
[ad_1]
(Noticias de Nanowerk) La inteligencia artificial (IA) puede entrenarse para reconocer si una imagen de tejido contiene un tumor. Sin embargo, cómo toma exactamente su decisión sigue siendo un misterio hasta ahora. Un equipo del Centro de Investigación para el Diagnóstico de Proteínas (PRODI) de la Universidad Ruhr de Bochum está desarrollando un nuevo enfoque que hace que la decisión de una IA sea transparente y, por lo tanto, confiable.
Los investigadores que trabajan con el profesor Axel Mosig describen el enfoque en la revista especializada Análisis de imágenes médicas («Un marco para explicaciones falsificables de modelos de aprendizaje automático con una aplicación en patología computacional»).
Para el estudio, el bioinformático Axel Mosig cooperó con el profesor Andrea Tannapfel, director del Instituto de Patología, la oncóloga profesora Anke Reinacher-Schick del Hospital St. Josef de la Universidad del Ruhr y el biofísico y director fundador de PRODI, el profesor Klaus Gerwert. El grupo desarrolló una red neuronal, es decir, una IA que puede clasificar si una muestra de tejido contiene un tumor o no. Para hacer esto, alimentaron a la IA con una variedad de imágenes microscópicas de tejido, algunas con tumores, otras sin tumores.
«Las redes neuronales son inicialmente una caja negra: no está claro qué características de reconocimiento aprende una red de los datos de entrenamiento», explica Axel Mosig. A diferencia de los expertos humanos, carecen de la capacidad de explicar sus decisiones. «Especialmente para aplicaciones médicas, es importante que la IA sea explicable y, por lo tanto, confiable», agrega el bioinformático David Schuhmacher, quien trabajó en el estudio.
La IA se basa en hipótesis falsables
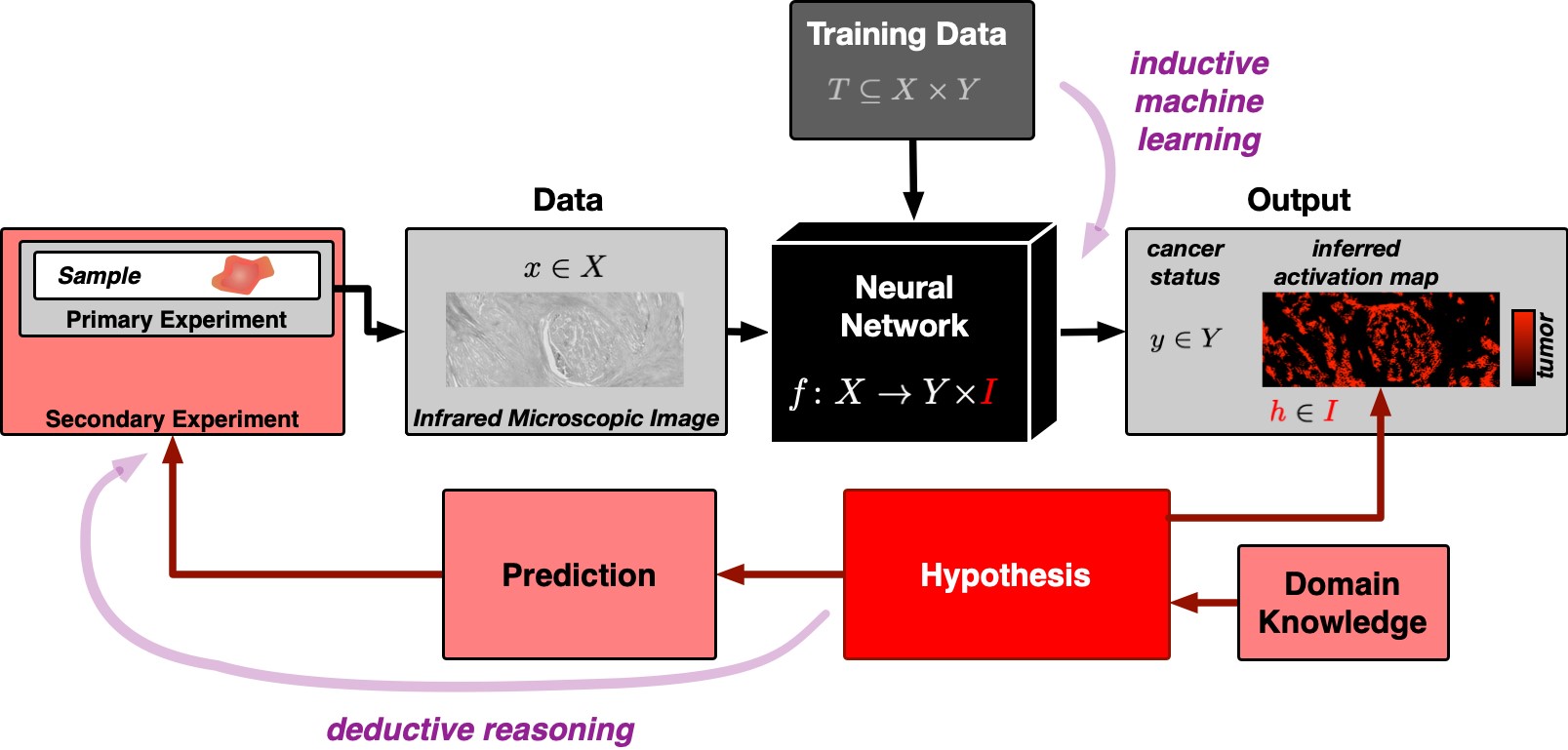
La IA explicable del equipo de Bochum se basa, por lo tanto, en la única declaración significativa conocida por la ciencia: en hipótesis falsables. Si una hipótesis es incorrecta, este hecho debe ser demostrable mediante experimentos. La inteligencia artificial generalmente sigue el principio del razonamiento inductivo: en base a observaciones específicas, es decir, los datos de entrenamiento, la IA crea un modelo general que utiliza para evaluar todas las observaciones posteriores.
El problema subyacente fue descrito hace 250 años por el filósofo David Hume y es fácil de ilustrar: no importa cuántos cisnes blancos observemos, nunca podríamos concluir a partir de estos datos que todos los cisnes son blancos y que no hay cisnes negros en absoluto. La ciencia, por tanto, utiliza lo que se conoce como lógica deductiva. En este enfoque, una hipótesis general es el punto de partida. Por ejemplo, la hipótesis de que todos los cisnes son blancos se falsea cuando se avista un cisne negro.
El mapa de activación muestra dónde se detectó el tumor
«A primera vista, la IA inductiva y el método científico deductivo parecen casi incompatibles», dice Stephanie Schörner, física que también contribuyó al estudio. Pero los investigadores encontraron una manera. Su novedosa red neuronal no solo permite una clasificación de si una muestra de tejido contiene un tumor o no tiene tumor, sino que también genera un mapa de activación de la imagen microscópica del tejido.

El mapa de activación se basa en una hipótesis falsable, a saber, que la activación derivada de la red neuronal se corresponde exactamente con las regiones tumorales de la muestra. Se pueden usar métodos moleculares específicos del sitio para probar esta hipótesis.
«Gracias a las estructuras interdisciplinarias de PRODI, tenemos los mejores requisitos previos para incorporar el enfoque basado en hipótesis en el desarrollo de un biomarcador de IA confiable en el futuro, por ejemplo, para poder distinguir ciertos subtipos de tumores relevantes para la terapia», concluye Axel. Mosig.
[ad_2]