[ad_1]
La clasificación es un tema central en una variedad de áreas, tales como B. motores de búsqueda, sistemas de recomendación o respuesta a consultas. Como tal, los investigadores a menudo usan Learning-to-Rank (LTR), un conjunto de técnicas de aprendizaje automático supervisado que están optimizadas para el beneficio de un lista completa de artículos (en lugar de un solo artículo a la vez). Un nuevo enfoque notable es combinar LTR con aprendizaje profundo. Las bibliotecas existentes, especialmente TF Ranking, brindan a los investigadores y profesionales las herramientas necesarias para usar LTR en su trabajo. Sin embargo, ninguna de las bibliotecas LTR existentes funciona de forma nativa con JAX, un nuevo marco de aprendizaje automático que proporciona un sistema extensible de transformaciones de funciones que incluyen: diferenciación automática, compilación JIT para dispositivos GPU/TPU y más.
Hoy nos complace presentar Rax, una biblioteca para LTR en el ecosistema JAX. Rax trae décadas de investigación LTR al ecosistema JAX, lo que hace posible aplicar JAX a una variedad de problemas de clasificación y combinar técnicas de clasificación con avances recientes en aprendizaje profundo construido sobre JAX (por ejemplo, T5X). Rax ofrece pérdida de clasificación de última generación, un conjunto de métricas de clasificación estándar y un conjunto de transformaciones de características para permitir la optimización de métricas de clasificación. Toda esta funcionalidad se proporciona con una API bien documentada y fácil de usar que se verá y se sentirá familiar para los usuarios de JAX. Puede encontrar más detalles técnicos en nuestro documento.
Aprende a clasificar con Rax
Rax está diseñado para resolver problemas de LTR. Para este propósito, Rax proporciona funciones de pérdida y métricas que funcionan en lotes de lizano lotes de puntos de datos individuales como es común en otros problemas de aprendizaje automático. Un ejemplo de dicha lista son los múltiples resultados potenciales de una consulta de motor de búsqueda. La siguiente figura ilustra cómo se pueden usar las herramientas de Rax para entrenar redes neuronales para tareas de clasificación. En este ejemplo, los elementos verdes (B, F) son muy relevantes, los elementos amarillos (C, E) bastante relevantes y los elementos rojos (A, D) no relevantes. Se utiliza una red neuronal para predecir un puntaje de relevancia para cada elemento, y estos elementos luego se ordenan por esos puntajes para crear una clasificación. Una pérdida de clasificación de Rax involucra la lista completa de resultados para optimizar la red neuronal y mejorar la clasificación general de los elementos. Después de varias iteraciones del descenso del gradiente estocástico, la red neuronal aprende a clasificar los elementos de tal manera que la clasificación resultante sea óptima: los elementos relevantes se colocan en la parte superior de la lista y los elementos irrelevantes se colocan en la parte inferior.
 |
| Uso de Rax para optimizar una red neuronal para una tarea de clasificación. Los elementos verdes (B, F) son muy relevantes, los elementos amarillos (C, E) bastante relevantes y los elementos rojos (A, D) no relevantes. |
Optimización métrica aproximada
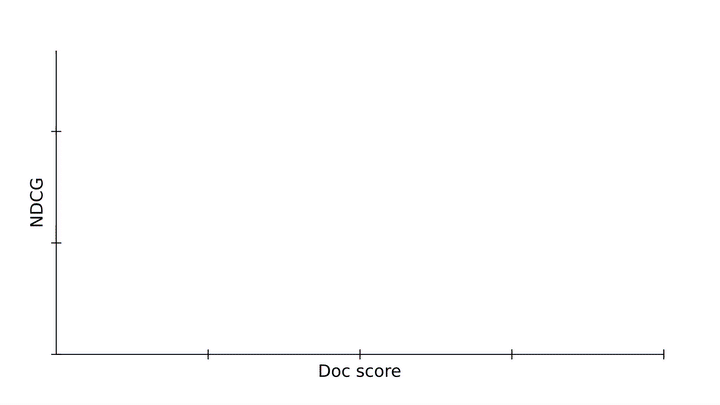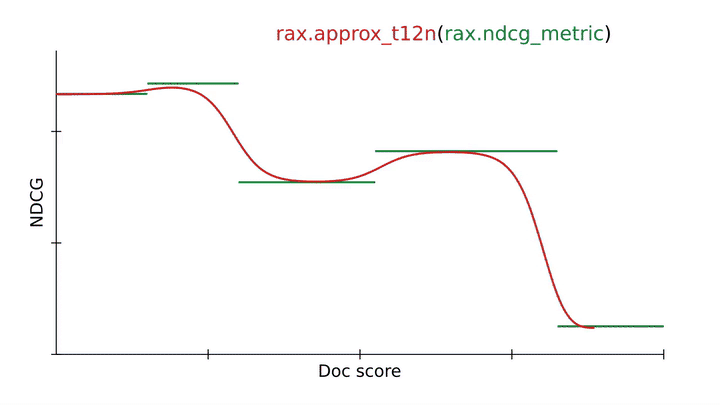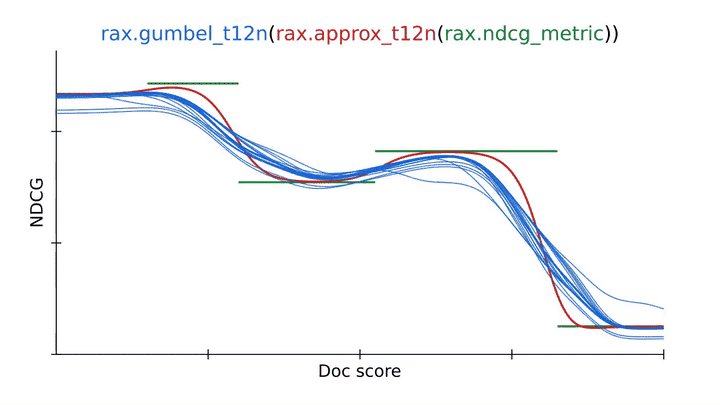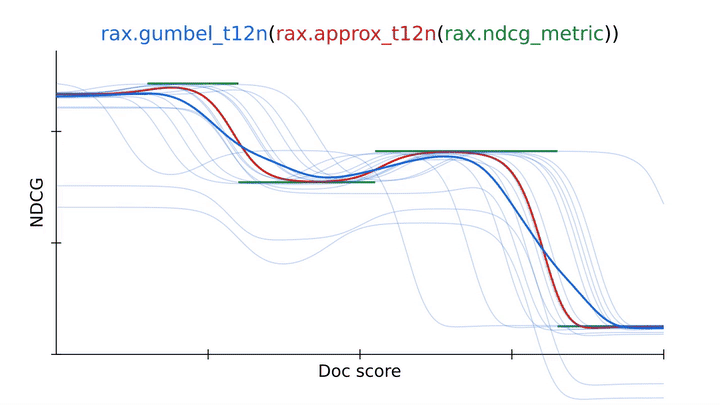
La calidad de una clasificación se evalúa comúnmente utilizando métricas de clasificación, p. B. Ganancia acumulada descontada normalizada (NDCG). Un objetivo clave de LTR es optimizar una red neuronal para que funcione bien en las métricas de clasificación. Sin embargo, las métricas de clasificación como NDCG pueden presentar desafíos, ya que a menudo son discontinuas y planas, por lo que el descenso de gradiente estocástico no se puede aplicar directamente a estas métricas. Rax proporciona técnicas de aproximación de última generación que permiten crear sustitutos diferenciables para métricas de clasificación que permiten la optimización a través del descenso de gradiente. La siguiente imagen ilustra el uso de rax.approx_t12nuna transformación de función exclusiva de Rax que permite transformar la métrica NDCG en una forma aproximada y diferenciable.
 |
Usando una técnica de aproximación de Rax para transformar la métrica de clasificación NDCG en una pérdida de clasificación diferenciable y ajustable (approx_t12n y gumbel_t12n). |
En primer lugar, tenga en cuenta que la métrica NDCG (en verde) es plana y discontinua, lo que dificulta la optimización con descenso de gradiente estocástico. Al aplicar el rax.approx_t12n Transformando a la métrica obtenemos ApproxNDCG, una métrica de aproximación que ahora es diferenciable con gradientes bien definidos (en rojo). Sin embargo, puede tener muchos óptimos locales (puntos en los que la pérdida es localmente óptima pero no globalmente óptima) en los que el proceso de entrenamiento puede atascarse. Cuando la pérdida alcanza un óptimo local, los métodos de entrenamiento como el descenso de gradiente estocástico luchan por mejorar aún más la red neuronal.
Para evitar esto, podemos obtener la versión gumbel de ApproxNDCG usando el rax.gumbel_t12n Transformación. Esta versión de Gumbel introduce ruido en las puntuaciones de clasificación, lo que provoca la pérdida de muestras de muchas clasificaciones diferentes que pueden incurrir en costos distintos de cero (en azul). Este tratamiento estocástico puede ayudar a que la pérdida escape a los óptimos locales y, a menudo, es una mejor opción cuando se entrena una red neuronal en una métrica de clasificación. Por diseño, Rax permite el uso gratuito de las transformaciones de Aproximación y Gumbel con cualquier métrica que ofrezca la biblioteca, incluidas las métricas con un valor de corte k superior, como recuperación o precisión. De hecho, incluso es posible implementar sus propias métricas y transformarlas para obtener versiones aproximadas de Gumbel que permitan la optimización sin ningún esfuerzo adicional.
Ranking en el ecosistema JAX
Rax está diseñado para integrarse bien con el ecosistema JAX y damos prioridad a la interoperabilidad con otras bibliotecas basadas en JAX. Por ejemplo, un flujo de trabajo común para los investigadores que usan JAX es usar conjuntos de datos de TensorFlow para cargar un conjunto de datos, Flax para construir una red neuronal y Optax para ajustar los parámetros de la red. Cada una de estas bibliotecas se combina bien con las demás, y la composición de estas herramientas hace que trabajar con JAX sea flexible y potente. Para los investigadores y profesionales de los sistemas de clasificación, el ecosistema JAX anteriormente carecía de la funcionalidad LTR, y Rax llena este vacío al proporcionar una colección de métricas y pérdidas de clasificación. Diseñamos cuidadosamente Rax para que funcione de forma nativa con transformaciones JAX estándar como jax.jit y jax.grad y varias bibliotecas como Flax y Optax. Esto significa que los usuarios pueden usar sus herramientas JAX y Rax favoritas juntas.
Clasificación con T5
Si bien los modelos de lenguaje gigante como T5 han mostrado un rendimiento excelente en tareas de lenguaje natural, aún no se ha explorado cómo se pueden usar las fugas de clasificación para mejorar su rendimiento en tareas de clasificación como búsqueda o respuesta a preguntas. Con Rax es posible explotar al máximo este potencial. Rax está escrito como una primera biblioteca JAX, por lo que es fácil de integrar con otras bibliotecas JAX. Debido a que T5X es una implementación de T5 en el ecosistema JAX, Rax puede funcionar sin problemas con él.
Con ese fin, tenemos un ejemplo que muestra cómo se puede usar Rax en T5X. Al incluir caídas de clasificación y métricas, ahora es posible optimizar T5 para problemas de clasificación, y nuestros resultados muestran que mejorar T5 con caídas de clasificación puede ofrecer mejoras significativas en el rendimiento. Por ejemplo, en el punto de referencia MS-MARCO QNA v2.1, podemos lograr +1.2 % NDCG y +1.7 % MRR al ejecutar un modelo base T5 usando la pérdida de entropía cruzada Rax softmax listada en lugar de una escala fina punto por punto. el ajuste optimiza la pérdida de entropía cruzada sigmoidal.
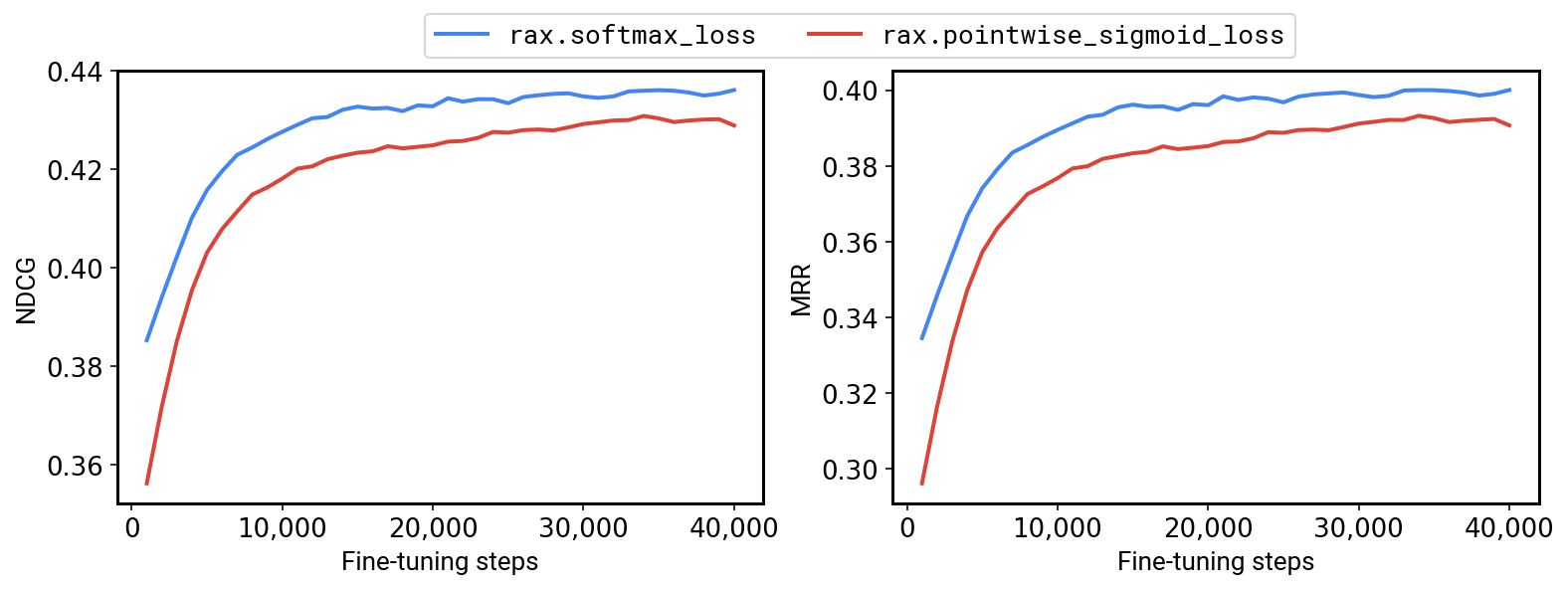 |
| Ajuste fino de un modelo base T5 en MS-MARCO QNA v2.1 con una pérdida de clasificación (softmax, en azul) frente a una pérdida sin clasificación (punto sigmoideo, en rojo). |
Conclusión
En general, Rax es una nueva incorporación al creciente ecosistema de bibliotecas JAX. Rax es completamente de código abierto y está disponible para todos en github.com/google/rax. También se pueden encontrar más detalles técnicos en nuestro documento. Alentamos a todos a explorar los ejemplos incluidos en el repositorio de Github: (1) optimizar una red neuronal con Flax y Optax, (2) comparar varias técnicas de optimización de métricas aproximadas y (3) cómo integrar Rax con T5X.
Gracias
Muchos empleados de Google han hecho posible este proyecto: Xuanhui Wang, Zhen Qin, Le Yan, Rama Kumar Pasumarthi, Michael Bendersky, Marc Najork, Fernando Diaz, Ryan Doherty, Afroz Mohiuddin y Samer Hassan.
[ad_2]