
[ad_1]
Se han logrado grandes avances en la adaptación de modelos de lenguaje grandes (LLM) para permitir la entrada multimodal para tareas como subtítulos, respuesta visual a preguntas (VQA) y reconocimiento de vocabulario abierto. A pesar de estos logros, los modelos de lenguaje visual (VLM) de última generación actuales se quedan cortos cuando se busca información visual en conjuntos de datos como Infoseek y OK-VQA, donde se requiere conocimiento externo para responder las preguntas.
 |
| Ejemplos de consultas de búsqueda de información visual que requieren conocimiento externo para responder la pregunta. Las imágenes provienen del conjunto de datos OK-VQA. |
En «AVIS: Búsqueda autónoma de información visual con modelos de lenguaje grandes» presentamos un método novedoso que logra resultados de última generación en tareas de búsqueda de información visual. Nuestro método integra LLM con tres tipos de herramientas: (i) herramientas de visión por computadora para extraer información visual de imágenes, (ii) una herramienta de búsqueda web para recuperar conocimientos y hechos del mundo abierto, y (iii) una herramienta de búsqueda de imágenes para recopilar información relevante a partir de metadatos asociados con imágenes visualmente similares. AVIS utiliza un planificador basado en LLM que selecciona herramientas y consultas en cada paso. También utiliza un razonamiento basado en LLM para analizar los resultados de la herramienta y extraer información importante. Un componente de memoria almacena información durante todo el proceso.
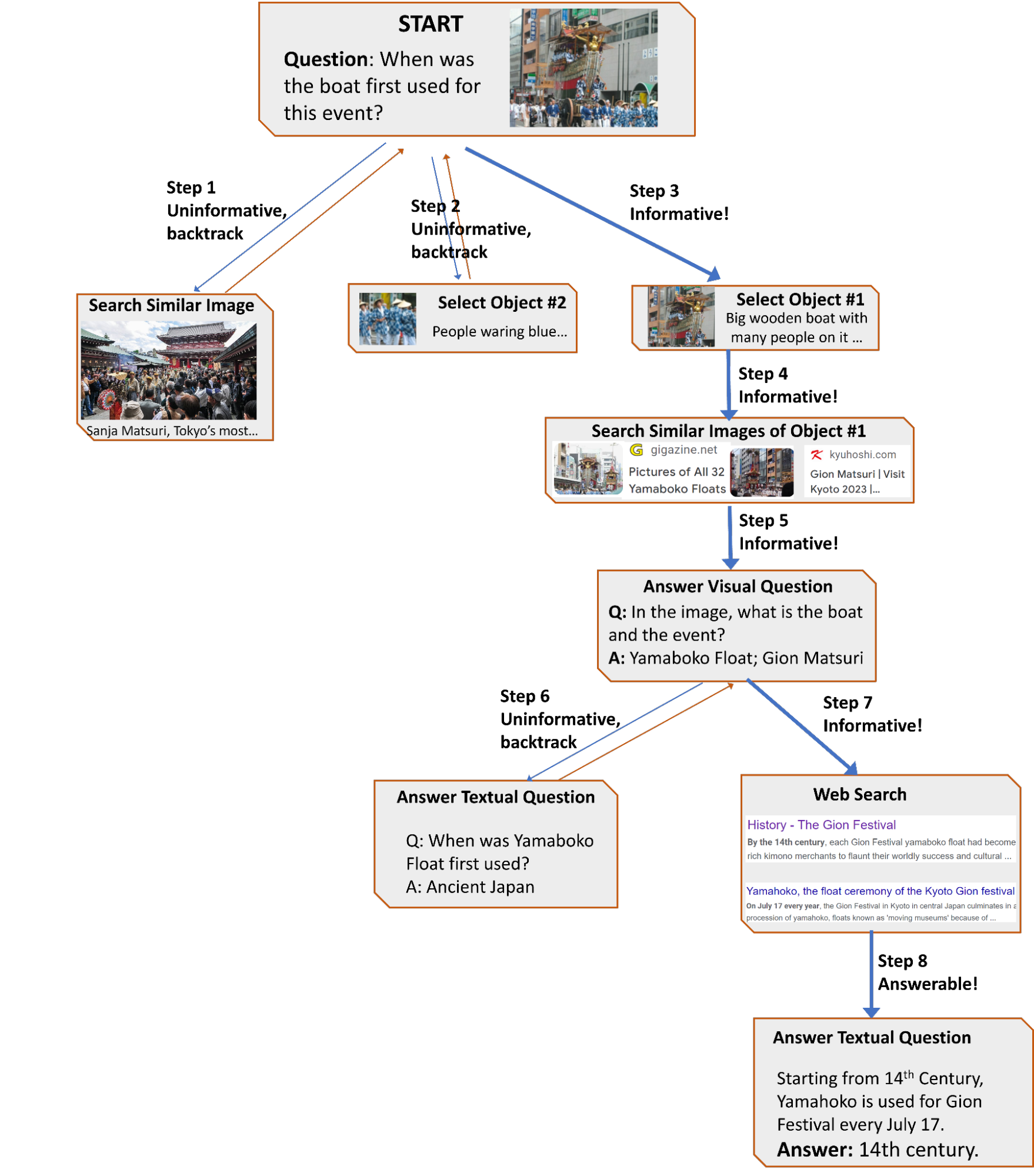 |
| Un ejemplo del flujo de trabajo generado por AVIS para responder una pregunta desafiante de búsqueda de información visual. La imagen de entrada proviene del conjunto de datos de Infoseek. |
Comparación con trabajos anteriores.
Estudios recientes (por ejemplo, Chameleon, ViperGPT y MM-ReAct) examinaron la adición de herramientas a los LLM para entradas multimodales. Estos sistemas siguen un proceso de dos pasos: planificación (dividir las preguntas en programas o instrucciones estructurados) y ejecución (utilizar herramientas para recopilar información). Aunque este enfoque tiene éxito en tareas básicas, a menudo falla en escenarios complejos del mundo real.
También ha habido un interés creciente en aplicar los LLM como agentes autónomos (por ejemplo, WebGPT y ReAct). Estos agentes interactúan con su entorno, se adaptan en función de la retroalimentación en tiempo real y logran objetivos. Sin embargo, estos métodos no limitan las herramientas que se pueden invocar en cada etapa, lo que genera un enorme espacio de búsqueda. Como resultado, incluso los LLM más avanzados de la actualidad pueden repetir o propagar errores. AVIS aborda este problema mediante un uso guiado de LLM que está influenciado por decisiones humanas a partir de un estudio de usuario.
Apoyar la toma de decisiones de LLM a través de un estudio de usuarios.
Muchas de las preguntas visuales en conjuntos de datos como Infoseek y OK-VQA son desafiantes incluso para los humanos y a menudo requieren el soporte de varias herramientas y API. A continuación se muestra una pregunta de muestra del conjunto de datos OK-VQA. Realizamos un estudio de usuarios para comprender la toma de decisiones humanas cuando utilizamos herramientas externas.
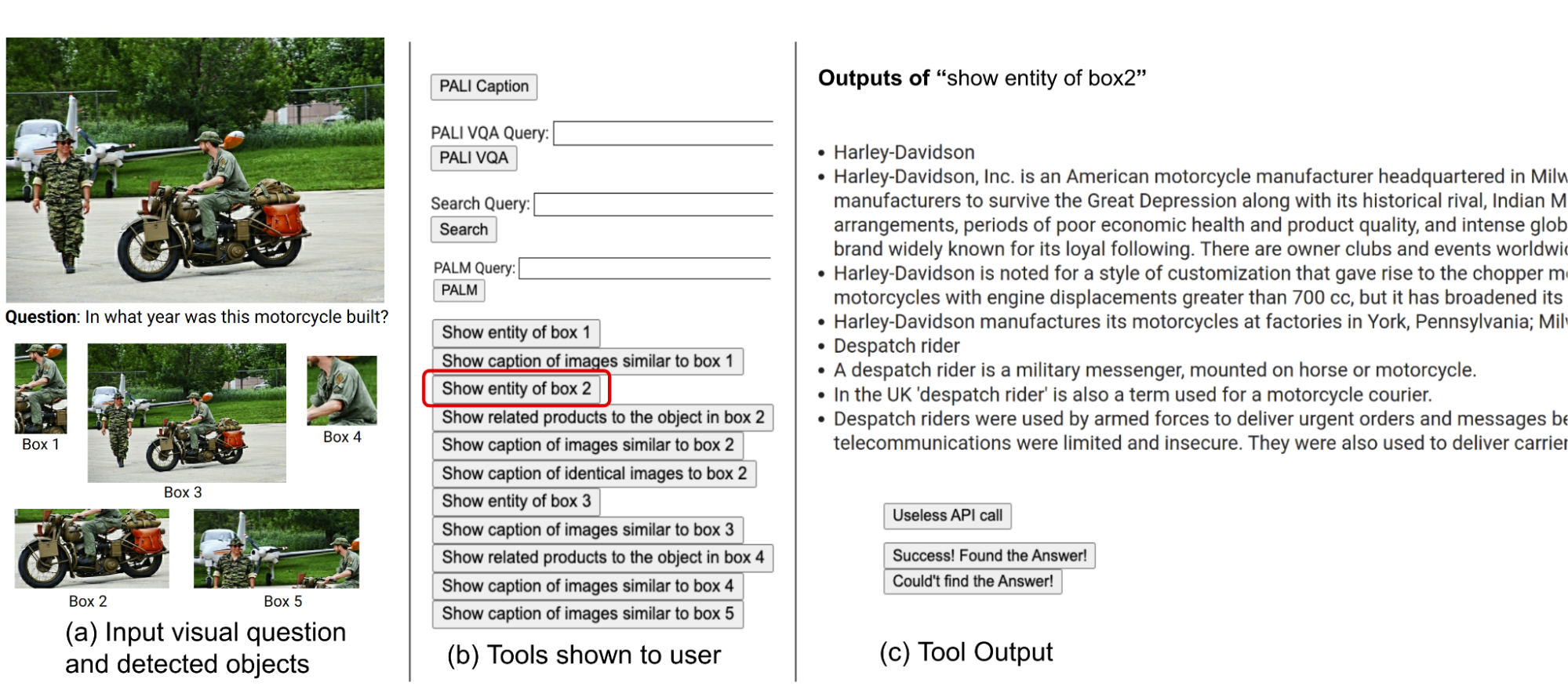 |
| Realizamos un estudio de usuarios para comprender la toma de decisiones humanas cuando utilizamos herramientas externas. La imagen proviene del conjunto de datos OK-VQA. |
Los usuarios disponían de herramientas idénticas a las de nuestro método, incluidas PALI, PaLM y búsqueda web. Recibieron imágenes de entrada, preguntas, recortes de objetos reconocidos y botones vinculados a resultados de búsqueda de imágenes. Estos botones ofrecían diversa información sobre los recortes de objetos detectados, como por ejemplo: B. Entidades de gráficos de conocimiento, títulos similares, títulos de productos relacionados y títulos idénticos.
Registramos las acciones y resultados de los usuarios y los utilizamos para guiar nuestro sistema de dos maneras importantes. Primero, creemos un diagrama de transición (ver más abajo) analizando el orden de las decisiones tomadas por los usuarios. Este diagrama define diferentes estados y restringe las acciones disponibles en cada estado. En el estado inicial, por ejemplo, el sistema sólo puede realizar una de estas tres acciones: etiquetado PALI, PALI VQA o reconocimiento de objetos. En segundo lugar, utilizamos ejemplos de toma de decisiones humanas para guiar a nuestro planificador y pensador con instancias relevantes de contexto, mejorando así el rendimiento y la eficacia de nuestro sistema.
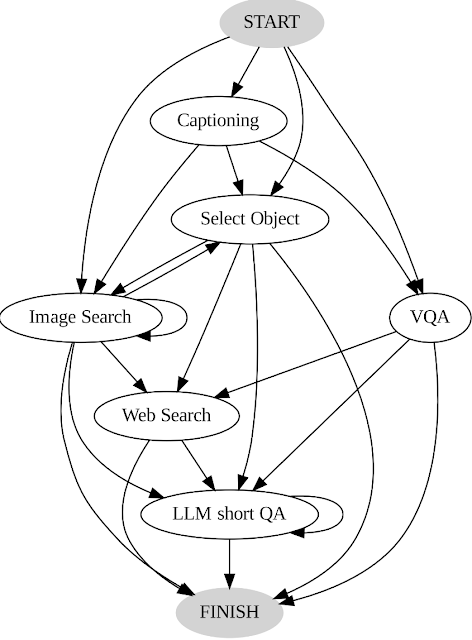 |
| Diagrama de transición AVIS. |
condiciones generales
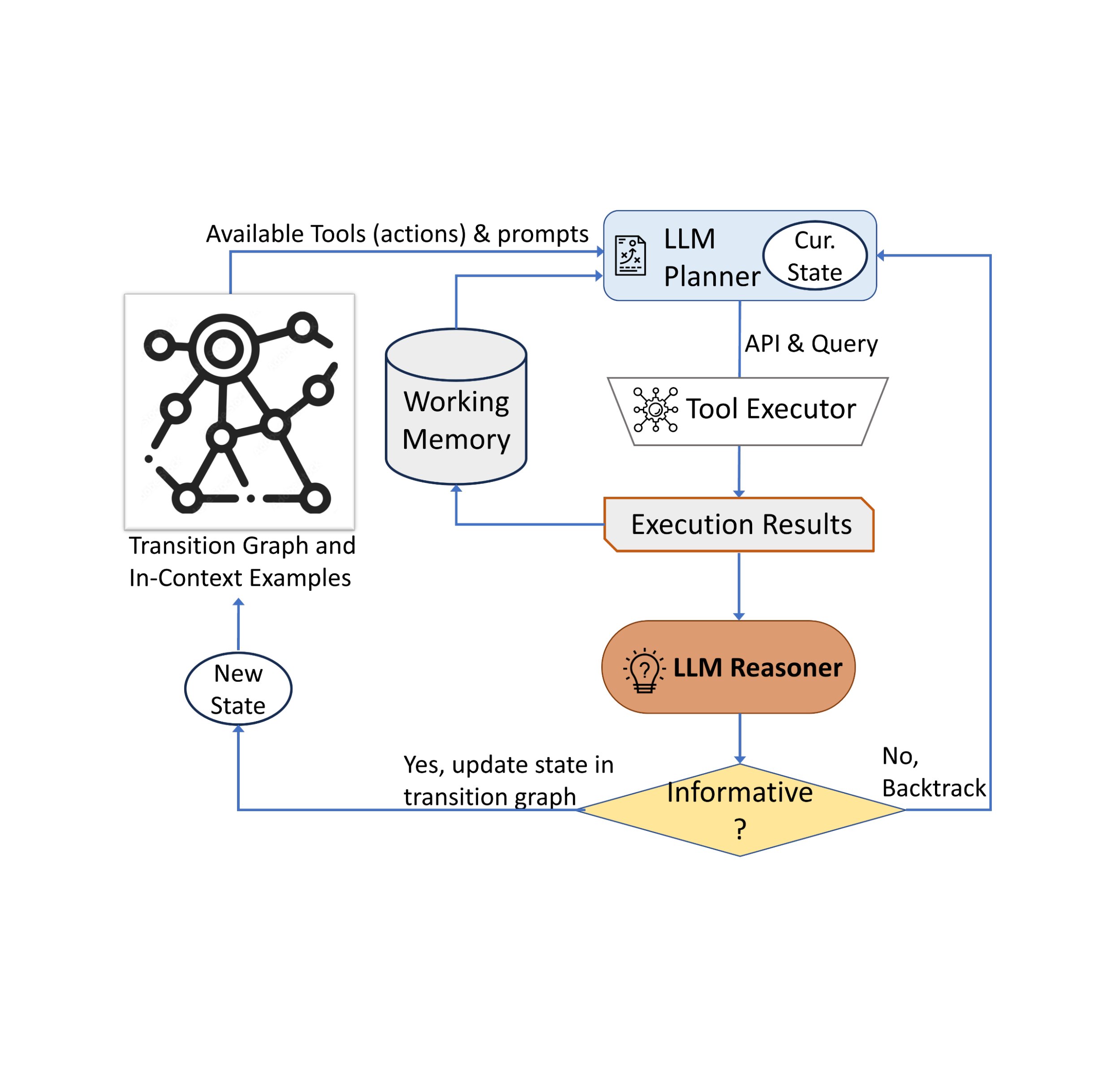
Nuestro enfoque se basa en una estrategia dinámica de toma de decisiones diseñada para responder a solicitudes visuales de información. Nuestro sistema consta de tres componentes principales. primero tenemos uno planificador para determinar la acción posterior, incluida la llamada API adecuada y la consulta a procesar. En segundo lugar, tenemos uno. memoria de trabajo que almacena información sobre los resultados de las ejecuciones de API. Por ultimo tenemos uno pensador, cuyo trabajo es procesar las salidas de las llamadas API. Determina si la información obtenida es suficiente para construir la respuesta final o si se requiere recuperación de datos adicionales.
El programador realiza una serie de pasos cada vez que es necesario tomar una decisión sobre qué herramienta implementar y qué solicitud enviar a la herramienta. Basándose en el estado actual, el planificador prevé una serie de posibles acciones de seguimiento. El espacio de acción potencial puede ser tan grande que hace que el espacio de búsqueda sea difícil de manejar. Para abordar este problema, el planificador se basa en el diagrama de transición para eliminar acciones irrelevantes. El planificador también excluye las acciones que ya se han realizado anteriormente y están almacenadas en la memoria.
A continuación, el planificador recopila un conjunto de ejemplos contextuales relevantes compilados a partir de las elecciones realizadas previamente por los humanos durante el estudio del usuario. Con estos ejemplos y la memoria de trabajo que almacena datos de interacciones pasadas con herramientas, el planificador formula un mensaje. Luego, el mensaje se envía al LLM, que devuelve una respuesta estructurada y determina la siguiente herramienta a activar y la solicitud a enviarle. Este diseño permite que el programador sea invocado varias veces durante el proceso, lo que permite una toma de decisiones dinámica que conduce progresivamente a responder la consulta de entrada.
Utilizamos un razonador para analizar el resultado de la ejecución de la herramienta, extraer la información útil y decidir en qué categoría cae el resultado de la herramienta: informativa, no informativa o respuesta definitiva. Nuestro método utiliza el LLM con indicaciones apropiadas y ejemplos contextuales para llevar a cabo el razonamiento. Cuando el razonador concluye que está listo para dar una respuesta, emite la respuesta final, completando así la tarea. Si descubre que el resultado de la herramienta no es significativo, regresa al programador para elegir una acción diferente según el estado actual. Si la salida de la herramienta es útil, cambia de estado y transfiere el control nuevamente al planificador para tomar una nueva decisión en el nuevo estado.
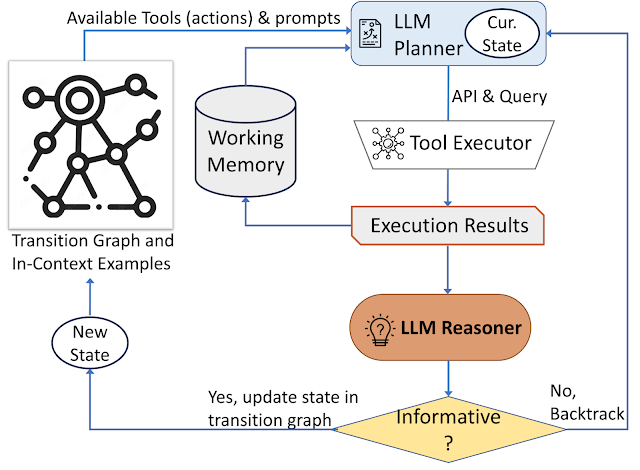 |
| AVIS utiliza una estrategia dinámica de toma de decisiones para responder a solicitudes visuales de información. |
Resultados
Evaluamos AVIS utilizando conjuntos de datos Infoseek y OK-VQA. Como se muestra a continuación, incluso los modelos de lenguaje visual robustos como OFA y PaLI no logran una alta precisión cuando se ajustan con Infoseek. Nuestro enfoque (AVIS) logra una precisión del 50,7% en la división de entidades invisibles de este conjunto de datos sin realizar ajustes.
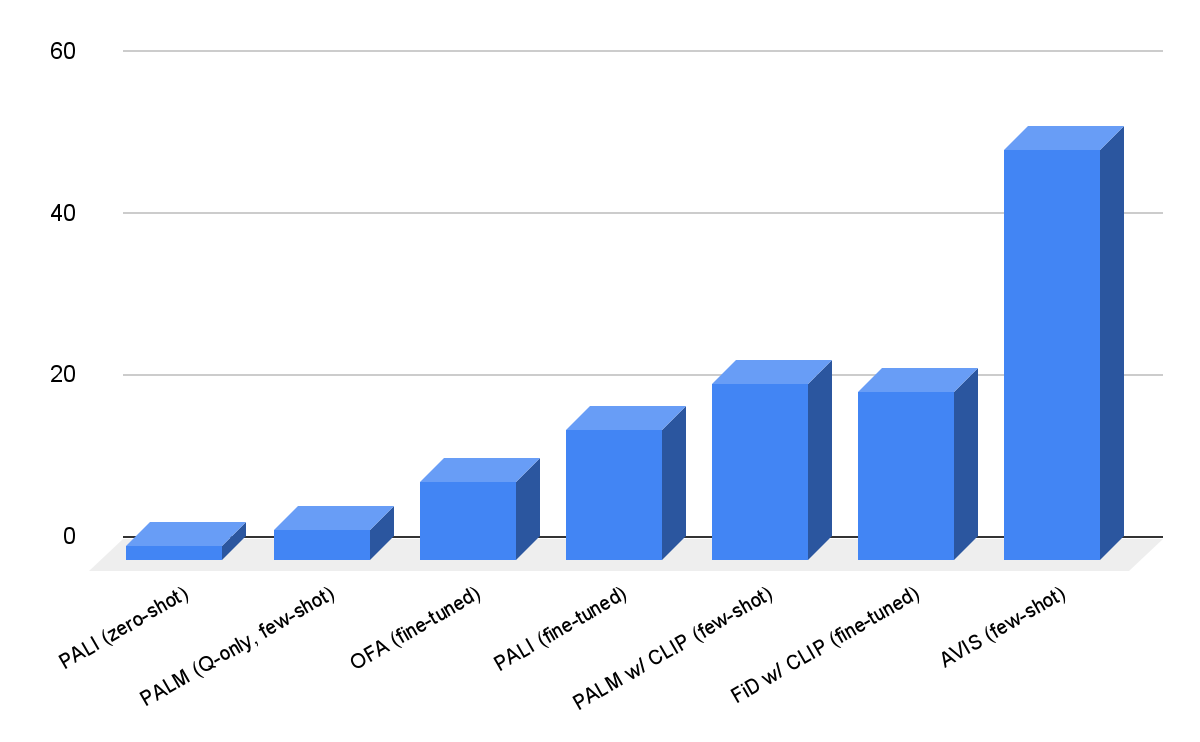 |
| Resultados visuales de preguntas y respuestas de AVIS en el conjunto de datos de Infoseek. AVIS logra una mayor precisión en comparación con líneas de base anteriores basadas en PaLI, PaLM y OFA. |
Nuestros hallazgos sobre el conjunto de datos OK-VQA se presentan a continuación. Con algunos ejemplos contextuales, AVIS logra una precisión del 60,2%, superior a la mayoría de los trabajos anteriores. AVIS logra una precisión menor, pero comparable, en comparación con el modelo PALI optimizado para OK-VQA. Esta diferencia en comparación con Infoseek, donde AVIS supera al PALI finamente afinado, se debe al hecho de que la mayoría de los ejemplos de preguntas y respuestas en OK-VQA se basan en el sentido común más que en un conocimiento detallado. Por lo tanto, PaLI puede codificar dicho conocimiento genérico en los parámetros del modelo y no requiere ningún conocimiento externo.
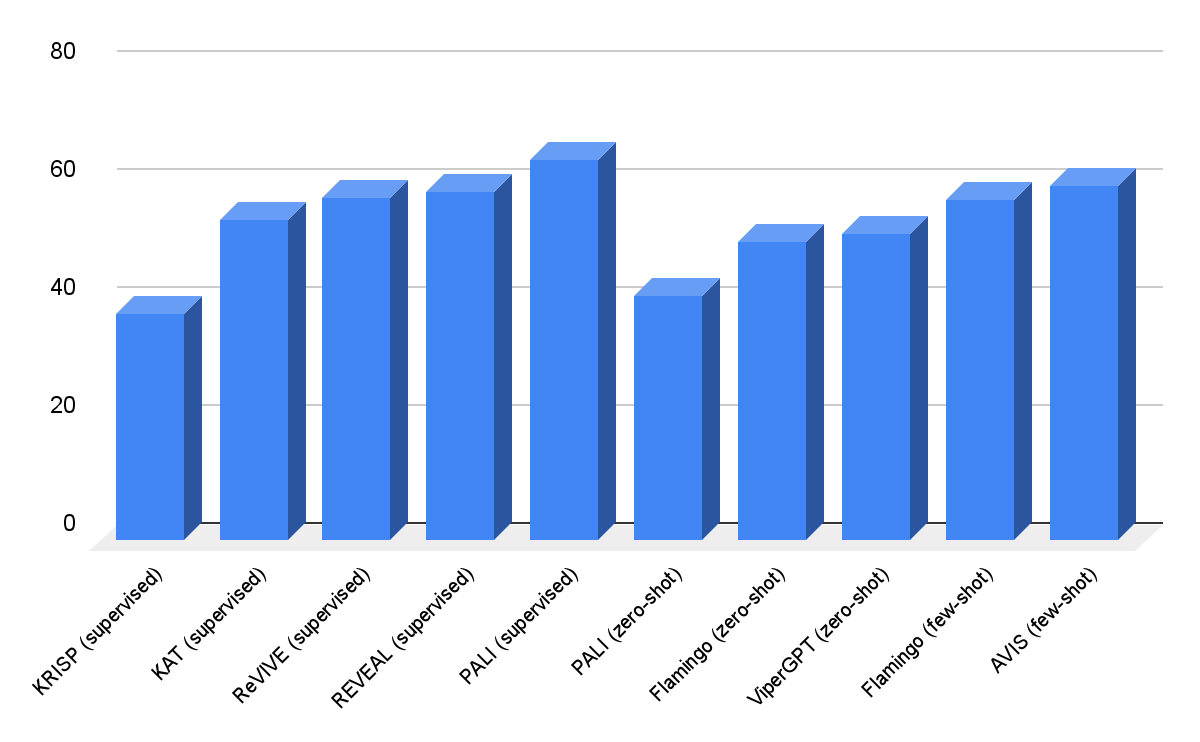 |
| Resultados visuales para responder preguntas sobre A-OKVQA. AVIS logra una mayor precisión en comparación con trabajos anteriores utilizando aprendizaje de tiro bajo o cero, incluidos Flamingo, PaLI y ViperGPT. AVIS también logra una mayor precisión que la mayoría de los trabajos anteriores ajustados en el conjunto de datos OK-VQA, incluidos REVEAL, ReVIVE, KAT y KRISP, y logra resultados cercanos al modelo PaLI ajustado. |
Diploma
Presentamos un enfoque novedoso que permite a los LLM utilizar una variedad de herramientas para responder preguntas visuales intensivas en conocimiento. Nuestra metodología se basa en datos de decisiones humanas recopilados como parte de un estudio de usuarios y emplea un marco estructurado que utiliza un planificador basado en LLM para decidir dinámicamente sobre la selección de herramientas y la formulación de consultas. Un razonador basado en LLM tiene la tarea de procesar y extraer información importante del resultado de la herramienta seleccionada. Nuestro método utiliza el planificador y el pensador de forma iterativa para utilizar diferentes herramientas hasta que se recopila toda la información necesaria para responder la pregunta visual.
gracias
Esta investigación fue realizada por Ziniu Hu, Ahmet Iscen, Chen Sun, Kai-Wei Chang, Yizhou Sun, David A. Ross, Cordelia Schmid y Alireza Fathi.
[ad_2]