
[ad_1]
Amazon SageMaker Data Wrangler reduce el tiempo que lleva agregar y preparar datos para el aprendizaje automático (ML) de semanas a minutos en Amazon SageMaker Studio, el primer entorno de desarrollo totalmente integrado (IDE) para ML. Con Data Wrangler, puede simplificar la preparación de datos y el proceso de ingeniería de características y completar cada paso del flujo de trabajo de preparación de datos, incluida la selección, limpieza, exploración y visualización de datos, desde una única interfaz visual. Puede importar datos de varias fuentes de datos, como Amazon Simple Storage Service (Amazon S3), Amazon Redshift, Snowflake y 26 fuentes de datos de consultas federadas compatibles con Amazon Athena.
A partir de hoy, al importar datos de fuentes de datos de Athena, puede configurar la ubicación de salida de la consulta de S3 y el período de retención de datos para importar datos en Data Wrangler para controlar dónde y durante cuánto tiempo Athena almacena los datos intermedios. En esta publicación, lo guiaremos a través de esta nueva función.
descripción general de la solución
Athena es un servicio de consulta interactivo que facilita la exploración del catálogo de datos de AWS Glue y el análisis de datos en Amazon S3 y 26 fuentes de datos de consulta federadas mediante SQL estándar. Si usa Athena para importar datos, puede usar la ubicación S3 predeterminada de Data Wrangler para la salida de consultas de Athena o especificar un grupo de trabajo de Athena para aplicar una ubicación S3 personalizada. Anteriormente, tenía que implementar flujos de trabajo de limpieza para eliminar estos datos intermedios o configurar manualmente la configuración del ciclo de vida de S3 para controlar los costos de almacenamiento y cumplir con los requisitos de seguridad de datos de su organización. Esta es una gran sobrecarga operativa y no escalable.
Data Wrangler ahora admite ubicaciones de S3 personalizadas y períodos de retención de datos para la salida de su consulta de Athena. Esta nueva función le permite cambiar la ubicación de salida de la consulta de Athena a un depósito de S3 personalizado. Ahora tiene una política de retención de datos predeterminada de 5 días para la salida de consultas de Athena y puede cambiarla para satisfacer las necesidades de seguridad de datos de su organización. Según el período de retención, el resultado de la consulta de Athena se limpia automáticamente en el depósito de S3. Después de importar los datos, puede realizar un análisis exploratorio de datos en ese conjunto de datos y guardar los datos limpios en Amazon S3.
El siguiente diagrama ilustra esta arquitectura.

Para nuestro caso de uso, usaremos un registro bancario de ejemplo para recorrer la solución. El flujo de trabajo consta de los siguientes pasos:
- Descargue el conjunto de datos de muestra y cárguelo en un depósito de S3.
- Configure un rastreador de AWS Glue para rastrear el esquema y almacenar el esquema de metadatos en el catálogo de datos de AWS Glue.
- Utilice Athena para acceder al catálogo de datos para consultar datos del depósito S3.
- Cree un nuevo flujo de Data Wrangler para conectarse a Athena.
- Al crear la conexión, establezca el TTL de retención para el conjunto de datos.
- Utilice esta conexión en el flujo de trabajo y almacene los datos limpios en otro depósito de S3.
En aras de la simplicidad, asumimos que ya ha configurado el entorno de Athena (pasos 1-3). Explicamos los pasos adicionales en este artículo.
requisitos
Para configurar el entorno de Athena, consulte el manual del usuario para obtener instrucciones paso a paso y siga los pasos 1 a 3 como se describe en la sección anterior.
Importe sus datos de Athena a Data Wrangler
Siga los pasos a continuación para importar sus datos:
- En la consola de Studio, seleccione el recursos icono en el área de navegación.
- Elegir organizador de datos en el menú desplegable.
- Elegir río nuevo.

- Sobre el Importar pestaña, seleccione amazona atena.

Se abre una página de detalles donde puede conectarse a Athena y escribir una consulta SQL para importar desde la base de datos. - Introduzca un nombre para su conexión.

- Extender Configuración avanzada.
Al conectarse a Athena, Data Wrangler utiliza Amazon S3 para proporcionar los datos consultados. De forma predeterminada, estos datos se proporcionan en el sitio de S3s3://sagemaker-{region}-{account_id}/athena/con un período de retención de 5 días. - Hacia Amazon S3 ubicación de los resultados de la consultaingrese su ubicación S3.
- Elegir período de retención de datos y establezca el período de retención de datos (1 día para esta publicación).
Si deshabilita esta opción, los datos se conservarán indefinidamente.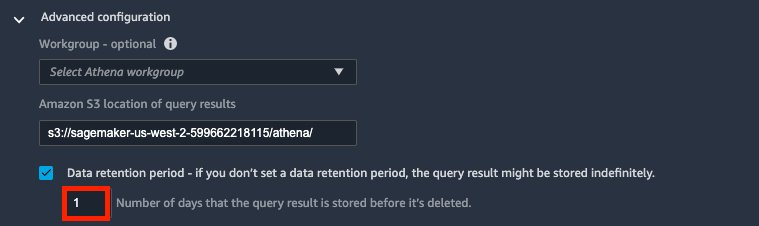 Detrás de escena, Data Wrangler adjunta una política de configuración del ciclo de vida de S3 a esta ubicación de S3 para limpiarla automáticamente. Consulte la siguiente política de ejemplo:
Detrás de escena, Data Wrangler adjunta una política de configuración del ciclo de vida de S3 a esta ubicación de S3 para limpiarla automáticamente. Consulte la siguiente política de ejemplo:
Necesitas
s3:GetLifecycleConfigurationys3:PutLifecycleConfigurationpara que su función de ejecución de SageMaker aplique correctamente las políticas de configuración del ciclo de vida. Sin estos permisos, recibirá mensajes de error cuando intente importar los datos.El siguiente mensaje de error es un ejemplo de falta del
GetLifecycleConfigurationPermiso.
El siguiente mensaje de error es un ejemplo de falta del
PutLifecycleConfigurationPermiso.
- Si es necesario, por ej. grupo de trabajopuede especificar un grupo de trabajo de Athena.
Un grupo de trabajo de Athena aísla usuarios, equipos, aplicaciones o cargas de trabajo en grupos, cada uno con sus propios permisos y ajustes de configuración. Si especifica un grupo de trabajo, Data Wrangler hereda la configuración del grupo de trabajo definida en Athena. Por ejemplo, si un grupo de trabajo ha definido una ubicación de S3 para almacenar los resultados de la consulta y anular la configuración del lado del cliente, no puede editar la ubicación de los resultados de la consulta de S3. De forma predeterminada, Data Wrangler también guarda la conexión de Athena por usted. Esto aparecerá como una nueva ficha de Atenea en la Importar Tabulador Siempre puede volver a abrir esta conexión para consultar otros datos y llevarlos a Data Wrangler.
De forma predeterminada, Data Wrangler también guarda la conexión de Athena por usted. Esto aparecerá como una nueva ficha de Atenea en la Importar Tabulador Siempre puede volver a abrir esta conexión para consultar otros datos y llevarlos a Data Wrangler.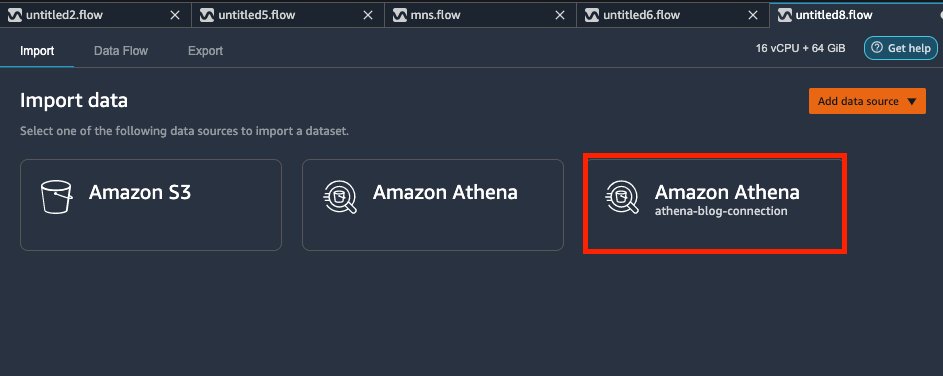
- Deseleccionar guardar conexión si no desea guardar la conexión.

- Para configurar la conexión de Athena, seleccione ninguna hacia muestreo para importar todo el conjunto de datos.

Para grandes conjuntos de datos, Data Wrangler le permite importar un subconjunto de sus datos para crear su flujo de trabajo de transformación y solo procesar el conjunto de datos completo cuando esté listo. Esto acelera el ciclo de iteración y ahorra tiempo y costos de procesamiento. Para obtener más información sobre las diferentes opciones de muestreo de datos disponibles, visite Amazon SageMaker Data Wrangler ahora admite muestreo aleatorio y muestreo estratificado. - Hacia Catálogo de datosSeleccione Catálogo de datos de AWS.
- Hacia Base de datosseleccione su base de datos.

Data Wrangler mostrará las tablas disponibles. Puede seleccionar cualquier tabla para revisar el esquema y obtener una vista previa de los datos.
- Introduzca el siguiente código en el campo de consulta:
- Elegir Correr para obtener una vista previa de los datos.
- Si todo se ve bien, elija Importar.
- Introduzca un nombre de registro y seleccione añadir para importar los datos a su espacio de trabajo de Data Wrangler.

Analice y procese datos con Data Wrangler
Después de cargar los datos en Data Wrangler, puede realizar un análisis exploratorio de datos (EDA) y preparar los datos para el aprendizaje automático.
- Seleccione el signo más junto a eso
bank-dataRegistrar en el flujo de datos y seleccionar Agregar análisis.
Data Wrangler ofrece análisis integrados que incluyen un informe de información y calidad de datos, correlación de datos, un informe de sesgo previo al entrenamiento, un resumen de su conjunto de datos y visualizaciones (como histogramas y diagramas de dispersión). Además, puede crear su propia visualización personalizada.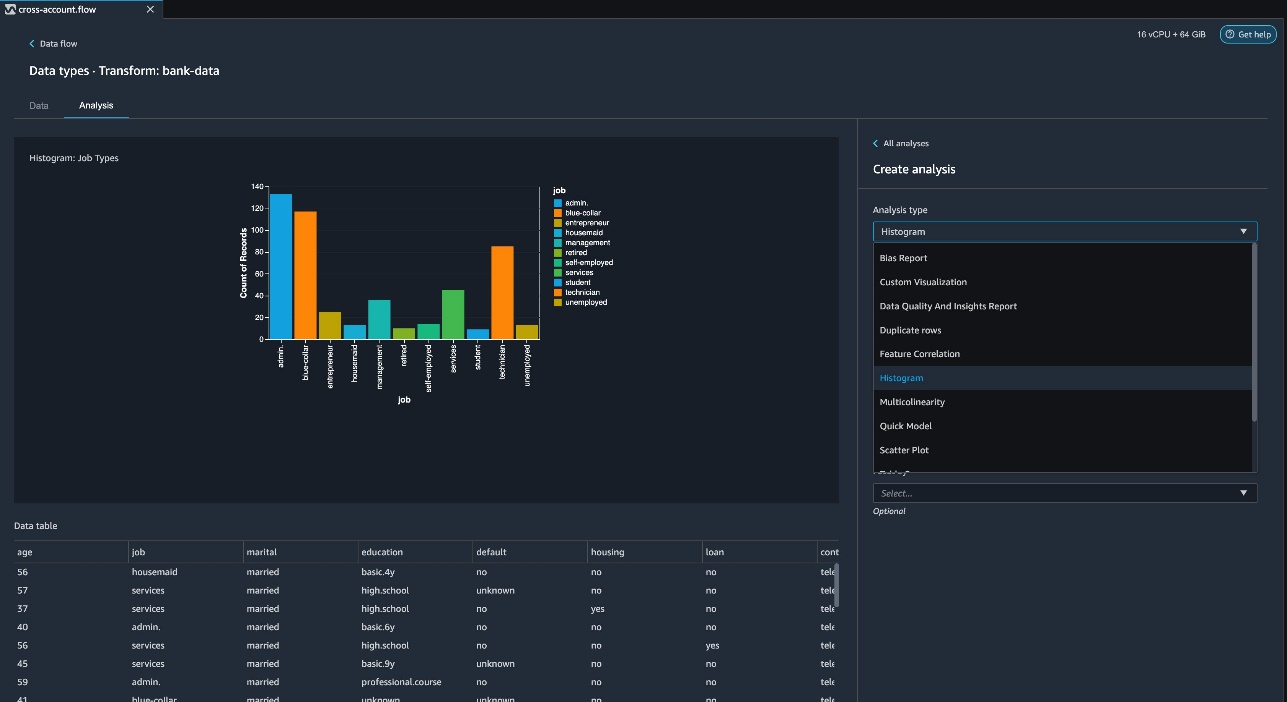
- Hacia tipo de análisisSeleccione Informe de información y calidad de datos.
Esto genera automáticamente visualizaciones, análisis para identificar problemas de calidad de datos y recomendaciones para las transformaciones correctas necesarias para su conjunto de datos. - Hacia columna de destinoSeleccione Y.
- Dado que este es un problema de clasificación, p. tipo de problemaelegir clasificación.
- Elegir Crear.

Data Wrangler crea un informe detallado sobre su conjunto de datos. También puede descargar el informe a su computadora local.
- Para la preparación de datos en el flujo de datos, seleccione el signo más junto al registro de datos bancarios y seleccione Agregar Transformar.
- Elegir añadir paso para empezar a construir tus transformaciones.

Al momento de escribir, Data Wrangler ofrece más de 300 transformaciones integradas. También puede escribir sus propias transformaciones usando Pandas o PySpark.
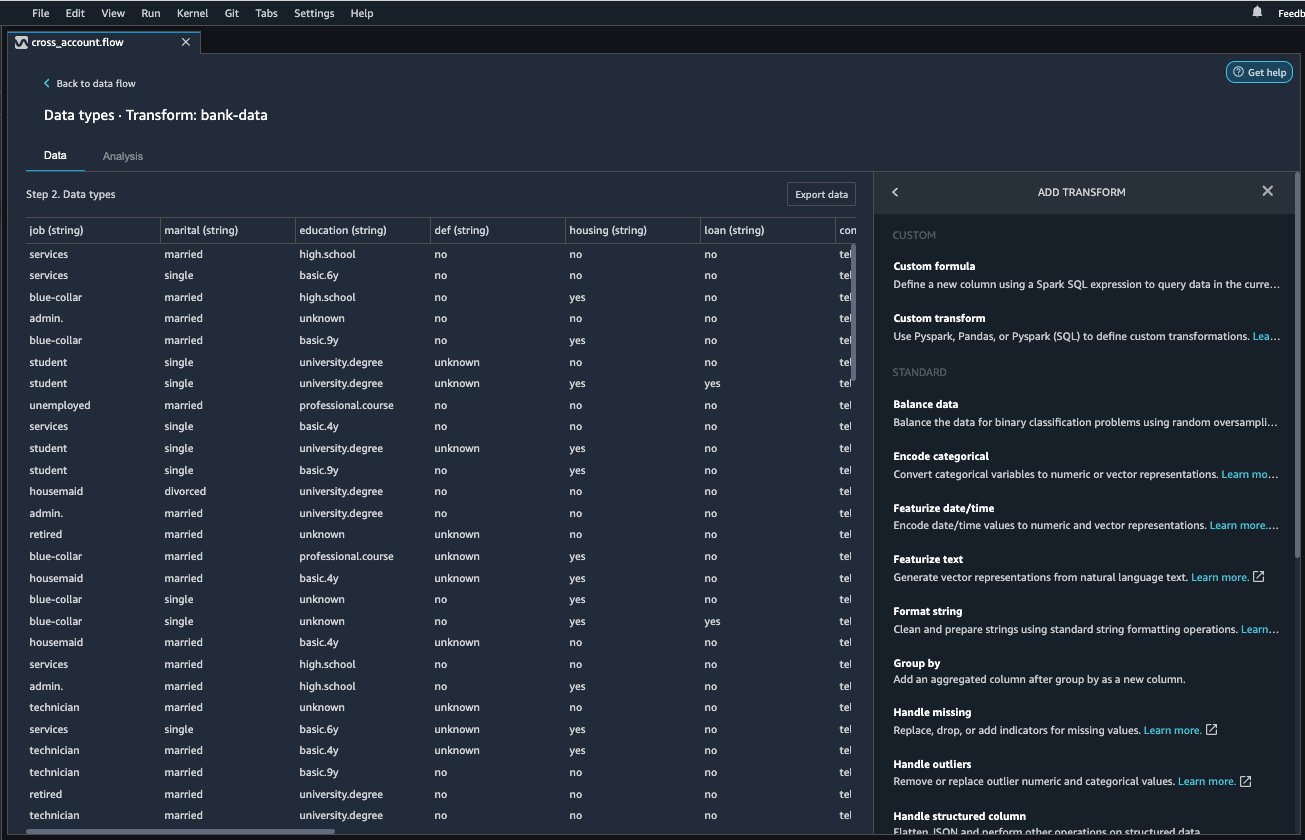
Ahora puede comenzar a construir sus transformaciones y análisis en función de sus necesidades comerciales.
Limpiar
Para evitar costos de funcionamiento, utilice los siguientes pasos para eliminar los recursos de Data Wrangler cuando haya terminado.
- Seleccione el icono Instancias y núcleos en ejecución.
- En APLICACIONES EN EJECUCIÓN, haga clic en el icono de apagado junto a
sagemaker-data-wrangler-1.0 app. - Seleccione Apagar todo para confirmar.

Conclusión
En esta publicación, proporcionamos una descripción general de cómo personalizar su ubicación de S3 y habilitar las configuraciones del ciclo de vida de S3 para importar datos de Athena a Data Wrangler. Esta función le permite almacenar datos intermedios en una ubicación segura de S3 y eliminar automáticamente la copia de datos después de que expire el período de retención para reducir el riesgo de acceso no autorizado a los datos. Te animamos a que pruebes esta nueva función. ¡Feliz edificio!
Para obtener más información sobre Athena y SageMaker, visite la Guía del usuario de Athena y la Documentación de Amazon SageMaker.
Sobre los autores
 Meenakshisundaram Thandavarayan es especialista sénior en inteligencia artificial y aprendizaje automático en AWS. Ayuda a cuentas estratégicas de alta tecnología en su viaje de IA y ML. Está muy interesado en la IA basada en datos.
Meenakshisundaram Thandavarayan es especialista sénior en inteligencia artificial y aprendizaje automático en AWS. Ayuda a cuentas estratégicas de alta tecnología en su viaje de IA y ML. Está muy interesado en la IA basada en datos.
 Harish Rajagopalan es arquitecto sénior de soluciones en Amazon Web Services. Harish trabaja con clientes empresariales y los ayuda en su viaje a la nube.
Harish Rajagopalan es arquitecto sénior de soluciones en Amazon Web Services. Harish trabaja con clientes empresariales y los ayuda en su viaje a la nube.
 James Wu es arquitecto sénior de soluciones especialista en inteligencia artificial y aprendizaje automático en AWS. Apoyar a los clientes en el desarrollo y creación de soluciones AI/ML. El trabajo de James cubre una amplia gama de casos de uso de ML, y sus principales intereses son la visión artificial, el aprendizaje profundo y la ampliación de ML en toda la empresa. Antes de unirse a AWS, James fue arquitecto, desarrollador y líder tecnológico durante más de 10 años, incluidos 6 años en ingeniería y 4 años en la industria del marketing y la publicidad.
James Wu es arquitecto sénior de soluciones especialista en inteligencia artificial y aprendizaje automático en AWS. Apoyar a los clientes en el desarrollo y creación de soluciones AI/ML. El trabajo de James cubre una amplia gama de casos de uso de ML, y sus principales intereses son la visión artificial, el aprendizaje profundo y la ampliación de ML en toda la empresa. Antes de unirse a AWS, James fue arquitecto, desarrollador y líder tecnológico durante más de 10 años, incluidos 6 años en ingeniería y 4 años en la industria del marketing y la publicidad.
[ad_2]