPajama). También se puede habilitar el paralelismo de secuencia para que NeMo Megatron pueda optimizar con éxito modelos con una longitud de secuencia más larga de 4000. La siguiente tabla muestra los resultados de configuración y rendimiento del experimento de ajuste fino de Llama 7B. El rendimiento aumenta casi linealmente a medida que el número de instancias aumenta hasta 4.
| Biblioteca distribuida | Registros | Longitud de la secuencia | Número de instancias | Tensor paralelo | Paralelo de datos | Tubería paralela | Tamaño de lote global | Rendimiento (seq/s) |
| Neurona NeMo Megatrón | Óscar | 4096 | 1 | octavo | 4 | 1 | 256 | 3.7 |
| . | . | 4096 | 2 | octavo | 4 | 1 | 256 | 7.4 |
| . | . | 4096 | 4 | octavo | 4 | 1 | 256 | 14.6 |
| . | QNLI | 4096 | 4 | octavo | 4 | 1 | 256 | 14.1 |
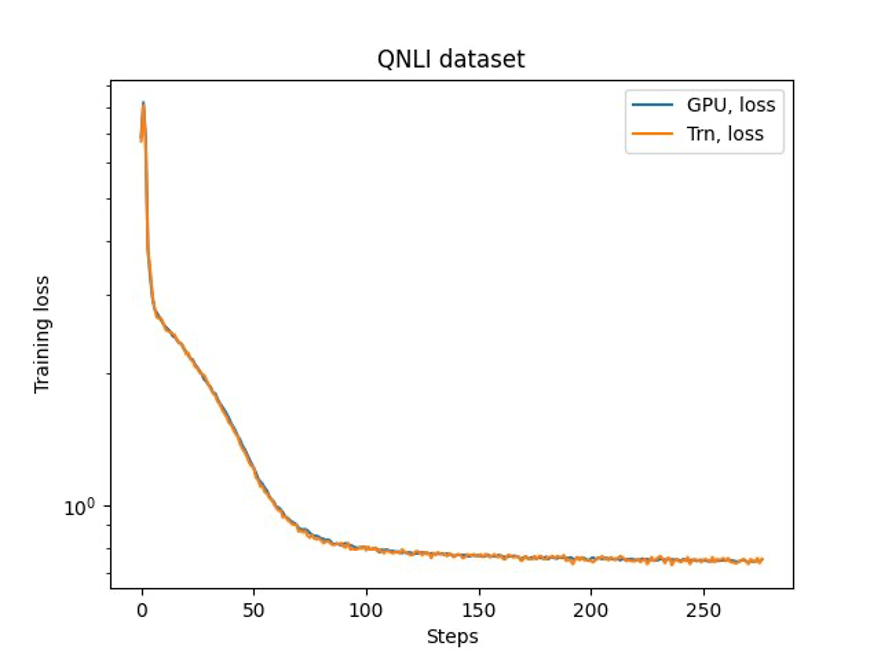
El último paso es comprobar la precisión con el modelo base. Implementamos un script de referencia para experimentos de GPU y confirmamos que las curvas de entrenamiento para GPU y Trainium son consistentes, como se muestra en la siguiente figura. La figura muestra curvas de pérdida sobre la cantidad de pasos de entrenamiento en el conjunto de datos QNLI. Se adoptó precisión mixta para GPU (azul) y bf16 con redondeo estocástico estándar para Trainium (naranja).
Diploma
En esta publicación hemos demostrado que Trainium ofrece un alto rendimiento y un ajuste rentable de Llama 2. Para obtener recursos adicionales sobre el uso de Trainium para el entrenamiento previo distribuido y el ajuste de sus modelos de IA generativa con NeMo Megatron, consulte AWS Neuron Reference para NeMo Megatron.
Sobre los autores
 Hao Zhou es científico investigador en Amazon SageMaker. Anteriormente, trabajó en el desarrollo de métodos de aprendizaje automático para la detección de fraudes para Amazon Fraud Detector. Le apasiona aplicar técnicas de aprendizaje automático, optimización e inteligencia artificial generativa a diversos problemas del mundo real. Tiene un doctorado en ingeniería eléctrica de la Universidad Northwestern.
Hao Zhou es científico investigador en Amazon SageMaker. Anteriormente, trabajó en el desarrollo de métodos de aprendizaje automático para la detección de fraudes para Amazon Fraud Detector. Le apasiona aplicar técnicas de aprendizaje automático, optimización e inteligencia artificial generativa a diversos problemas del mundo real. Tiene un doctorado en ingeniería eléctrica de la Universidad Northwestern.
 Karthick Gopalswamy es un científico aplicado en AWS. Antes de AWS, trabajó como científico en Uber y Walmart Labs centrándose en la optimización de enteros mixtos. En Uber, se centró en optimizar la red de transporte público con productos SaaS bajo demanda y viajes compartidos. En Walmart Labs, trabajó en optimizaciones de precios y empaques. Karthick tiene un doctorado en ingeniería industrial y de sistemas con especialización en investigación de operaciones de la Universidad Estatal de Carolina del Norte. Su investigación se centra en modelos y métodos que combinan investigación de operaciones y aprendizaje automático.
Karthick Gopalswamy es un científico aplicado en AWS. Antes de AWS, trabajó como científico en Uber y Walmart Labs centrándose en la optimización de enteros mixtos. En Uber, se centró en optimizar la red de transporte público con productos SaaS bajo demanda y viajes compartidos. En Walmart Labs, trabajó en optimizaciones de precios y empaques. Karthick tiene un doctorado en ingeniería industrial y de sistemas con especialización en investigación de operaciones de la Universidad Estatal de Carolina del Norte. Su investigación se centra en modelos y métodos que combinan investigación de operaciones y aprendizaje automático.
 Xin Huang es científico aplicado senior de Amazon SageMaker JumpStart y los algoritmos integrados en Amazon SageMaker. Su atención se centra en el desarrollo de algoritmos escalables de aprendizaje automático. Sus intereses de investigación incluyen el procesamiento del lenguaje natural, el aprendizaje profundo explicable sobre datos tabulares y el análisis sólido de agrupaciones espacio-temporales no paramétricas. Ha publicado numerosos artículos en conferencias ACL, ICDM y KDD y en la Royal Statistical Society Serie A.
Xin Huang es científico aplicado senior de Amazon SageMaker JumpStart y los algoritmos integrados en Amazon SageMaker. Su atención se centra en el desarrollo de algoritmos escalables de aprendizaje automático. Sus intereses de investigación incluyen el procesamiento del lenguaje natural, el aprendizaje profundo explicable sobre datos tabulares y el análisis sólido de agrupaciones espacio-temporales no paramétricas. Ha publicado numerosos artículos en conferencias ACL, ICDM y KDD y en la Royal Statistical Society Serie A.
 Parque Youngsuk es científico aplicado senior en AWS Annapurna Labs y trabaja en el desarrollo y capacitación de modelos fundamentales para aceleradores de IA. Anteriormente, la Dra. Park como científico senior de investigación y desarrollo para Amazon Forecast en los laboratorios de IA de AWS. Su investigación radica en la interacción entre aprendizaje automático, modelos fundamentales, optimización y aprendizaje por refuerzo. Ha publicado más de 20 artículos revisados por pares en lugares líderes como ICLR, ICML, AISTATS y KDD, organizando talleres y presentando tutoriales en el campo de series temporales y formación LLM. Antes de unirse a AWS, obtuvo un doctorado en ingeniería eléctrica de la Universidad de Stanford.
Parque Youngsuk es científico aplicado senior en AWS Annapurna Labs y trabaja en el desarrollo y capacitación de modelos fundamentales para aceleradores de IA. Anteriormente, la Dra. Park como científico senior de investigación y desarrollo para Amazon Forecast en los laboratorios de IA de AWS. Su investigación radica en la interacción entre aprendizaje automático, modelos fundamentales, optimización y aprendizaje por refuerzo. Ha publicado más de 20 artículos revisados por pares en lugares líderes como ICLR, ICML, AISTATS y KDD, organizando talleres y presentando tutoriales en el campo de series temporales y formación LLM. Antes de unirse a AWS, obtuvo un doctorado en ingeniería eléctrica de la Universidad de Stanford.
 Yida Wang es un científico senior del equipo de IA de AWS de Amazon. Sus intereses de investigación incluyen sistemas, computación de alto rendimiento y análisis de big data. Actualmente trabaja en sistemas de aprendizaje profundo, centrándose en componer y optimizar modelos de aprendizaje profundo para un entrenamiento e inferencia eficientes, particularmente en modelos de referencia a gran escala. La misión es unir los modelos de alto nivel de varios marcos y plataformas de hardware de bajo nivel, incluidas CPU, GPU y aceleradores de IA, para que diferentes modelos puedan ejecutarse en diferentes dispositivos con alto rendimiento.
Yida Wang es un científico senior del equipo de IA de AWS de Amazon. Sus intereses de investigación incluyen sistemas, computación de alto rendimiento y análisis de big data. Actualmente trabaja en sistemas de aprendizaje profundo, centrándose en componer y optimizar modelos de aprendizaje profundo para un entrenamiento e inferencia eficientes, particularmente en modelos de referencia a gran escala. La misión es unir los modelos de alto nivel de varios marcos y plataformas de hardware de bajo nivel, incluidas CPU, GPU y aceleradores de IA, para que diferentes modelos puedan ejecutarse en diferentes dispositivos con alto rendimiento.
 Jun (Lucas) Huan es un científico senior en AWS AI Labs. Dr. Huan participa en la inteligencia artificial y la ciencia de datos. Ha publicado más de 160 artículos revisados por pares en importantes congresos y revistas y ha obtenido 11 títulos de doctorado. Recibió el Premio al Desarrollo Profesional Temprano de la Facultad de la NSF en 2009. Antes de unirse a AWS, trabajó en Baidu Research como científico distinguido y director del Laboratorio de Big Data de Baidu. Fundó StylingAI Inc., una nueva empresa de inteligencia artificial, y se desempeñó como director ejecutivo y científico jefe de 2019 a 2021. Antes de ingresar a la industria, fue profesor Charles E. y Mary Jane Spahr en el Departamento EECS de la Universidad de Kansas. De 2015 a 2018 fue director de programa de la NSF de EE. UU., responsable de su programa de big data.
Jun (Lucas) Huan es un científico senior en AWS AI Labs. Dr. Huan participa en la inteligencia artificial y la ciencia de datos. Ha publicado más de 160 artículos revisados por pares en importantes congresos y revistas y ha obtenido 11 títulos de doctorado. Recibió el Premio al Desarrollo Profesional Temprano de la Facultad de la NSF en 2009. Antes de unirse a AWS, trabajó en Baidu Research como científico distinguido y director del Laboratorio de Big Data de Baidu. Fundó StylingAI Inc., una nueva empresa de inteligencia artificial, y se desempeñó como director ejecutivo y científico jefe de 2019 a 2021. Antes de ingresar a la industria, fue profesor Charles E. y Mary Jane Spahr en el Departamento EECS de la Universidad de Kansas. De 2015 a 2018 fue director de programa de la NSF de EE. UU., responsable de su programa de big data.
 Sruti Koparkar es gerente senior de marketing de productos en AWS. Ayuda a los clientes a explorar, evaluar y adoptar la infraestructura informática acelerada de Amazon EC2 para sus necesidades de aprendizaje automático.
Sruti Koparkar es gerente senior de marketing de productos en AWS. Ayuda a los clientes a explorar, evaluar y adoptar la infraestructura informática acelerada de Amazon EC2 para sus necesidades de aprendizaje automático.
[ad_2]