[ad_1]
Los modelos de aprendizaje profundo han logrado avances impresionantes en la visión, el habla y otras modalidades, particularmente con la llegada del entrenamiento previo a gran escala. Dichos modelos son más precisos cuando se aplican a datos de prueba que provienen de la misma distribución que su conjunto de entrenamiento. Sin embargo, en la práctica, los datos que enfrentan los modelos en entornos del mundo real rara vez coinciden con la distribución de entrenamiento. Además, es posible que los modelos no sean adecuados para aplicaciones en las que el rendimiento de la predicción es solo una parte de la ecuación. Para que los modelos sean confiables cuando se implementan, deben poder adaptarse a los cambios en la distribución de datos y tomar decisiones útiles en una variedad de escenarios.
En Plex: Towards Reliability Using Pre-trained Large Model Extensions, presentamos un marco para Aprendizaje profundo confiable como una nueva perspectiva sobre las habilidades de un modelo; Esto incluye un conjunto de tareas y conjuntos de datos concretos para evaluar la confiabilidad del modelo. También presentamos Plex, un conjunto de extensiones preentrenadas para modelos grandes que se pueden aplicar a muchas arquitecturas diferentes. Ilustramos la efectividad de Plex en los dominios de visión y voz al aplicar estas mejoras a los modelos Vision Transformer y T5 de última generación, lo que resulta en una mejora significativa en su confiabilidad. También estamos lanzando el código como código abierto para fomentar una mayor exploración de este enfoque.
 |
| incertidumbre — Clasificador de perros contra gatos: Plex puede decir «No sé» para entradas que no son ni gato ni perro. Generalización robusta — Un modelo ingenuo es sensible a correlaciones falsas («Objetivo»), mientras que Plex es robusto. ajustamiento — Plex puede seleccionar activo los datos a partir de los cuales aprende a mejorar el rendimiento más rápido. |
marco para la confiabilidad
Primero, examinamos cómo comprender la confiabilidad de un modelo en escenarios novedosos. Establecemos tres categorías generales de requisitos para sistemas confiables de aprendizaje automático (ML): (1) Deben informar con precisión las incertidumbres sobre sus predicciones («saber lo que no sabes»); (2) deberían generalizarse sólidamente a nuevos escenarios (cambio de distribución); y (3) deberían poder adaptarse de manera eficiente a los nuevos datos (adaptación). Es importante destacar que un modelo confiable debe aspirar a funcionar bien Todo el mundo de estas áreas simultáneamente sin tener que adaptarse a tareas individuales.
- incertidumbre refleja la información incompleta o desconocida que dificulta que un modelo haga predicciones precisas. La cuantificación de la incertidumbre predictiva permite que un modelo calcule decisiones óptimas y ayuda a los profesionales a saber cuándo confiar en las predicciones del modelo, lo que permite errores elegantes cuando es probable que el modelo esté equivocado.
- Generalización robusta implica una estimación o pronóstico de un evento no visto. Examinamos cuatro tipos de datos fuera de distribución: cambio de covariable (cuando la distribución de entrada cambia entre el entrenamiento y la aplicación y la distribución de salida permanece sin cambios), cambio semántico (o de clase), incertidumbre de etiqueta y cambio de subpoblación.
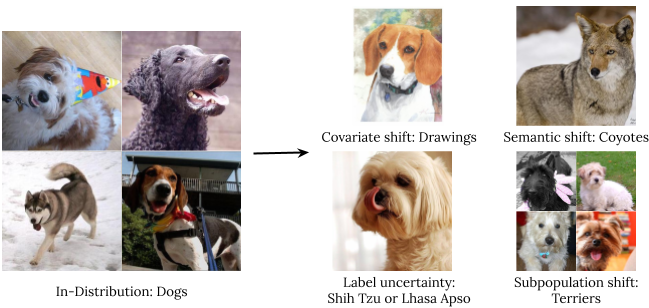
Los tipos de distribución están cambiando con una ilustración de los perros de ImageNet. - ajustamiento se refiere a probar las capacidades del modelo en el curso de su proceso de aprendizaje. Los puntos de referencia generalmente se evalúan en conjuntos de datos estáticos con divisiones de prueba de tren predefinidas. Sin embargo, en muchas aplicaciones estamos interesados en modelos que puedan adaptarse rápidamente a nuevos conjuntos de datos y aprender de manera eficiente con la menor cantidad posible de ejemplos etiquetados.
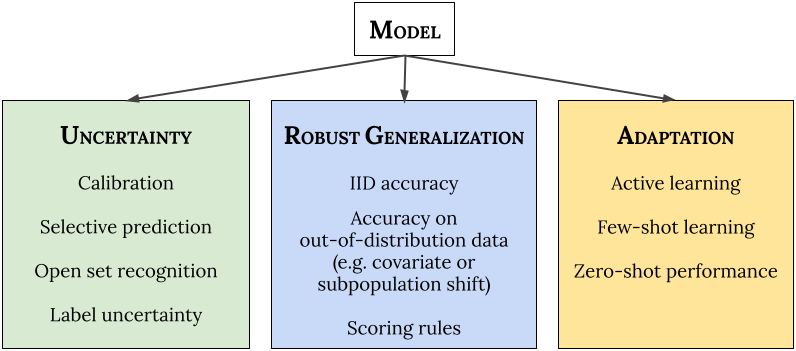 |
| marco de confiabilidad. Proponemos probar simultáneamente el rendimiento del modelo listo para usar (es decir, la distribución predictiva) a través de la incertidumbre, la generalización robusta y los puntos de referencia de ajuste, sin ajustes para tareas individuales. |
Aplicamos 10 tipos de tareas para capturar los tres dominios de confiabilidad (incertidumbre, generalización robusta y ajuste) y nos aseguramos de que las tareas midan un conjunto diverso de propiedades deseables en cada dominio. Juntas, las tareas incluyen 40 conjuntos de datos posteriores para las modalidades de visión y lenguaje natural: 14 conjuntos de datos para el ajuste fino (incluidas menos exposiciones y ajuste activo basado en el aprendizaje) y 26 conjuntos de datos para la evaluación fuera de distribución.
Plex: extensiones de modelos grandes preentrenadas para la visión y el habla
Para mejorar la confiabilidad, estamos desarrollando ViT-Plex y T5-Plex, que se basan en grandes modelos de visión preentrenada (ViT) y habla (T5), respectivamente. Una característica clave de Plex es una composición más eficiente basada en submodelos, cada uno de los cuales hace una predicción que luego se agrega. Además, Plex intercambia la última capa lineal de cada arquitectura con un proceso gaussiano o una capa heteroscedástica para representar mejor la incertidumbre de la predicción. Se ha encontrado que estas ideas funcionan muy bien para modelos entrenados desde cero en la escala de ImageNet. Entrenamos los modelos con diferentes tamaños de hasta 325 millones de parámetros para la visión (ViT-Plex L) y mil millones de parámetros para el habla (T5-Plex L) y conjuntos de datos de preentrenamiento con hasta 4 mil millones de ejemplos.
La siguiente figura ilustra el rendimiento de Plex en tareas seleccionadas en comparación con el estado actual de la técnica. El modelo de mejor rendimiento para cada tarea suele ser un modelo especializado que está altamente optimizado para ese problema. Plex alcanza un nuevo nivel de tecnología con muchos de los 40 conjuntos de datos. Es importante destacar que, con la salida del modelo lista para usar, Plex ofrece un rendimiento sólido para cualquier tarea sin la necesidad de un diseño personalizado o ajuste para cada tarea.
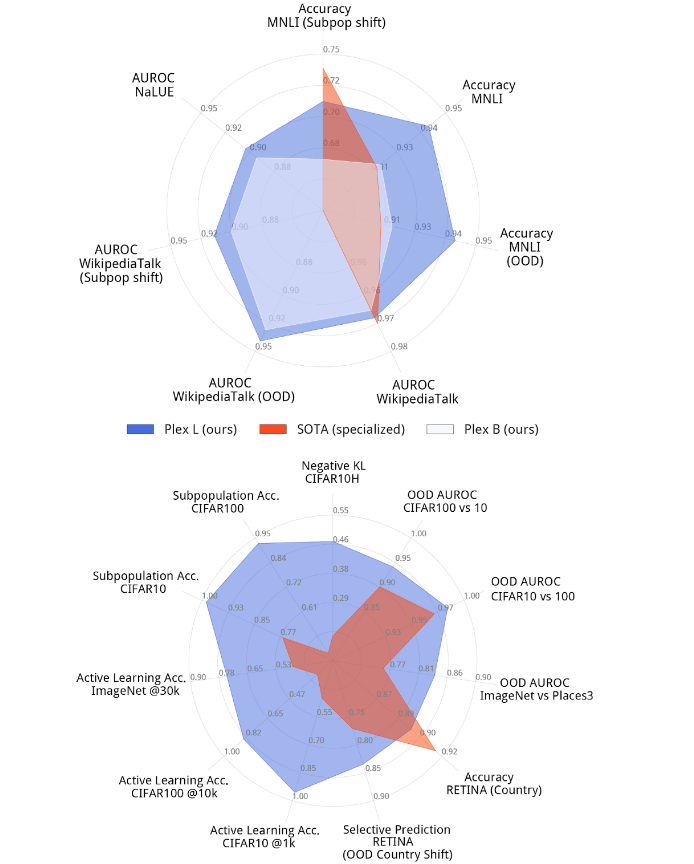 |
| El complejo T5 más grande (arriba) y ViT Plex (abajo) modelos evaluados contra modelos especializados de última generación utilizando un conjunto destacado de tareas de confiabilidad. Los radios indican diferentes tareas y cuantifican el rendimiento de las métricas para diferentes conjuntos de datos. |
Plex en acción para varias tareas de confiabilidad
Destacamos la confiabilidad de Plex en tareas seleccionadas a continuación.
Detección de conjunto abierto
Mostramos la salida de Plex cuando el modelo tiene que diferir la predicción porque la entrada es una que el modelo no admite. Esta tarea se denomina detección de conjuntos abiertos. Aquí, el rendimiento de la predicción es parte de un escenario de toma de decisiones más amplio en el que el modelo puede renunciar a ciertas predicciones. En la siguiente figura mostramos estructurado Detección de conjunto abierto: Plex devuelve múltiples salidas y señala la parte específica de la salida sobre la cual el modelo es incierto y probablemente no distribuido.
 |
| La detección estructurada de conjuntos abiertos permite que el modelo proporcione una aclaración matizada. Aquí, T5-Plex L puede detectar casos detallados fuera de distribución en los que se admite la vertical de la solicitud (es decir, dominio de servicio grueso como banca, medios, productividad, etc.) y el dominio, pero no la intención. soportado. |
etiqueta de incertidumbre
En conjuntos de datos reales, a menudo hay una ambigüedad inherente detrás de la etiqueta de verdad básica para cada entrada. Esto puede ocurrir, por ejemplo, debido a la ambigüedad del evaluador humano para una imagen determinada. En este caso, queremos que el modelo capture la distribución completa de la incertidumbre perceptual humana. Mostramos Plex a continuación usando ejemplos de una variante de ImageNet que construimos y que proporciona una distribución de etiquetas de verdad.
 |
| Plex para la incertidumbre de la etiqueta. Usando un conjunto de datos que creamos llamado ImageNet ReaL-H, ViT-Plex L demuestra la capacidad de capturar la ambigüedad inherente (distribución de probabilidad) de las etiquetas de imagen. |
aprendizaje activo
Examinamos la capacidad de un modelo grande no solo para aprender sobre un conjunto fijo de puntos de datos, sino también para participar en saber de qué puntos de datos aprender en primer lugar. Tal tarea se conoce como aprendizaje activo, donde en cada paso de entrenamiento el modelo selecciona entradas prometedoras para entrenar a partir de un grupo de puntos de datos no etiquetados. Este procedimiento evalúa la eficiencia de etiquetado de un modelo de ML donde las anotaciones de etiquetado pueden ser escasas y, por lo tanto, queremos maximizar el rendimiento y minimizar la cantidad de puntos de datos etiquetados que se utilizan. Plex logra un aumento significativo en el rendimiento sobre la arquitectura del mismo modelo sin capacitación previa. Además, incluso con menos muestras de entrenamiento, supera al método BASE preentrenado de última generación, que logra una precisión del 63 % en 100 000 muestras.
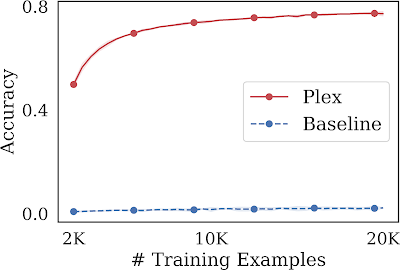 |
| Aprendizaje activo en ImageNet1K. ViT-Plex L es muy eficiente con las etiquetas en comparación con una línea de base que no usa entrenamiento previo. También encontramos que la estrategia de recopilación de datos de aprendizaje activo es más efectiva que la selección aleatoria uniforme de puntos de datos. |
Aprende más
Vea nuestro documento aquí y una próxima publicación sobre cómo trabajar en el taller de capacitación previa de ICML 2022 el 23 de julio de 2022. Para fomentar una mayor investigación en esta dirección, proporcionamos todo el código para el entrenamiento y la puntuación como parte de las líneas de base de incertidumbre. También proporcionamos una demostración que muestra cómo usar un punto de control del modelo ViT-Plex. Las implementaciones de capas y métodos utilizan Edward2.
Gracias
Agradecemos a todos los coautores por sus contribuciones al proyecto y la publicación, incluidos Andreas Kirsch, Clara Huiyi Hu, Du Phan, D. Sculley, Honglin Yuan, Jasper Snoek, Jeremiah Liu, Jie Ren, Joost van Amersfoort, Karan Singhal, Kehang Han, Kelly Buchanan, Kevin Murphy, Mark Collier, Mike Dusenberry, Neil Band, Nithum Thain, Rodolphe Jenatton, Tim GJ Rudner, Yarin Gal, Zachary Nado, Zelda Mariet, Zi Wang y Zoubin Ghahramani. También agradecemos a Anusha Ramesh, Ben Adlam, Dilip Krishnan, Ed Chi, Neil Houlsby, Rif A. Saurous y Sharat Chikkerur por sus útiles comentarios, y a Tom Small y Ajay Nainani por su ayuda con las visualizaciones.
[ad_2]