[ad_1]
Un problema de larga data en la interfaz de la visión por computadora y los gráficos por computadora es la síntesis de vista, la tarea de crear nuevas vistas de una escena a partir de múltiples imágenes de esa escena. Esto está recibiendo una mayor atención. [1, 2, 3] desde la introducción de los campos de radiación neural (NeRF). El problema es desafiante porque para sintetizar con precisión nuevas vistas de una escena, un modelo debe capturar muchos tipos de información (su estructura 3D detallada, materiales e iluminación) a partir de un pequeño conjunto de imágenes de referencia.
En esta publicación, presentamos modelos de aprendizaje profundo publicados recientemente para la síntesis de vistas. En Light Field Neural Rendering (LFNR), presentado en CVPR 2022, nos desafiamos a nosotros mismos a reproducir con precisión los efectos dependientes de la vista mediante el uso de transformadores que aprenden a combinar colores de píxeles de referencia. Luego, en Generalizable Patch-Based Neural Rendering (GPNR), que se presentará en ECCV 2022, abordamos el desafío de generalizar a escenas no vistas utilizando una secuencia de transformadores con codificación posicional canonicalizada, asignada a una serie Entrenada a partir de escenas que pueden sintetizar vistas de nuevas escenas Estos modelos tienen algunas características únicas. Realizan una renderización basada en imágenes, combinando colores y características de las imágenes de referencia para renderizar vistas novedosas. Se basan exclusivamente en transformadores, funcionan con conjuntos de fotogramas y utilizan una representación de campo de luz 4D para la codificación de posición que ayuda a modelar los efectos dependientes de la vista.
 |
 |
| Entrenamos modelos de aprendizaje profundo que pueden generar nuevas vistas de una escena a partir de unas pocas imágenes. Estos modelos son particularmente efectivos para tratar los efectos dependientes de la vista, como la refracción y la transmisión de luz en los tubos de ensayo. Esta animación está comprimida; Vea las representaciones de calidad original aquí. Fuente: Escena de laboratorio del conjunto de datos NeX/Shiny. |
visión general
La entrada para los modelos consiste en un conjunto de imágenes de referencia y sus parámetros de cámara (distancia focal, posición y orientación en el espacio) así como las coordenadas del haz de referencia cuyo color queremos determinar. Para generar una nueva imagen, tomamos los parámetros de la cámara de las imágenes de entrada, obtenemos las coordenadas de los rayos de puntería (cada uno correspondiente a un píxel) y consultamos el modelo para cada uno.
En lugar de procesar completamente cada imagen de referencia, solo observamos las áreas que probablemente afecten al píxel de destino. Estas áreas se determinan a través de la geometría epipolar que asigna cada píxel de destino a una línea en cada cuadro de referencia. Para robustez, tomamos pequeñas regiones alrededor de una serie de puntos en la línea epipolar, lo que da como resultado el conjunto de parches realmente procesados por el modelo. Luego, los transformadores actúan sobre este conjunto de parches para obtener el color del píxel objetivo.
Los transformadores son particularmente útiles en este entorno porque su mecanismo de autoconciencia toma oraciones como entradas de forma natural, y los pesos de atención se pueden usar para combinar colores de vista de referencia y características para predecir los colores de píxeles de salida. Estos transformadores siguen la arquitectura introducida en ViT.
 |
| Para predecir el color de un píxel, los modelos utilizan una serie de parches extraídos alrededor de la línea epipolar de cada vista de referencia. Fuente de la imagen: conjunto de datos LLFF. |
Representación neuronal en el campo de luz.
En Light Field Neural Rendering (LFNR), usamos una secuencia de dos transformadores para mapear el conjunto de parches al color del píxel de destino. El primer transformador agrega información a lo largo de cada línea epipolar y el segundo a lo largo de cada marco de referencia. Podemos interpretar el primer transformador como encontrar coincidencias potenciales del píxel de destino en cada marco de referencia, y el segundo como un razonamiento sobre la oclusión y los efectos dependientes de la vista que son desafíos comunes de la representación basada en imágenes.
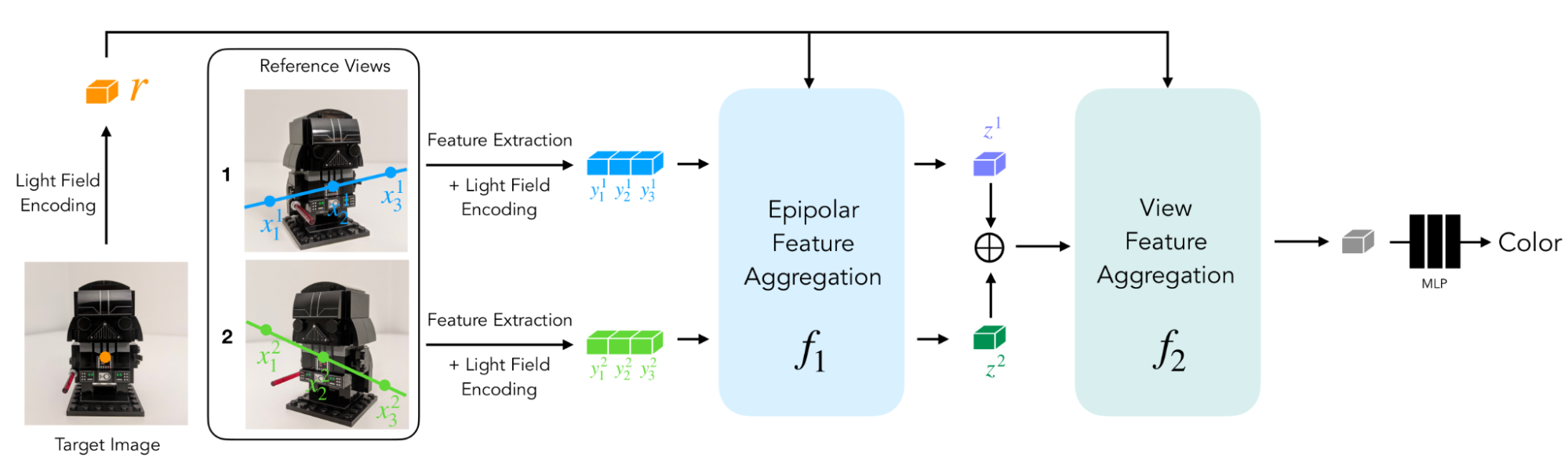 |
| LFNR usa una secuencia de dos transformadores para mapear una serie de parches extraídos a lo largo de líneas epipolares al color del píxel de destino. |
LFNR mejoró el estado del arte en los puntos de referencia de síntesis de vista más populares (Blender de NeRF y escenas reales orientadas hacia adelante y Shiny de NeX) con márgenes de hasta 5 dB de relación señal-ruido (PSNR) pico. Esto corresponde a una reducción del error píxel por píxel por un factor de 1,8x. Mostramos resultados cualitativos en escenas desafiantes del conjunto de datos Shiny a continuación:
 |
| LFNR reproduce sofisticados efectos dependientes de la vista, como el arcoíris y los reflejos en el CD, reflejos, refracciones y transmisión de luz en las botellas. Esta animación está comprimida; Vea las representaciones de calidad original aquí. Fuente: Escena de CD del conjunto de datos NeX/Shiny. |
 |
| Los métodos anteriores, como NeX y NeRF, no pueden reproducir los efectos dependientes de la vista, como la translucidez y las refracciones en los tubos de ensayo en la escena del laboratorio del conjunto de datos NeX/Shiny. También vea nuestro video de esta escena en la parte superior de la publicación y las ediciones originales de calidad aquí. |
Generalización a nuevas escenas.
Una limitación de LFNR es que el primer transformador colapsa la información a lo largo de cada línea epipolar de forma independiente para cada marco de referencia. Esto significa que decide qué información conservar basándose únicamente en las coordenadas de los rayos de salida y los parches de cada imagen de referencia, lo que funciona bien cuando se entrena en una sola escena (como lo hacen la mayoría de los métodos de renderizado neuronal), pero no se generaliza en todas las escenas. Los métodos generalizables son importantes porque se pueden aplicar a nuevas escenas sin volver a entrenar.
Superamos esta limitación de LFNR en la representación neuronal generalizable basada en parches (GPNR). Agregamos un transformador que corre delante de los otros dos e intercambia información entre puntos a la misma profundidad en todas las imágenes de referencia. Por ejemplo, este primer Transformer mira los pilares de parches del banco del parque que se muestra arriba y puede usar señales como la flor que aparece en dos vistas a las profundidades correspondientes, lo que indica una posible coincidencia. Otra idea clave de este trabajo es la canonización de la codificación de posición basada en el rayo de puntería, ya que para la generalización entre escenas es necesario representar las magnitudes en marcos de referencia relativos en lugar de absolutos. La siguiente animación muestra una descripción general del modelo.
 |
| GPNR consta de una secuencia de tres transformadores que asignan una serie de parches extraídos a lo largo de líneas epipolares a un color de píxel. Los parches de imagen se asignan a las características iniciales (representadas como cuadros azules y verdes) a través del plano de proyección lineal. Luego, estas características se refinan y agregan sucesivamente por el modelo, lo que da como resultado la característica/color final representado por el rectángulo gris. Fuente de la imagen del banco del parque: conjunto de datos LLFF. |
Para evaluar el rendimiento de la generalización, entrenamos GPNR en un conjunto de escenas y lo probamos en nuevas escenas. GPNR mejoró el estado del arte en varios puntos de referencia (según los protocolos IBRNet y MVSNeRF) en un promedio de 0,5 a 1,0 dB. En el punto de referencia de IBRNet, GPNR supera las líneas de base mientras usa solo el 11% de las escenas de entrenamiento. Los resultados a continuación muestran nuevas vistas de escenas invisibles renderizadas sin ajustes finos.
 |
| GPNR generó vistas de escenas sostenidas sin ningún ajuste fino. Esta animación está comprimida; Vea las representaciones de calidad original aquí. Fuente: Conjunto de datos recopilados por IBRNet. |
 |
| Detalles sobre llamadas generadas por GPNR a escenas retenidas de NeX/Shiny (Izquierda) y LLFF (A la derecha), sin ajuste fino. GPNR reproduce los detalles de la hoja y las refracciones a través de la lente con mayor precisión en comparación con IBRNet. |
Trabajo futuro
Una limitación de la mayoría de los métodos de representación neuronal, incluido el nuestro, es que requieren poses de cámara para cada imagen de entrada. Las poses no son fáciles de obtener y, por lo general, provienen de métodos de optimización fuera de línea, que pueden ser lentos y limitar las posibles aplicaciones, p. B. en dispositivos móviles. La investigación sobre el aprendizaje conjunto de la síntesis de la visión y las poses de entrada es una dirección futura prometedora. Otra limitación de nuestros modelos es que son computacionalmente costosos de entrenar. Existe una línea activa de investigación en transformadores más rápidos que podría ayudar a mejorar la eficiencia de nuestros modelos. Los documentos, los resultados adicionales y el código de fuente abierta se pueden encontrar en las páginas de proyectos de Representación neuronal de campo ligero y Representación neuronal basada en parches generalizables.
Posible abuso
En nuestra investigación, nuestro objetivo es reproducir con precisión una escena existente usando imágenes de esa escena, dejando poco espacio para la creación de escenas falsas o inexistentes. Nuestros modelos asumen escenas estáticas, por lo que sintetizar objetos en movimiento como personas no funcionará.
Gracias
Todo el trabajo duro fue realizado por nuestro increíble pasante, Mohammed Suhail, estudiante de doctorado en la UBC, en colaboración con Carlos Esteves y Ameesh Makadia de Google Research y Leonid Sigal de la UBC. Agradecemos a Corinna Cortés por apoyar y patrocinar este proyecto.
Nuestro trabajo está inspirado en NeRF, que ha despertado un interés reciente en la síntesis de vistas, e IBRNet, que primero consideró la generalización a nuevas escenas. Nuestra codificación de la posición del haz de luz está inspirada en el trabajo seminal Light Field Rendering y nuestro uso de transformadores sigue a ViT.
Los resultados del video provienen de escenas de conjuntos de datos recopilados por LLFF, Shiny e IBRNet.
[ad_2]