
[ad_1]
La medicina es una disciplina inherentemente multimodal. En enfermería, los médicos interpretan habitualmente datos de una variedad de modalidades, incluidas imágenes médicas, notas clínicas, pruebas de laboratorio, registros médicos electrónicos, genómica y más. Durante la última década, los sistemas de IA han logrado un rendimiento de nivel experto en determinadas tareas. dentro de especifico Modalidades: algunos sistemas de IA procesan tomografías computarizadas, mientras que otros analizan diapositivas patológicas con gran aumento y otros buscan variaciones genéticas raras. Las entradas a estos sistemas suelen ser datos complejos, como imágenes, y suelen proporcionar salidas estructuradas, ya sea en forma de grados discretos o máscaras de segmentación de imágenes densas. Paralelamente, las capacidades y habilidades de los Modelos de Lenguaje Grande (LLM) han avanzado hasta el punto en que han demostrado comprensión y experiencia en conocimientos médicos a través de interpretación y respuestas en lenguaje sencillo. Pero, ¿cómo reunimos estas habilidades para desarrollar sistemas médicos de inteligencia artificial que puedan utilizar su información? todo estas fuentes?
En la publicación de blog de hoy, describimos un espectro de enfoques para brindar a los LLM capacidades multimodales y compartimos algunos resultados interesantes sobre la viabilidad de crear LLM médicos multimodales, como se describe en tres artículos de investigación recientes. Los artículos, a su vez, establecen cómo debe realizarse la introducción. de novo Modalidades de un LLM, cómo transferir un modelo fundamental de imágenes médicas de última generación a un LLM conversacional y los primeros pasos para construir un sistema de IA médica multimodal verdaderamente generalista. Si se desarrollan con éxito, los LLM médicos multimodales podrían servir como base para nuevas tecnologías de asistencia en medicina profesional, investigación médica y aplicaciones para el consumidor. Al igual que con nuestro trabajo anterior, enfatizamos la necesidad de una evaluación cuidadosa de estas tecnologías en colaboración con la comunidad médica y el ecosistema de atención médica.
Una variedad de enfoques
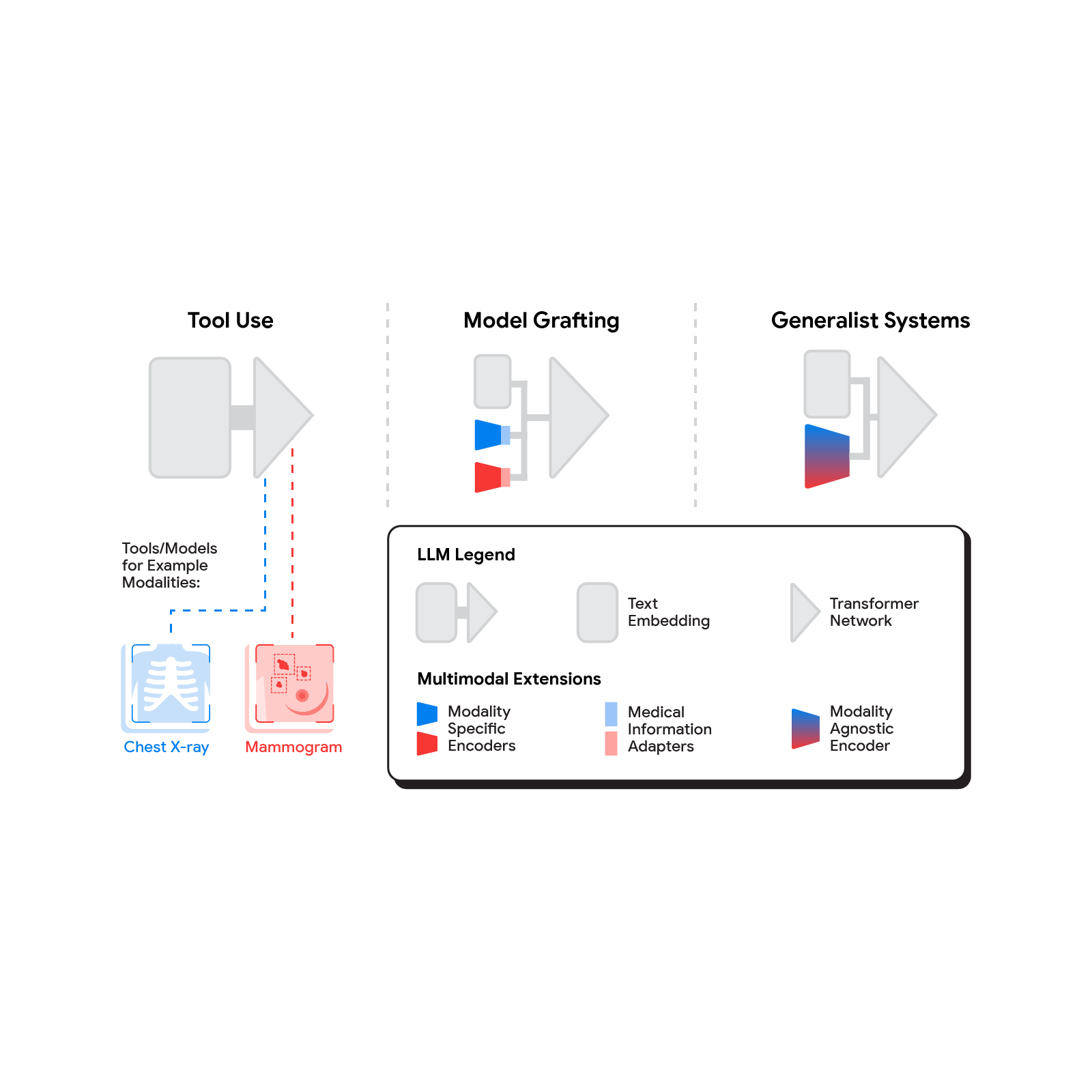
En los últimos meses se han propuesto varios métodos para construir LLM multimodales. [1, 2, 3], y sin duda seguirán surgiendo nuevos métodos durante algún tiempo. Para comprender las posibilidades de introducir nuevas modalidades en los sistemas de IA médica, consideramos tres enfoques ampliamente definidos: uso de herramientas, trasplante de modelos y sistemas generalistas.
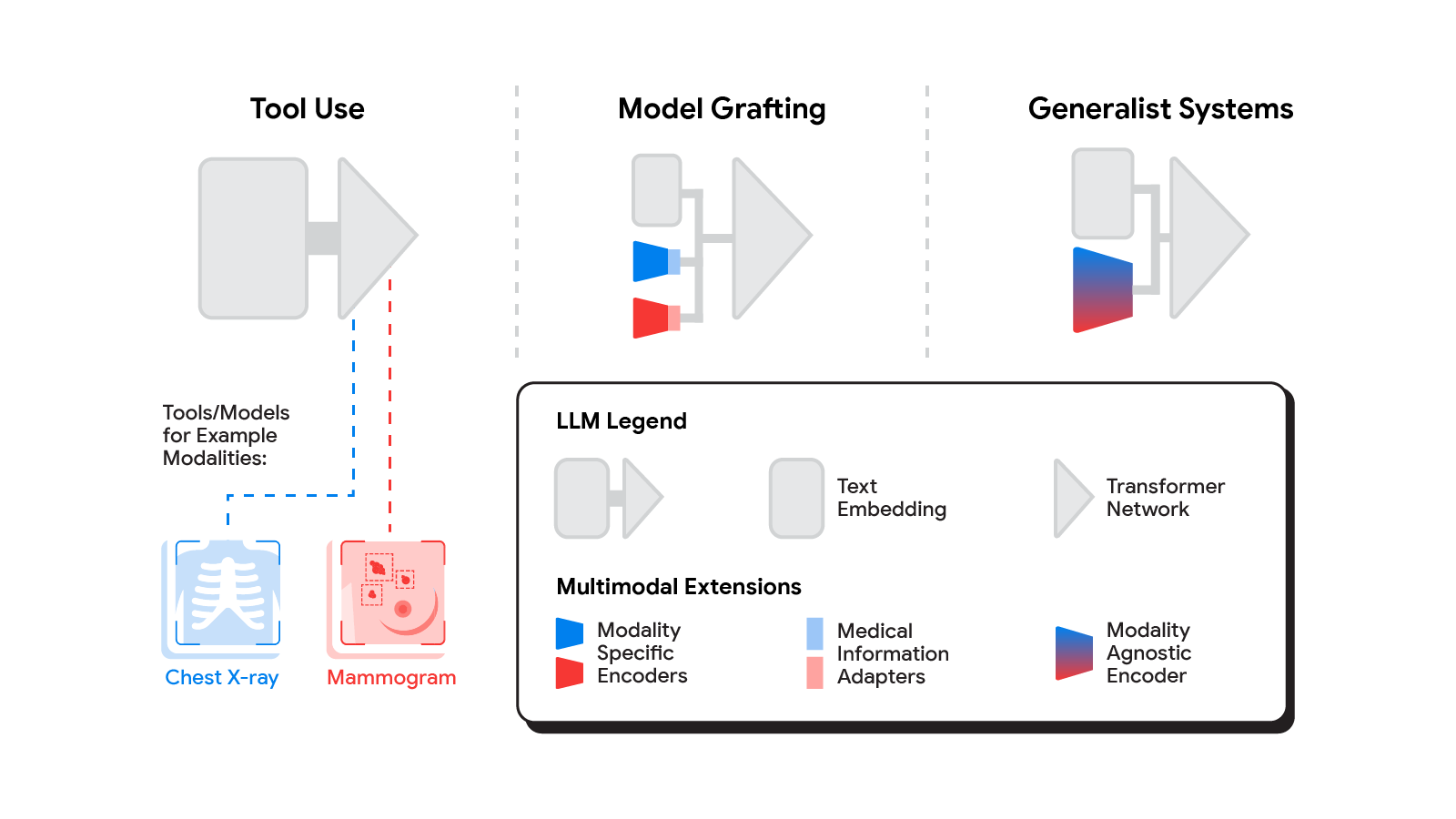 |
| El espectro de enfoques para construir LLM multimodales abarca desde el uso de herramientas o modelos existentes por parte del LLM hasta el uso de componentes de dominio específico con un adaptador para el modelado conjunto de un modelo multimodal. |
uso de herramientas
En el uso de herramientas En este enfoque, un LLM médico central subcontrata el análisis de datos en diferentes modalidades a un conjunto de subsistemas de software que están optimizados de forma independiente para estas tareas: las herramientas. El ejemplo mnemotécnico común del uso de herramientas es enseñar a un LLM a usar una calculadora en lugar de hacer matemáticas por su cuenta. En el campo de la medicina, a un LLM médico al que se le presente una radiografía de tórax podría enviar esa imagen a un sistema de IA radiológico e integrar esa respuesta. Esto podría lograrse mediante interfaces de programación de aplicaciones (API) ofrecidas por subsistemas o, de manera más imaginativa, dos sistemas médicos de IA con diferentes especializaciones participando en una conversación.
Este enfoque tiene algunas ventajas importantes. Permite la máxima flexibilidad e independencia entre subsistemas, lo que permite a los sistemas de atención médica mezclar y combinar productos entre proveedores de tecnología en función de características de rendimiento de subsistemas validadas. Además, los canales de comunicación legibles por humanos entre subsistemas maximizan la capacidad de prueba y depuración. Sin embargo, puede resultar difícil lograr una buena comunicación entre subsistemas independientes, limitar la transferencia de información o conllevar el riesgo de malentendidos y pérdida de información.
refinamiento del modelo
Un enfoque más integrado sería adaptar una red neuronal especializada para cada dominio relevante para que pueda conectarse directamente al LLM. injerto el modelo visual sobre los agentes de razonamiento centrales. A diferencia del uso de herramientas, donde las herramientas específicas utilizadas las determina el LLM, en el trasplante de modelos los investigadores pueden optar por utilizar, perfeccionar o desarrollar modelos específicos durante el desarrollo. En dos artículos recientes de Google Research, demostramos que esto es realmente factible. Los LLM neuronales normalmente procesan el texto asignando primero palabras en un espacio de incrustación vectorial. Ambos trabajos se basan en la idea de mapear datos de una nueva modalidad en el espacio de incrustación de palabras de entrada ya conocido en el LLM. El primer artículo, «LLM multimodales para la salud basado en datos personales», muestra que la predicción del riesgo de asma en el Biobanco del Reino Unido se puede mejorar si primero entrenamos un clasificador de redes neuronales para interpretar espirogramas (una modalidad que se utiliza para evaluar la respirabilidad) y luego los ajustamos. la salida de esta red para que sirva como entrada al LLM.
El segundo artículo, «ELIXR: Hacia un sistema de inteligencia artificial de rayos X de propósito general mediante la alineación de modelos de lenguaje grandes y codificadores de visión radiológica», adopta el mismo enfoque pero lo aplica a modelos de codificadores de imágenes completos en radiología. Partiendo de un modelo básico para la comprensión de las radiografías de tórax, que ya ha demostrado ser una buena base para construir una variedad de clasificadores en esta modalidad, este artículo describe cómo entrenar un peso ligero. Adaptador de información médica Esto expresa la salida del nivel superior del modelo base como un conjunto de tokens en el espacio de inserción de entrada del LLM. Aunque ni el codificador visual ni el modelo de lenguaje han sido sometidos a ningún ajuste, el sistema resultante muestra capacidades para las que no fue entrenado, incluida la búsqueda semántica y la respuesta visual a preguntas.
 |
| Nuestro enfoque para trasplantar un modelo funciona entrenando un adaptador de información médica que convierte la salida de un codificador de imágenes existente o refinado en un formato comprensible de LLM. |
El trasplante de modelos tiene una serie de ventajas. Requiere recursos computacionales relativamente modestos para entrenar las capas del adaptador, pero permite que el LLM se base en modelos existentes altamente optimizados y validados en cada dominio de datos. Modularizar el problema en componentes de codificador, adaptador y LLM también puede facilitar las pruebas y la depuración de componentes de software individuales al desarrollar e implementar dicho sistema. Las desventajas relacionadas son que la comunicación entre el codificador específico y el LLM ya no es legible por humanos (ya que es una serie de vectores de alta dimensión) y que el proceso de injerto no es solo para cada codificador de dominio específico, sino también para cada Necesito crear un nuevo adaptador. revisión cada uno de estos codificadores.
Sistemas generalistas
El enfoque más radical de la IA médica multimodal es construir un sistema integrado y totalmente generalizado que sea capaz de absorber información de todas las fuentes de forma nativa. En nuestro tercer artículo en esta área, Hacia la IA biomédica generalista, nos basamos en PaLM-E, un modelo multimodal publicado recientemente que es en sí mismo una combinación de un único LLM (PaLM) y un codificador de visión única (ViT). En esta configuración, las modalidades de texto y datos tabulares están cubiertas por el codificador de texto LLM, pero ahora todos los demás datos se tratan como una imagen y se envían al codificador de visión.
 |
| Med-PaLM M es un gran modelo generativo multimodal que codifica e interpreta de manera flexible datos biomédicos, incluido el lenguaje clínico, las imágenes y la genómica, con los mismos pesos del modelo. |
Especializamos PaLM-E en el ámbito médico refinando el conjunto completo de parámetros del modelo en conjuntos de datos médicos descritos en el artículo. El sistema de IA médica generalista resultante es una versión multimodal de Med-PaLM, que llamamos Med-PaLM M. La arquitectura flexible multimodal de secuencia a secuencia nos permite anidar diferentes tipos de información biomédica multimodal en una única interacción. Hasta donde sabemos, esta es la primera demostración de un modelo unificado único que puede interpretar datos biomédicos multimodales y manejar una variedad de tareas, todas usando el mismo conjunto de pesos del modelo (evaluaciones detalladas en el artículo).
Este enfoque sistémico generalista de la multimodalidad es al mismo tiempo el más ambicioso y el más elegante de los enfoques que hemos descrito. En principio, este enfoque directo maximiza la flexibilidad y la transferencia de información entre modalidades. Sin API para mantener la compatibilidad y sin proliferación de capas de adaptadores, el enfoque generalista es posiblemente el diseño más simple. Sin embargo, esa misma elegancia también es la raíz de algunas de sus desventajas. Los costos computacionales suelen ser más altos y, dado que un codificador de visión unificado cubre una amplia gama de modalidades, la especialización del dominio o la capacidad de depuración del sistema podrían verse afectadas.
La realidad de la IA médica multimodal
Para aprovechar al máximo la IA en medicina, debemos combinar el poder de los sistemas expertos entrenados con IA predictiva con la flexibilidad que permite la IA generativa. Qué enfoque (o combinación de enfoques) será más útil en esta área depende de una variedad de factores aún no evaluados. ¿Es la flexibilidad y simplicidad de un modelo generalista más valiosa que la modularidad de la propagación del modelo o el uso de herramientas? ¿Qué enfoque proporciona resultados de mayor calidad para un caso de uso determinado del mundo real? ¿Es diferente el enfoque preferido para apoyar la investigación médica o la educación médica de mejorar la práctica médica? Responder a estas preguntas requiere una investigación empírica rigurosa y continua y una colaboración directa continua con proveedores de atención médica, instituciones médicas, agencias gubernamentales y socios de la industria de la salud en general. Esperamos encontrar las respuestas juntos.
[ad_2]