[ad_1]
La gente no escribe como habla. El lenguaje escrito es controlado e intencional, mientras que las transcripciones de discursos improvisados (como entrevistas) son difíciles de leer porque el lenguaje es desorganizado y menos fluido. Un aspecto que dificulta particularmente la lectura de transcripciones de discursos es la fluidez, que incluye autocorrecciones, repeticiones y pausas completas (por ejemplo, palabras como «em«, y «Sabes»). El siguiente es un ejemplo de una oración hablada que contiene incertidumbres del corpus LDC CALLHOME:
Pero no lo es, no lo es, es, eh, es un juego de palabras con lo que acabas de decir.
Se necesita algo de tiempo para entender esta oración: el oyente tiene que filtrar las palabras superfluas y resolverlas todas. No. Eliminar las incertidumbres hace que la oración sea mucho más fácil de leer y comprender:
Pero es un juego de palabras con lo que acabas de decir.
Si bien las personas generalmente ni siquiera notan los trastornos del habla en las conversaciones cotidianas, los primeros trabajos preliminares en lingüística computacional han demostrado cuán comunes son. En 1994, utilizando el corpus Switchboard, Elizabeh Shriberg demostró que existe un 50% de probabilidad de que una oración de 10 a 13 palabras contenga falta de fluidez, y que la probabilidad aumenta con la longitud de la oración.
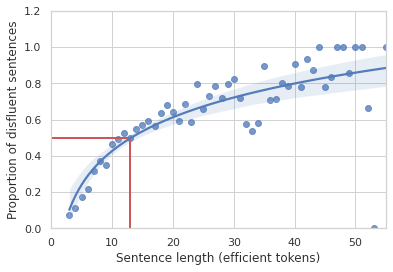 |
| La proporción de oraciones del conjunto de datos Switchboard con al menos una falta de fluidez trazada contra la longitud de la oración, medida en tokens no disfluentes (es decir, eficientes) en la oración. Cuanto más larga sea una oración, más probable es que contenga falta de fluidez. |
En «Enseñar a BERT a esperar: equilibrar la precisión y la latencia para la detección de falta de fluidez en la transmisión», presentamos una investigación sobre cómo «limpiar» las transcripciones del texto hablado. Creamos transcripciones y subtítulos en lenguaje humano más legibles al encontrar y eliminar las dificultades lingüísticas en el idioma de las personas. Usando datos etiquetados, hemos desarrollado algoritmos de aprendizaje automático (ML) que detectan caprichos en el habla humana. Una vez que se identifican, podemos eliminar las palabras adicionales para que las transcripciones sean más fáciles de leer. Esto también mejora el rendimiento de los algoritmos de procesamiento del lenguaje natural (NLP) que operan en las transcripciones del lenguaje humano. Nuestro trabajo pone especial énfasis en garantizar que estos modelos puedan ejecutarse en dispositivos móviles, para que podamos proteger la privacidad del usuario y preservar el rendimiento en escenarios de baja conectividad.
Resumen del modelo base
El núcleo de nuestro modelo base es un BERT pre-entrenadoBASE Codificador con 108,9 millones de parámetros. Usamos la configuración estándar de clasificación por token, alimentando un encabezado de clasificación binaria de las codificaciones de secuencia para cada token.
.png) |
| Ilustración de cómo los tokens en el texto se convierten en incrustaciones numéricas, que luego conducen a etiquetas de salida. |
Refinamos el codificador BERT al continuar con el entrenamiento previo en los comentarios del conjunto de datos Pushrift Reddit de 2019. Los comentarios de Reddit no son datos de idioma, pero son más informales y conversacionales que los datos de wiki y libros. Esto entrena al codificador para comprender mejor el habla informal, pero corre el riesgo de internalizar algunos de los sesgos inherentes a los datos. Sin embargo, para nuestro caso de uso particular, el modelo solo captura la sintaxis o la forma general del texto, no su contenido, lo que evita problemas potenciales relacionados con el sesgo de nivel semántico en los datos.
Refinamos nuestro modelo para la clasificación de disfluencia en corpus etiquetados a mano, como el corpus Switchboard mencionado anteriormente. Los hiperparámetros (tamaño del lote, tasa de aprendizaje, número de épocas de entrenamiento, etc.) se optimizaron con Vizier.
También producimos una gama de modelos «pequeños» para usar en dispositivos móviles utilizando una técnica de destilación de conocimientos conocida como «autoformación». Nuestro mejor modelo pequeño se basa en la variante Small Vocab BERT con 3,1 millones de parámetros. Este modelo más pequeño logra resultados comparables a nuestra línea de base al 1% del tamaño (en MiB). Puede leer más sobre cómo logramos esta miniaturización del modelo en nuestro artículo de Interspeech de 2021.
corriente
Algunos de los casos de uso más recientes para la transcripción automática de voz incluyen subtítulos en vivo automatizados, como los generados por la función Live Captions de Android, que transcribe automáticamente el lenguaje hablado en audio para reproducirlo en el dispositivo. Para que la eliminación de fluctuaciones sea útil en este entorno para mejorar la legibilidad de los subtítulos, debe ser rápida y estable. Es decir, el modelo no debería cambiar sus predicciones anteriores cuando ve nuevas palabras en la transcripción.
A esto lo llamamos procesamiento token por token en vivo. corriente. La transmisión precisa es difícil debido a las dependencias de tiempo; la mayoría de los líquidos no son reconocibles hasta más tarde. Por ejemplo, una repetición no se convierte en repetición hasta que la palabra o frase se dice por segunda vez.
Para examinar si nuestro modelo es efectivo para detectar disfluencias en las aplicaciones de transmisión, dividimos las expresiones en nuestro conjunto de entrenamiento en segmentos de prefijo, con solo el primero norte Se proporcionaron tokens del enunciado en el momento del entrenamiento para todos los valores de norte a la longitud total del enunciado. Evaluamos el modelo, que simula un flujo de texto hablado, alimentando prefijos a los modelos y midiendo el rendimiento usando múltiples métricas que capturan la precisión, la estabilidad y la latencia del modelo, incluida la transmisión F1, el tiempo de detección (TTD), el esfuerzo (EO ) y Tiempo medio de espera (AWT). Hemos experimentado con ventanas anticipadas de uno o dos tokens, lo que permite que el modelo «anticipe» tokens adicionales que el modelo no necesita predecir. Esencialmente, le estamos pidiendo al modelo que «espere» una o dos pruebas más antes de tomar una decisión.
Si bien agregar esta anticipación fija mejoró la estabilidad y la transmisión de resultados de F1 en muchos contextos, descubrimos que en algunos casos la etiqueta ya estaba clara incluso sin mirar el siguiente token, y el modelo no se benefició necesariamente de la espera. En otros casos, bastaba con esperar un token adicional. Presumimos que el modelo en sí podría aprender cuándo esperar más contexto. Nuestra solución fue una arquitectura de modelo modificada que incluye un encabezado de clasificación de «espera» que decide cuándo el modelo ha visto suficiente evidencia para confiar en el encabezado de clasificación de disfluencia.
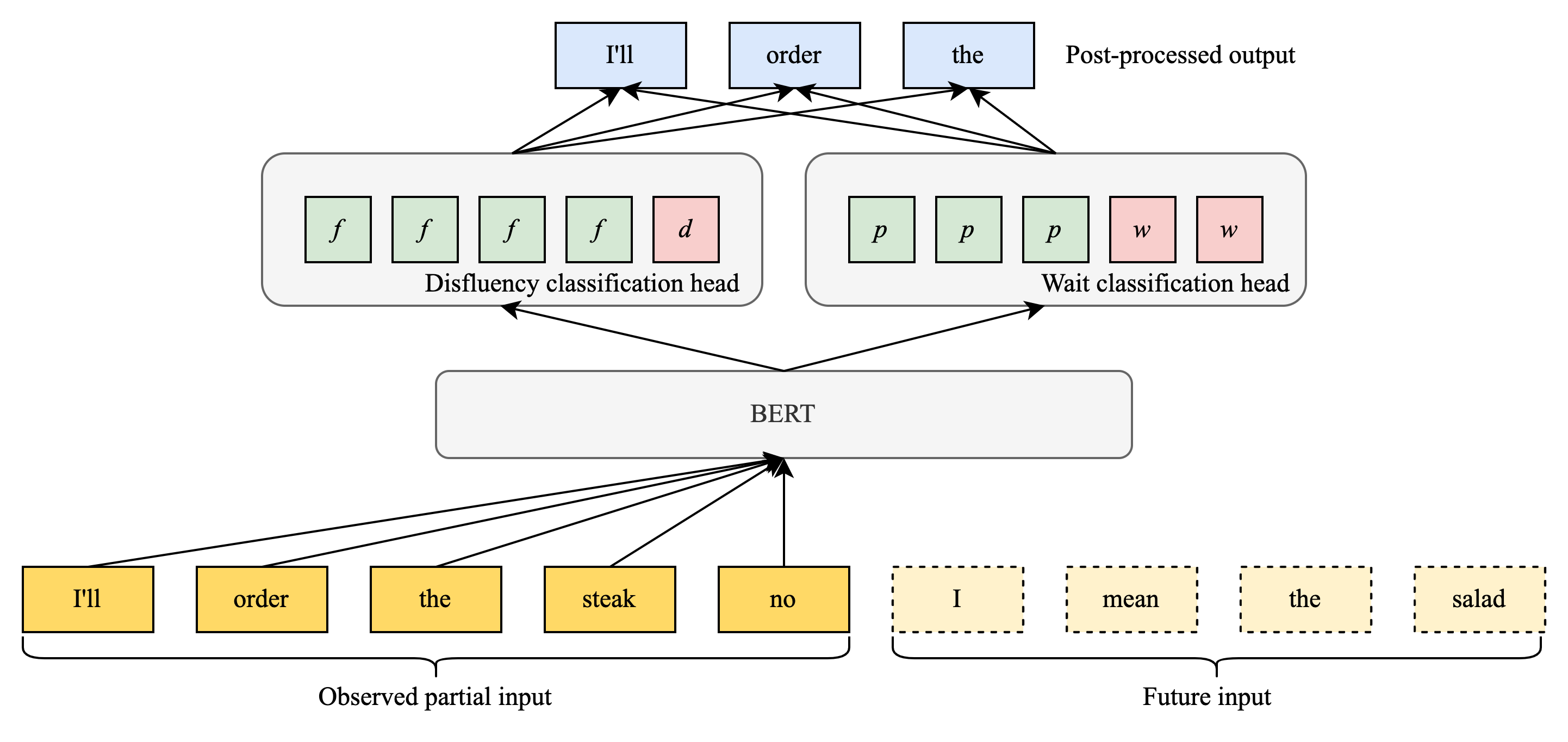 |
| Diagrama que muestra cómo el modelo etiqueta los tokens de entrada a medida que llegan. Las capas de incrustación BERT alimentan dos cabezales de binning separados que se combinan para la salida. |
Construimos una función de pérdida de entrenamiento que es una suma ponderada de tres factores:
- La pérdida de entropía cruzada tradicional para el encabezado de clasificación de disfluencia
- Un término de entropía cruzada que solo considera hasta el primer token con una clasificación de «espera»
- Una penalización de latencia que evita que el modelo espere demasiado para hacer una predicción
Evaluamos este modelo de transmisión, así como la línea de base predeterminada sin anticipación y con valores de anticipación de 1 y 2 tokens:
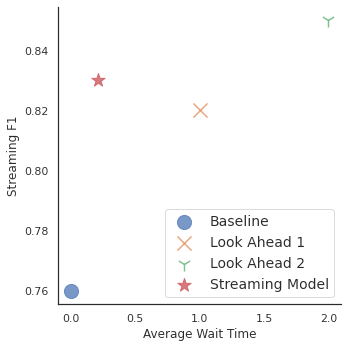 |
| Gráfico de la puntuación de transmisión de F1 frente al tiempo de espera promedio en tokens. Tres puntos de datos indican valores de F1 superiores a 0,82 durante múltiples tiempos de espera. El modelo de transmisión propuesto logra un rendimiento casi máximo con latencias mucho más cortas que los modelos fijos de anticipación. |
El modelo de transmisión logró una mejor puntuación de transmisión de F1 que una línea de base estándar sin anticipación y un modelo con una anticipación de 1. Funcionó casi tan bien como la variante con una anticipación fija de 2, pero con mucho menos tiempo de espera. En promedio, el modelo solo esperó 0,21 tokens de contexto.
internacionalización
Hemos tenido nuestros mejores resultados hasta ahora con las transcripciones en inglés. Esto se debe principalmente a problemas de recursos: si bien hay una cantidad relativamente grande de conjuntos de datos de conversación etiquetados que contienen ignorancia del inglés, muy pocos de estos conjuntos de datos suelen estar disponibles para otros idiomas. Por lo tanto, para que los modelos estén disponibles para detectar el dominio del idioma fuera del inglés, se necesita un método para construir modelos de una manera que no requiera encontrar y etiquetar cientos de miles de expresiones en cada idioma de destino. Una solución prometedora es usar versiones multilingües de BERT para transferir lo que un modelo ha aprendido sobre la incompetencia en inglés a otros idiomas para lograr un rendimiento similar con muchos menos datos. Esta es un área de investigación activa, pero tenemos algunos resultados prometedores para esbozar aquí.
Como primer intento de validar este enfoque, agregamos etiquetas a unas 10 000 líneas de diálogo del conjunto de datos alemán CALLHOME. Luego comenzamos con el modelo BERT bilingüe en inglés y alemán de Geotrend (extraído de BERT multilingüe) y lo comparamos con aproximadamente 77 000 ejemplos etiquetados como disfluencia en English Switchboard y 1,3 millones de ejemplos con transcripciones autoetiquetadas del Fisher Corpus refinado. Luego hicimos más ajustes con alrededor de 7500 ejemplos etiquetados internamente del conjunto de datos alemán CALLHOME.
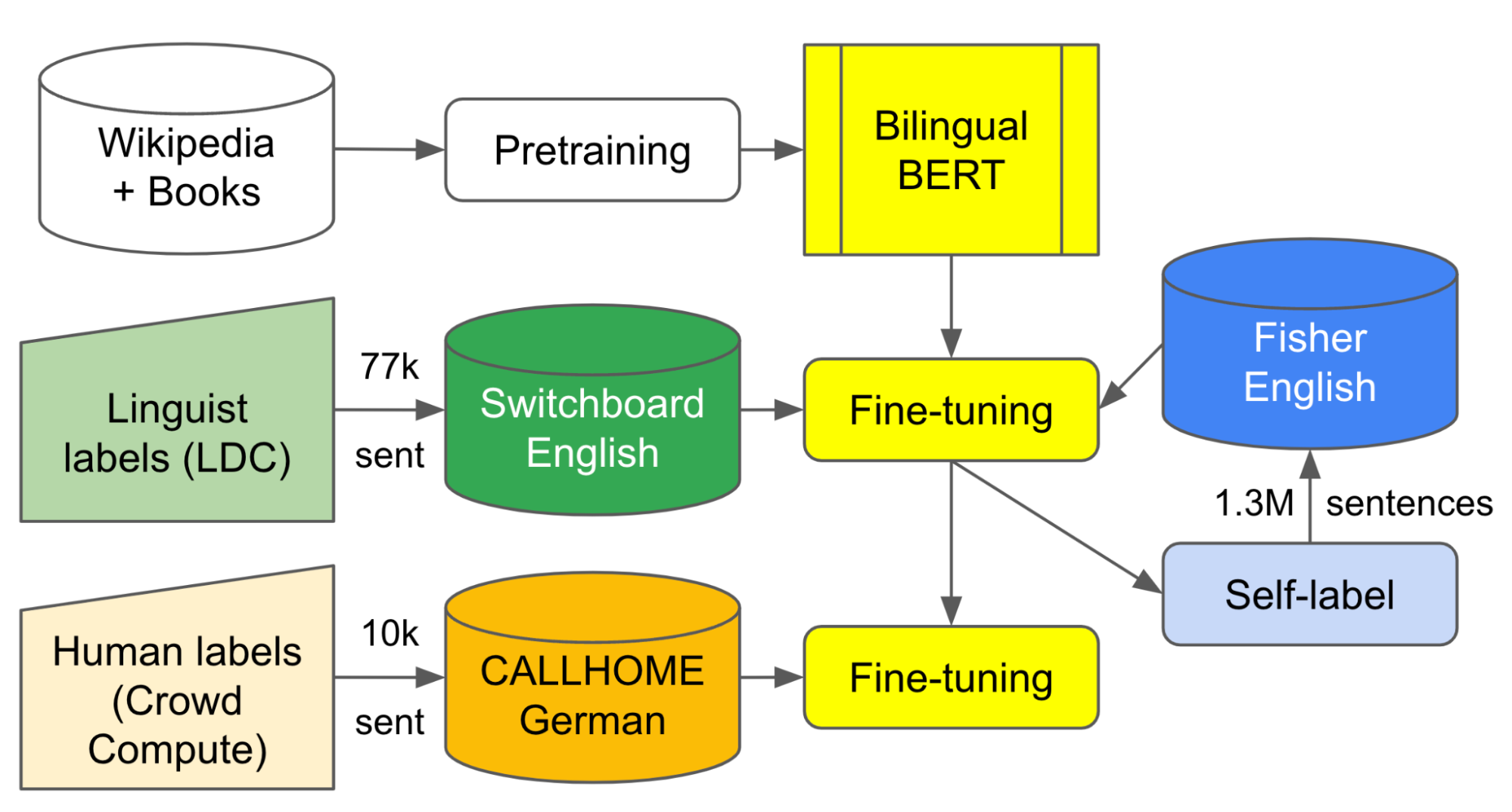 |
| Diagrama que ilustra el flujo de datos etiquetados y la salida autodidacta en nuestra mejor configuración de formación multilingüe. Al entrenar con datos en inglés y alemán, podemos mejorar el rendimiento a través del aprendizaje por transferencia. |
Nuestros resultados indican que el ajuste fino en un gran corpus en inglés puede lograr una precisión aceptable con una transferencia de tiro cero a idiomas similares al alemán, pero se requirió al menos una cantidad modesta de etiquetas alemanas para aumentar el recuerdo de menos del 60 % a más. mejor que el 80%. El ajuste fino en dos etapas de un modelo bilingüe inglés-alemán arrojó la mayor precisión y el total de F1.
| Acercarse | precisión | Recuerdo | F1 |
| Berto alemánBASE Modelo refinado utilizando 7300 ejemplos CALLHOME alemanes etiquetados por humanos | 89,1% | 81,3% | 85.0 |
| Como arriba, pero con 7500 ejemplos de CALLHOME alemanes autoetiquetados adicionales | 91,5% | 83,3% | 87.2 |
| Modelo BERTbase bilingüe inglés/alemán ajustado a English Switchboard+Fisher, evaluado en alemán CALLHOME (transmisión de voz de disparo cero) | 87,2% | 59,1% | 70.4 |
| Como arriba, pero posteriormente refinado con 14.800 ejemplos de CALLHOME en alemán (etiquetados por personas y por ellos mismos). | 95,5% | 82,6% | 88.6 |
Conclusión
Limpiar las irregularidades en las transcripciones puede mejorar no solo su legibilidad humana, sino también el rendimiento de otros modelos que usan transcripciones. Demostramos métodos efectivos para identificar disfluencias y extender nuestro modelo de disfluencia a entornos con recursos limitados, nuevos idiomas y casos de uso más interactivos.
Gracias
Muchas gracias a Vicky Zayats, Johann Rocholl, Angelica Chen, Noah Murad, Dirk Padfield y Preeti Mohan por escribir el código, ejecutar los experimentos y escribir los artículos que se analizan aquí. También agradecemos a nuestro gerente técnico de productos, Aaron Schneider, Bobby Tran del equipo Cerebra Data Ops y Chetan Gupta de Speech Data Ops por su ayuda para obtener etiquetas de datos adicionales.
[ad_2]