[ad_1]
El aprendizaje por refuerzo profundo (RL, por sus siglas en inglés) continúa dando grandes pasos para resolver problemas de decisiones secuenciales del mundo real, como la navegación con globos, la física nuclear, la robótica y los juegos. A pesar de su promesa, los largos tiempos de entrenamiento son uno de los factores limitantes. Si bien el enfoque actual para acelerar la capacitación de RL para tareas complejas y difíciles utiliza capacitación distribuida ampliada a cientos o incluso miles de nodos de cómputo, aún requiere la implementación de recursos de hardware significativos, lo que hace que la capacitación de RL sea costosa y reduce el impacto ambiental. Sin embargo, trabajos más recientes [1, 2] señala que las optimizaciones de rendimiento en el hardware existente pueden reducir la huella de carbono (es decir, las emisiones totales de gases de efecto invernadero) de la formación y la inferencia.
RL también puede beneficiarse de técnicas similares de optimización del sistema que reducen el tiempo de capacitación, mejoran la utilización del hardware y reducen el dióxido de carbono (CO2) emisiones. Una de esas técnicas es la cuantificación, un proceso que convierte números de punto flotante de precisión completa (FP32) en números de menor precisión (int8) y luego realiza cálculos utilizando los números de menor precisión. La cuantificación puede ahorrar costos de memoria y ancho de banda para un cálculo más rápido y con mayor eficiencia energética. La cuantificación se ha aplicado con éxito al aprendizaje supervisado para permitir implementaciones de borde de modelos de aprendizaje automático (ML) y lograr un entrenamiento más rápido. Sin embargo, queda una forma de aplicar la cuantificación al entrenamiento de RL.
Para ello presentamos QuaRL: Quantization for Fast and Environmentally Sustainable Reinforcement Learning, publicado en el Transacciones de investigación de aprendizaje automático Revista que presenta un nuevo paradigma llamado ActorQ que aplica cuantificación para acelerar el entrenamiento de RL entre 1,5x y 5,4x mientras se mantiene el rendimiento. Además, mostramos que, en comparación con el entrenamiento con total precisión, la huella de carbono también se reduce significativamente en un factor de 1,9-3,8x.
Aplicación de la cuantificación al entrenamiento de RL
En el entrenamiento tradicional de RL un aprendiz La política se aplica a uno actor, que utiliza la política para explorar el entorno y recopilar muestras de datos. Las muestras recogidas de la actor luego son utilizados por el aprendiz para refinar continuamente la política original. Periódicamente, la política entrenada en el sitio del alumno se utiliza para actualizar el actor Política. Para aplicar la cuantificación al entrenamiento de RL, desarrollamos el paradigma ActorQ. ActorQ ejecuta la misma secuencia descrita anteriormente, con una diferencia clave: la actualización de la política se cuantifica desde el alumno hasta los actores, y el actor explora el entorno mediante la política de muestreo cuantificado int8.
La aplicación de la cuantificación al entrenamiento de RL de esta manera tiene dos beneficios principales. Primero, reduce la huella de memoria de la política. Con el mismo ancho de banda máximo, se transfieren menos datos entre los alumnos y los actores, lo que reduce los costos de comunicación para las actualizaciones de políticas de los alumnos a los actores. Segundo, los actores infieren la política cuantificada para generar acciones para un estado ambiental dado. El proceso de inferencia cuantificada es mucho más rápido en comparación con la realización de una inferencia de precisión completa.
 |
| Una descripción general del entrenamiento tradicional de RL (Izquierda) y Entrenamiento ActorQ RL (A la derecha). |
En ActorQ usamos el framework RL distribuido ACME. El bloque de cuantificación realiza una cuantificación uniforme que convierte la directiva FP32 en int8. El actor realiza inferencias con cálculos int8 optimizados. Aunque utilizamos la cuantificación uniforme al diseñar el bloque cuantificador, creemos que otras técnicas de cuantificación pueden reemplazar la cuantificación uniforme y lograr resultados similares. El alumno utiliza las muestras recopiladas por los actores para entrenar una estrategia de red neuronal. Periódicamente, la política aprendida es cuantificada por el bloque cuantificador y transmitida a los actores.
La cuantificación mejora el tiempo de entrenamiento y el rendimiento de RL
Evaluamos ActorQ en varios entornos, incluidos Deepmind Control Suite y OpenAI Gym. Demostramos la aceleración y el rendimiento mejorado de D4PG y DQN. Elegimos D4PG porque era el mejor algoritmo de aprendizaje en ACME para las tareas de Deepmind Control Suite y DQN es un algoritmo RL estándar y ampliamente utilizado.
Observamos una aceleración significativa (entre 1,5x y 5,41x) en la formación de políticas de RL. Más importante aún, el rendimiento se mantiene incluso cuando los actores realizan una inferencia cuantificada int8. Las imágenes a continuación muestran esto para los agentes D4PG y DQN para las tareas de Deepmind Control Suite y OpenAI Gym.
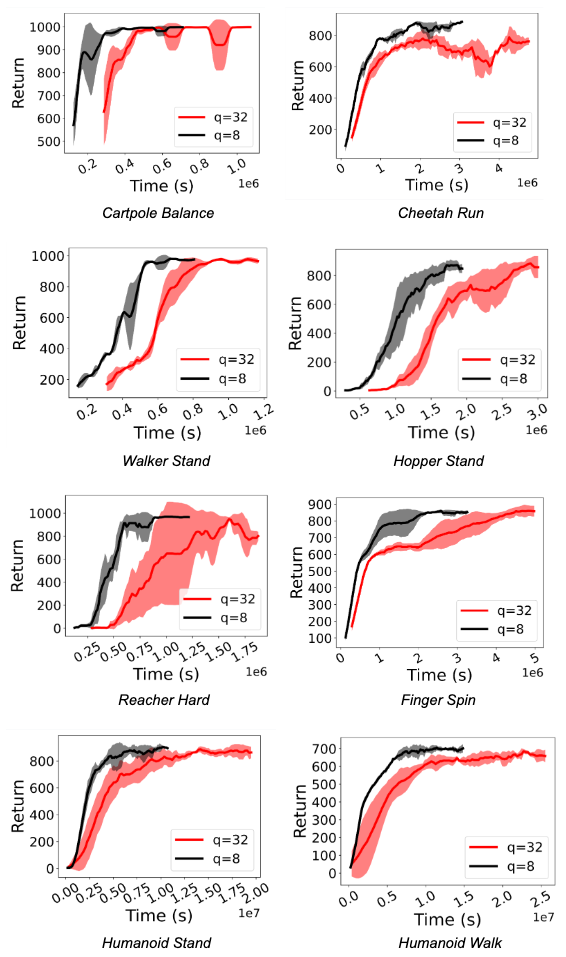 |
| Una comparación del entrenamiento de RL usando la política FP32 (q=32) y la política int8 cuantificada (q=8) para agentes D4PG en varias tareas de Deepmind Control Suite. La cuantización logra aceleraciones de 1,5x a 3,06x. |
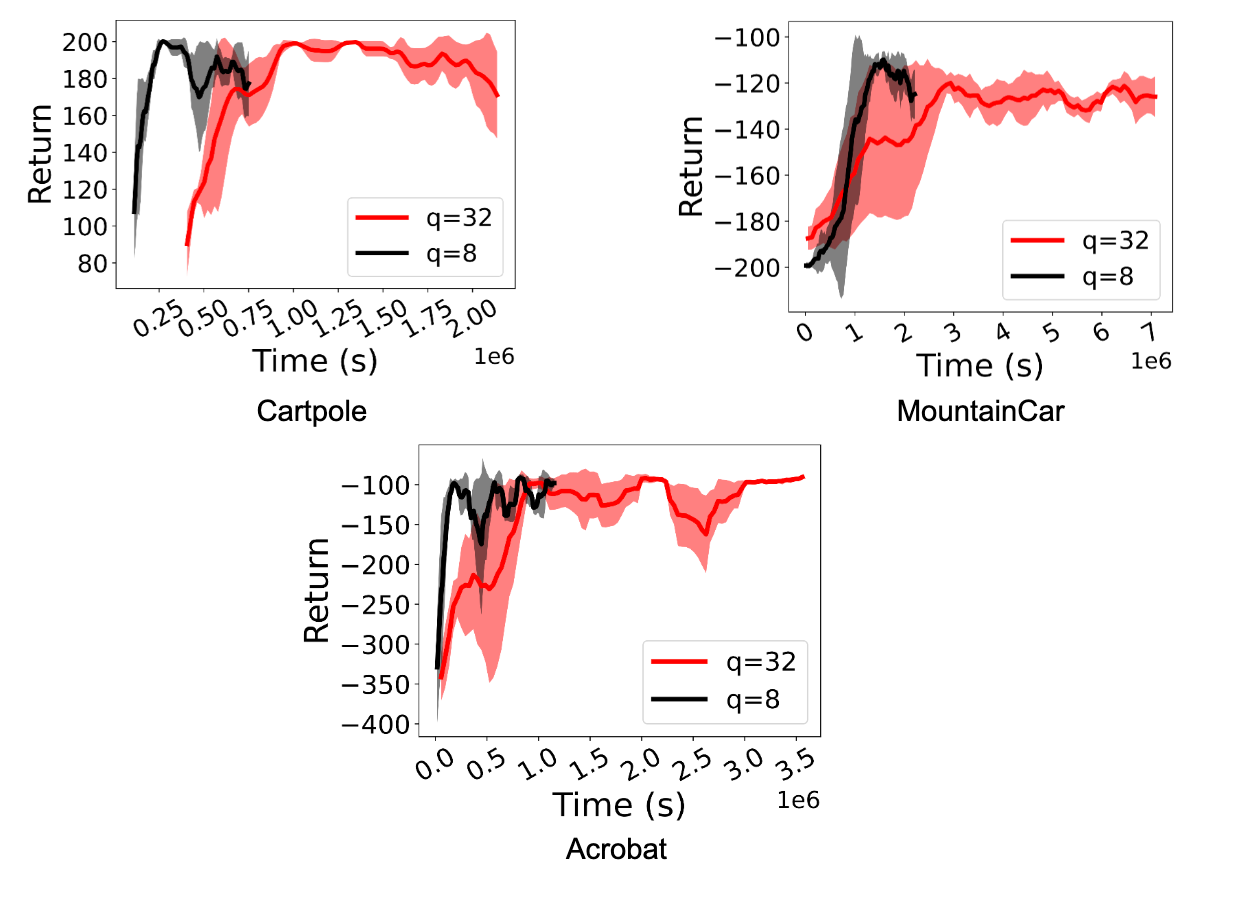 |
| Una comparación del entrenamiento de RL utilizando la pauta FP32 (q=32) y la pauta int8 cuantificada (q=8) para agentes DQN en el entorno OpenAI Gym. La cuantización logra una aceleración de 2,2x a 5,41x. |
La cuantización reduce las emisiones de carbono
La aplicación de cuantificación en RL con ActorQ mejora el tiempo de entrenamiento sin sacrificar el rendimiento. El resultado directo de usar el hardware de manera más eficiente es una menor huella de carbono. Medimos la mejora de la huella de carbono calculando el ratio de emisión de CO2 al aplicar la política FP32 durante el ejercicio frente a la emisión de CO2 al aplicar la política int8 durante el ejercicio.
Para medir la emisión de carbono para el experimento de entrenamiento RL, usamos el rastreador de impacto del experimento propuesto en trabajos anteriores. Equipamos el sistema ActorQ con API de monitoreo de carbono para medir la energía y las emisiones de carbono para cada experimento de entrenamiento.
En comparación con la emisión de CO2 con precisión total (FP32), observamos que la cuantificación de las pautas reduce las emisiones de CO2 entre 1,9x y 3,76x, según la tarea. Dado que los sistemas RL se escalan para ejecutarse en miles de aceleradores y núcleos de hardware distribuidos, creemos que la reducción absoluta de CO2 (medida en kilogramos de CO2) puede ser muy importante.
 |
| Comparación de emisiones de CO2 entre cursos de formación utilizando una política RP32 y una política int8. La escala del eje X está normalizada a las emisiones de carbono de la política FP32. Indicado por las barras rojas mayores que 1, ActorQ reduce las emisiones de CO2. |
Conclusión y direcciones futuras
Presentamos ActorQ, un paradigma novedoso que aplica la cuantificación al entrenamiento de RL y logra mejoras de aceleración de 1.5-5.4x mientras preserva el rendimiento. Además, mostramos que ActorQ puede reducir la huella de carbono del entrenamiento de RL en un factor de 1,9 a 3,8 en comparación con el entrenamiento de precisión total sin cuantificación.
ActorQ demuestra que la cuantificación se puede aplicar de manera efectiva a muchos aspectos de RL, desde lograr políticas cuantificadas eficientes y de alta calidad hasta reducir los tiempos de capacitación y las emisiones de carbono. A medida que RL continúa dando grandes pasos para resolver problemas del mundo real, creemos que hacer que la capacitación de RL sea sostenible será fundamental para la adopción. A medida que escalamos el entrenamiento de RL a miles de núcleos y GPU, incluso una mejora del 50 por ciento (como hemos demostrado experimentalmente) dará como resultado ahorros significativos en costos absolutos en dólares, energía y emisiones de CO2. Nuestro trabajo es el primer paso para aplicar la cuantización al entrenamiento de RL para conseguir un entrenamiento eficiente y respetuoso con el medio ambiente.
Si bien nuestro diseño del cuantificador en ActorQ se basó en una cuantificación uniforme simple, creemos que se pueden aplicar otras formas de cuantificación, compresión y dispersión (p. ej., destilación, dispersión, etc.). Esperamos que el trabajo futuro considere la aplicación de métodos de compresión y cuantización más agresivos, lo que puede traer beneficios adicionales al compromiso de rendimiento y precisión logrado por las pautas de RL entrenadas.
Gracias
Nos gustaría agradecer a nuestros coautores Max Lam, Sharad Chitlangia, Zishen Wan y Vijay Janapa Reddi (Universidad de Harvard) y Gabriel Barth-Maron (DeepMind) por su contribución a este trabajo. También agradecemos al equipo de Google Cloud por proporcionar crédito de investigación para este trabajo.
[ad_2]