[ad_1]

Comprender la calidad estética y técnica de las imágenes es importante para brindar al usuario una mejor experiencia visual. La evaluación de la calidad de la imagen (IQA) utiliza modelos para proporcionar un puente entre una imagen y la percepción subjetiva del usuario de su calidad. En la era del aprendizaje profundo, muchos enfoques de IQA, como NIMA, han tenido éxito al aprovechar el poder de las redes neuronales convolucionales (CNN). Sin embargo, los modelos IQA basados en CNN a menudo están limitados por el requisito de entrada de tamaño fijo en el entrenamiento por lotes, es decir Las imágenes de entrada deben cambiarse de tamaño o recortarse a una forma de tamaño fijo. Este procesamiento previo es problemático para IQA porque las imágenes pueden tener resoluciones y proporciones de aspecto muy diferentes. Cambiar el tamaño y recortar puede afectar la composición de la imagen o introducir distorsiones que alteran la calidad de la imagen.
 |
| En los modelos basados en CNN, las imágenes se deben cambiar de tamaño o recortar a una forma fija para el entrenamiento por lotes. Sin embargo, dicho procesamiento previo puede cambiar la relación de aspecto y la composición de la imagen, afectando así la calidad de la imagen. Imagen original utilizada bajo licencia CC BY 2.0. |
En MUSIQ: Transformador de calidad de imagen multiescala, lanzado en ICCV 2021, proponemos un Transformador de calidad de imagen multiescala (MUSIQ) basado en parches para evitar las limitaciones de tamaño de entrada fijo de CNN y mejorar la calidad de imagen en imágenes de resolución nativa. El modelo MUSIQ admite el procesamiento de entradas de imagen de tamaño completo con diferentes relaciones de aspecto y resoluciones, y permite la extracción de características en múltiples escalas para capturar la calidad de la imagen en diferentes granularidades. Para admitir la codificación posicional en la representación multiescala, proponemos una novedosa incrustación espacial 2D basada en hash en combinación con una incrustación que captura la escala de la imagen. Aplicamos MUSIQ a cuatro grandes conjuntos de datos IQA y demostramos resultados consistentes de última generación en tres conjuntos de datos de calidad técnica (PaQ-2-PiQ, KonIQ-10k y SPAQ) y un rendimiento comparable al de última generación. modelos en el conjunto de datos de calidad estética AVA.
 |
| El modelo MUSIQ basado en parches puede procesar la imagen de tamaño completo y extraer características de múltiples escalas que se adaptan mejor a la respuesta visual típica de una persona. |
En la siguiente figura, mostramos una selección de imágenes, su calificación MUSIQ y su calificación de opinión media (MOS) de varios evaluadores humanos entre paréntesis. La puntuación va de 0 a 100, siendo 100 la calidad percibida más alta. Como podemos ver en la figura, MUSIQ predice puntajes altos para imágenes con alta calidad estética y alta calidad técnica, y puntajes bajos para imágenes que no son estéticamente agradables (baja calidad estética) o que contienen distorsiones visibles (baja calidad técnica). .
| Puntuación MUSIQ pronosticada (y verdad sobre el terreno) en imágenes del conjunto de datos KonIQ-10k. Arriba: MUSIQ predice puntajes altos para imágenes de alta calidad. Centro: MUSIQ predice puntajes bajos para imágenes con baja calidad estética, p. B. Imágenes con mala composición o iluminación. Abajo: MUSIQ predice puntajes bajos para imágenes de baja calidad técnica, como imágenes con artefactos de distorsión visibles (por ejemplo, borrosas, ruidosas). |
El transformador de calidad de imagen multiescala
MUSIQ asume el desafío de aprender IQA usando imágenes de tamaño completo. A diferencia de los modelos CNN, que a menudo se limitan a una resolución fija, MUSIQ puede manejar entradas de cualquier relación de aspecto y resolución.
Para lograr esto, primero creamos una representación multiescala de la imagen de entrada, que contiene la imagen de resolución nativa y sus variantes redimensionadas. Para preservar la composición de la imagen, mantenemos la relación de aspecto durante el cambio de tamaño. Una vez obtenida la pirámide de imágenes, dividimos las imágenes a diferentes escalas en parches de tamaño fijo que se introducen en el modelo.
 |
| Ilustración de la visualización de imágenes multiescala en MUSIQ. |
Debido a que los parches provienen de imágenes con diferentes resoluciones, debemos codificar efectivamente la entrada de múltiples escalas y relaciones de aspecto múltiples en una secuencia de tokens que capturan tanto el píxel como la información espacial y de escala. Para lograr esto, diseñamos tres componentes de codificación en MUSIQ, que incluyen: 1) un módulo de codificación de parches para codificar parches extraídos de la representación multiescala; 2) un novedoso módulo de incrustación espacial basado en hash para codificar la posición espacial 2D para cada parche; y 3) una incrustación de escala aprendible para codificar diferentes escalas. Esto nos permite codificar efectivamente la entrada multiescala como una secuencia de tokens que sirven como entrada al codificador del Transformador.
Para predecir la calificación de calidad de imagen final, utilizamos el enfoque estándar, que antepone un «token de clasificación» (CLS) adicional que se puede aprender. El estado del token CLS en la salida del codificador Transformer sirve como representación final de la imagen. Luego agregamos una capa completamente conectada en la parte superior para predecir el IQS. La siguiente figura ofrece una descripción general del modelo MUSIQ.
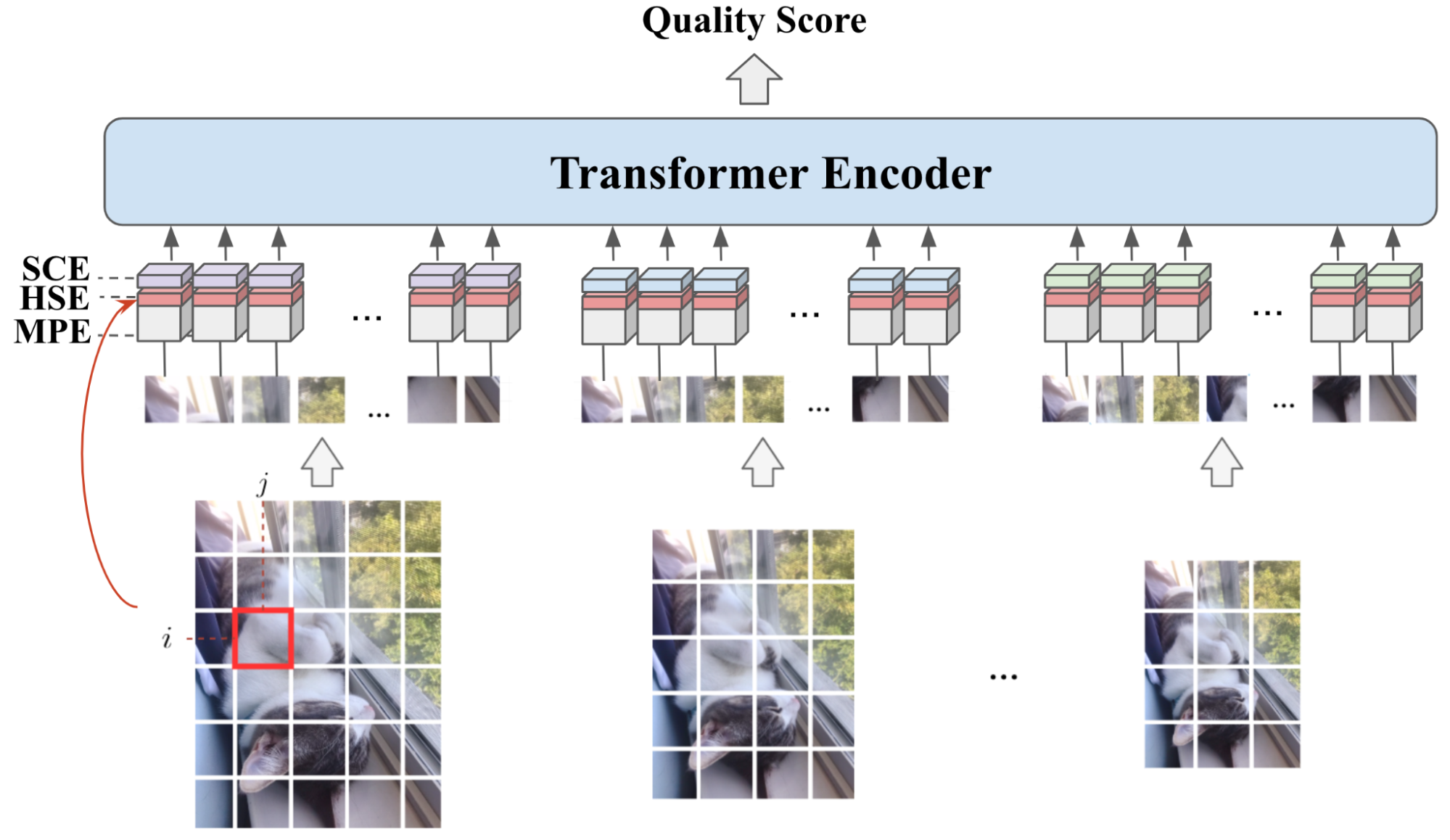 |
| Descripción general de MUSIQ. La entrada multiescala y multiresolución está codificada por tres componentes: incrustación de escala (SCE), incrustación espacial 2D basada en hash (HSE) e incrustación de parches multiescala (MPE). |
Dado que MUSIQ solo cambia la codificación de entrada, es compatible con todas las variantes de Transformer. Para demostrar la efectividad del método propuesto, en nuestros experimentos usamos el transformador clásico con una configuración relativamente ligera, por lo que el tamaño del modelo es comparable a ResNet-50.
punto de referencia y evaluación
Para evaluar MUSIQ, realizamos experimentos en varios conjuntos de datos IQA grandes. Para cada conjunto de datos, informamos el coeficiente de correlación de rango de Spearman (SRCC) y el coeficiente de correlación lineal de Pearson (PLCC) entre nuestra predicción del modelo y la puntuación de opinión media de los evaluadores humanos. SRCC y PLCC son métricas de correlación que van de -1 a 1. Un PLCC y un SRCC más altos significan una mejor coincidencia entre la predicción del modelo y la evaluación humana. El siguiente gráfico muestra que MUSIQ supera a otros métodos en PaQ-2-PiQ, KonIQ-10k y SPAQ.
 |
| Comparación de rendimiento de MUSIQ y métodos anteriores de última generación (SOTA) en cuatro grandes conjuntos de datos IQA. En cada conjunto de datos, comparamos el coeficiente de correlación de rangos de Spearman (SRCC) y el coeficiente de correlación lineal de Pearson (PLCC) de la predicción del modelo y la realidad fundamental. |
En particular, el conjunto de prueba PaQ-2 PiQ consiste completamente en imágenes grandes con al menos una dimensión mayor a 640 píxeles. Este es un desafío importante para los enfoques tradicionales de aprendizaje profundo que requieren un cambio de tamaño. MUSIQ puede superar a los métodos anteriores en el conjunto de pruebas de tamaño completo por un múltiplo, lo que confirma su solidez y eficacia.
También vale la pena señalar que los métodos anteriores basados en CNN a menudo requerían el muestreo de hasta 20 cultivos para cada cuadro durante la prueba. Este tipo de conjunto de cultivos múltiples es una forma de aliviar la restricción de forma fija en los modelos CNN. Sin embargo, dado que cada sección es solo una vista parcial de la imagen general, el conjunto sigue siendo una aproximación aproximada. Además, los métodos basados en CNN agregan costos de inferencia adicionales para cada cultivo y, dado que toman muestras de diferentes cultivos, pueden introducir aleatoriedad en el resultado. Por el contrario, dado que MUSIQ toma la imagen de tamaño completo como entrada, puede aprender directamente la mejor agregación de información sobre la imagen completa y solo necesita realizar la inferencia una vez.
Para verificar aún más que el modelo MUSIQ captura información diferente en diferentes escalas, visualizamos los pesos de atención en cada imagen en diferentes escalas.
 |
| Visualización de atención desde los tokens de salida hasta la representación multiescala, incluida la imagen de resolución original y dos imágenes modificadas proporcionalmente. Las áreas más claras indican una mayor atención, lo que significa que estas áreas son más importantes para la salida del modelo. Las imágenes ilustrativas son del conjunto de datos AVA. |
Observamos que MUSIQ tiende a centrarse en áreas más detalladas en las imágenes completas de alta resolución y en áreas más globales en las imágenes reducidas. Por ejemplo, en la foto de la flor de arriba, la atención del modelo se enfoca en los detalles del pedal en la imagen original, y la atención cambia a los capullos en resoluciones más bajas. Esto muestra que el modelo está aprendiendo a capturar calidad de imagen en diferentes granularidades.
Conclusión
Proponemos un Transformador de calidad de imagen de escala múltiple (MUSIQ) que puede manejar entradas de imagen de tamaño completo con diferentes resoluciones y relaciones de aspecto. Al transformar la imagen de entrada en una representación multiescala con vistas globales y locales, el modelo puede capturar la calidad de la imagen en diferentes granularidades. Aunque MUSIQ se desarrolló para IQA, se puede aplicar a otros escenarios donde las etiquetas de tareas son sensibles a la resolución de la imagen y la relación de aspecto. El modelo MUSIQ y los puntos de control están disponibles en nuestro repositorio de GitHub.
Gracias
Este trabajo es posible gracias a la colaboración entre varios equipos de Google. Nos gustaría reconocer las contribuciones de Qifei Wang, Yilin Wang y Peyman Milanfar.
[ad_2]