
[ad_1]
Los modelos de lenguajes grandes (LLM), como GPT-3 y PaLM, han logrado avances impresionantes en los últimos años, impulsados por modelos de escala y tamaños de datos de entrenamiento. No obstante, ha habido durante mucho tiempo un debate sobre si los LLM pueden inferir simbólicamente (es decir, manipular símbolos basándose en reglas lógicas). Por ejemplo, los LLM pueden realizar operaciones aritméticas simples cuando los números son pequeños, pero tienen dificultades con números grandes. Esto sugiere que los LLM no han aprendido las reglas subyacentes necesarias para realizar estas operaciones aritméticas.
Aunque las redes neuronales tienen poderosas capacidades de coincidencia de patrones, tienden a sobreajustar patrones estadísticos falsos en los datos. Esto no resta valor al buen desempeño cuando los datos de entrenamiento son grandes y diversos y la evaluación está distribuida. Sin embargo, para tareas que requieren razonamiento basado en reglas (por ejemplo, suma), los LLM luchan con la generalización fuera de la distribución, ya que las correlaciones espurias en los datos de entrenamiento suelen ser mucho más fáciles de explotar que la verdadera solución basada en reglas. A pesar de los avances significativos en una variedad de tareas de procesamiento del lenguaje natural, el desempeño en tareas computacionales simples como la suma siguió siendo un desafío. Incluso con una ligera mejora en los datos MATH establecidos por GPT-4, los errores todavía se deben en gran medida a errores aritméticos y de cálculo. Por lo tanto, una pregunta importante es si los LLM son capaces de pensar algorítmicamente, lo que implica resolver una tarea aplicando un conjunto de reglas abstractas que definen el algoritmo.
En «Enseñanza del razonamiento algorítmico mediante el aprendizaje en contexto» describimos un enfoque que utiliza el aprendizaje en contexto para habilitar habilidades de razonamiento algorítmico en los LLM. El aprendizaje contextual es la capacidad de un modelo para realizar una tarea después de ver algunos ejemplos de ella en el contexto del modelo. La tarea se asigna al modelo mediante un mensaje sin necesidad de actualizar el peso. También presentamos una novedosa técnica de indicación algorítmica que permite que los modelos de lenguaje de propósito general logren una fuerte generalización en problemas aritméticos que son más difíciles que los encontrados en la indicación. Finalmente, mostramos que con una elección adecuada de la estrategia de activación, un modelo puede ejecutar algoritmos de manera confiable para ejemplos fuera de distribución.
 |
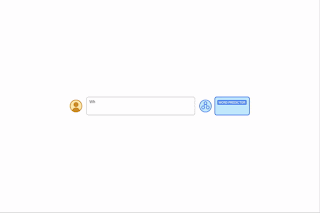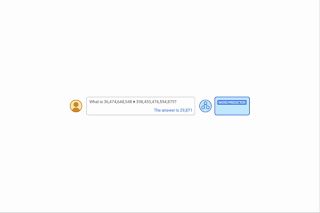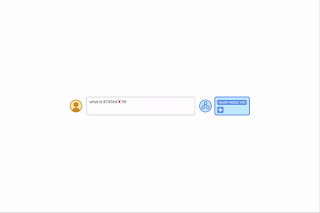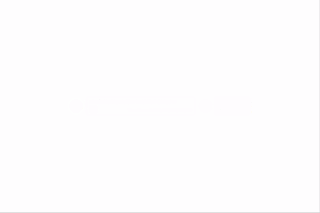
| Al proporcionar indicaciones algorítmicas, podemos enseñarle a un modelo las reglas de la aritmética a través del aprendizaje contextual. En este ejemplo, el LLM (predictor de palabras) devuelve la respuesta correcta cuando se le solicita una pregunta de suma simple (por ejemplo, 267+197), pero falla cuando se le hace una pregunta de suma similar con dígitos más largos. Sin embargo, si se adjunta una solicitud de adición algorítmica a la pregunta más difícil (cuadro azul con blanco + (vea la figura debajo de la palabra predictor) el modelo puede responder correctamente. Además, el modelo es capaz de simular el algoritmo de multiplicación (X) reuniendo una serie de cálculos de suma. |
Enseñar un algoritmo como habilidad
Para enseñarle a un modelo un algoritmo como habilidad, desarrollamos indicaciones algorítmicas que se basan en otros enfoques racionales complementados (por ejemplo, bloc de notas y cadena de pensamiento). Las indicaciones algorítmicas extraen habilidades de razonamiento algorítmico de los LLM y tienen dos diferencias notables en comparación con otros enfoques de indicaciones: (1) resuelve tareas generando los pasos necesarios para una solución algorítmica y (2) explica cada paso algorítmico con suficiente detalle. espacio para malas interpretaciones por parte del LLM.
Para tener una idea del mensaje algorítmico, consideremos la tarea de sumar dos números. En un mensaje estilo bloc de notas, procesamos cada dígito de derecha a izquierda, rastreando el valor de acarreo en cada paso (es decir, agregamos un 1 al siguiente dígito si el dígito actual es mayor que 9). Sin embargo, la regla de acarreo es ambigua después de ver sólo unos pocos ejemplos de valores de acarreo. Descubrimos que incluir ecuaciones explícitas que describan la regla de acarreo ayuda al modelo a centrarse en los detalles relevantes e interpretar la indicación con mayor precisión. Utilizamos estos conocimientos para desarrollar un mensaje algorítmico para sumar dos números, proporcionando ecuaciones explícitas para cada paso de cálculo y describiendo varias operaciones de indexación en formatos inequívocos.
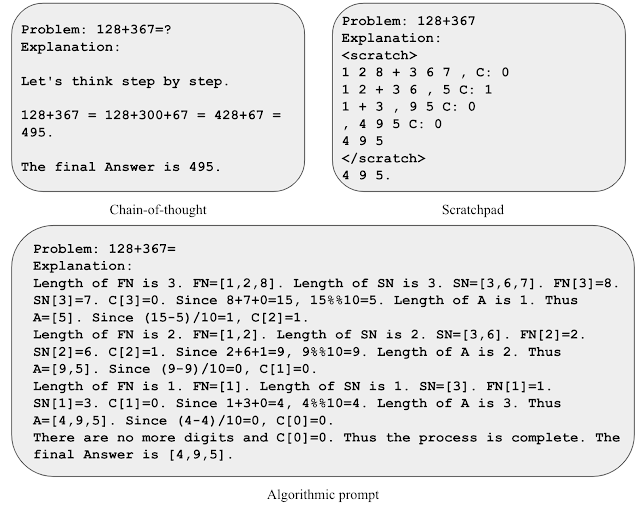 |
| Presentación de diferentes estrategias de suma oportuna. |
Utilizando solo tres mensajes de ejemplo para sumas con una longitud de respuesta de hasta 5 dígitos, evaluamos el rendimiento para sumas de hasta 19 dígitos. La precisión se mide utilizando un total de 2000 muestras distribuidas uniformemente a lo largo de la respuesta. Como se muestra a continuación, el uso de indicaciones algorítmicas garantiza una alta precisión para las preguntas que toman mucho más tiempo de lo que indica la indicación. Esto muestra que el modelo realmente resuelve la tarea ejecutando un algoritmo independiente de la entrada.
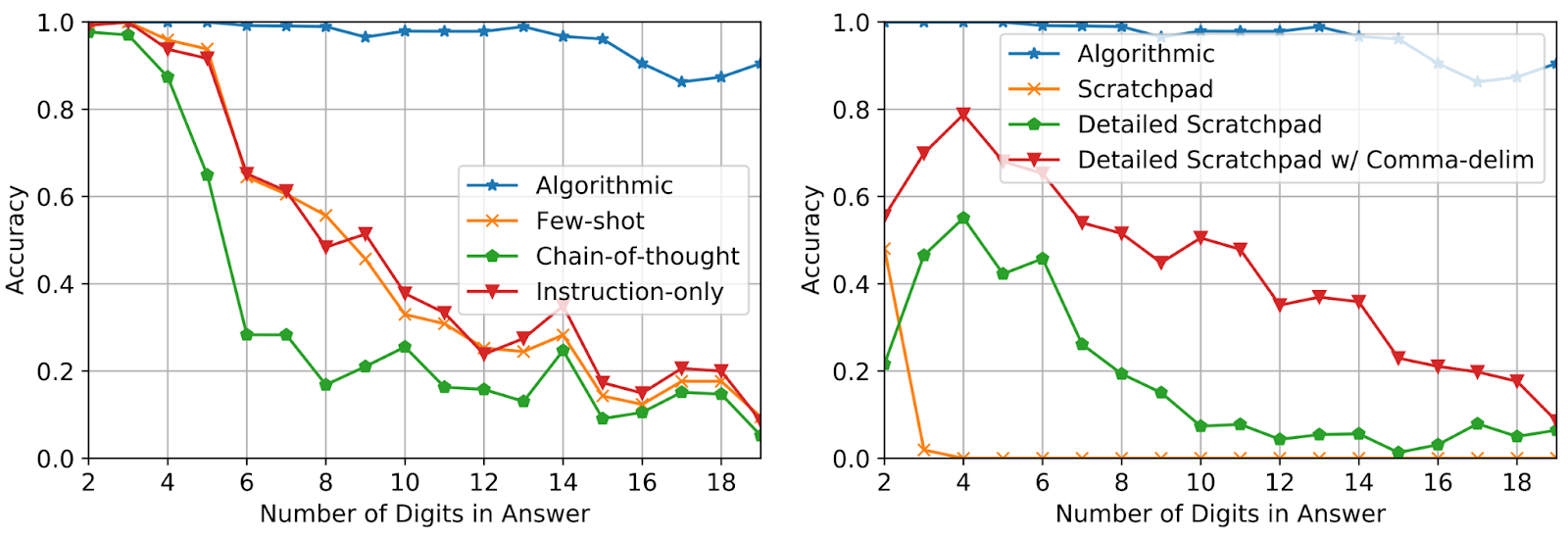 |
| Pruebe la precisión de las preguntas de suma con longitud creciente para diferentes métodos de entrada. |
Uso de habilidades algorítmicas como uso de herramientas.
Para evaluar si el modelo puede utilizar el razonamiento algorítmico en un proceso de pensamiento más amplio, evaluamos el desempeño mediante problemas planteados de matemáticas de la escuela primaria (GSM8k). Estamos tratando específicamente de reemplazar los cálculos de suma de GSM8k con una solución algorítmica.
Motivados por restricciones de longitud del contexto y posibles interferencias entre diferentes algoritmos, investigamos una estrategia en la que modelos gobernados de manera diferente interactúan entre sí para resolver tareas complejas. En el contexto de GSM8k tenemos un modelo especializado en razonamiento matemático informal utilizando indicaciones de cadenas de pensamiento y un segundo modelo especializado adicionalmente en indicaciones algorítmicas. Al modelo de razonamiento matemático informal se le pide que emita tokens especiales para invocar el modelo basado en la suma para realizar los pasos aritméticos. Extraemos las consultas entre tokens, las enviamos al modelo de suma y devolvemos la respuesta al primer modelo, después de lo cual el primer modelo continúa su salida. Evaluamos nuestro enfoque frente a un problema difícil de GSM8k (GSM8k-Hard), donde seleccionamos al azar 50 preguntas de suma pura y aumentamos los valores numéricos en las preguntas.
 |
| Un ejemplo del conjunto de datos duros GSM8k. El mensaje de la cadena de pensamiento se complementa con paréntesis para indicar cuándo ejecutar una llamada algorítmica. |
Creemos que utilizar contextos y modelos separados con indicaciones especiales es una forma eficaz de manejar GSM8k con dificultad. A continuación encontramos que el rendimiento del modelo con la llamada algorítmica a la suma es 2,3 veces la línea base de la cadena de pensamiento. Finalmente, esta estrategia proporciona un ejemplo de resolución de tareas complejas al facilitar las interacciones entre LLM especializados en diferentes habilidades a través del aprendizaje contextual.
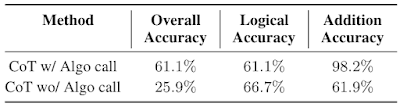 |
| Rendimiento de cadena de pensamiento (CoT) en GSM8k con o sin llamadas algorítmicas. |
Diploma
Presentamos un enfoque que utiliza el aprendizaje contextual y una novedosa técnica de estimulación algorítmica para desbloquear habilidades de razonamiento algorítmico en LLM. Nuestros resultados sugieren que podría ser posible transformar un contexto más extenso en un mejor desempeño del razonamiento al proporcionar explicaciones más detalladas. Por lo tanto, estos resultados sugieren la posibilidad de utilizar o simular contextos prolongados y generar justificaciones más significativas como direcciones de investigación prometedoras.
gracias
Gracias a nuestros coautores Behnam Neyshabur, Azade Nova, Hugo Larochelle y Aaron Courville por sus valiosas contribuciones al artículo y sus excelentes comentarios en el blog. Crédito a Tom Small por crear las animaciones en esta publicación. Este trabajo fue creado durante la pasantía de Hattie Zhou en Google Research.
[ad_2]