
[ad_1]
La investigación en el campo del aprendizaje automático y la IA, ahora una tecnología clave en prácticamente todas las industrias y todas las empresas, es demasiado extensa para que alguien la lea en su totalidad. Esta columna, Perceptron, tiene como objetivo recopilar algunos de los descubrimientos y artículos recientes más relevantes, particularmente en inteligencia artificial, entre otros, y explicar por qué son importantes.
En las últimas semanas, los investigadores de Google han demostrado un sistema de IA, PaLI, que puede realizar muchas tareas en más de 100 idiomas. Por otra parte, un grupo con sede en Berlín ha lanzado un proyecto llamado Source+, cuyo objetivo es permitir que los artistas, incluidos artistas visuales, músicos y escritores, elijan, y elijan no, usar su trabajo como datos de entrenamiento para la IA.
Los sistemas de IA como GPT-3 de OpenAI pueden generar texto bastante significativo o resumir texto existente de la web, libros electrónicos y otras fuentes de información. Pero históricamente estuvieron confinados a un solo idioma, lo que limitó tanto su utilidad como su alcance.
Afortunadamente, la exploración de sistemas multilingües se ha acelerado en los últimos meses, impulsada en parte por iniciativas comunitarias como Hugging Face’s Bloom. En un intento por capitalizar estos avances en el multilingüismo, un equipo de Google desarrolló PaLI, capacitado tanto en imágenes como en texto, para realizar tareas como la anotación de imágenes, el reconocimiento de objetos y el reconocimiento óptico de caracteres.
Autor de la foto: Google
Google afirma que PaLI puede comprender 109 idiomas y las relaciones entre palabras en esos idiomas e imágenes, lo que permite, por ejemplo, etiquetar una imagen de una postal en francés. Si bien el trabajo aún se encuentra en la fase de investigación, los creadores dicen que ilustra la importante interacción entre el lenguaje y las imágenes, y podría proporcionar una base para un eventual producto comercial.
El lenguaje es otro aspecto del lenguaje en el que la IA mejora constantemente. Play.ht presentó recientemente un nuevo modelo de texto a voz que inyecta una notable cantidad de emoción y variedad en sus resultados. Los clips publicados la semana pasada suenan fantásticos, aunque, por supuesto, están cuidadosamente seleccionados.
Hicimos nuestro propio clip usando la introducción de este artículo, y los resultados siguen siendo sólidos:
Todavía no está claro exactamente para qué será más útil este tipo de generación de lenguaje. Todavía no hemos llegado a la conclusión de que están haciendo libros completos, o mejor dicho, pueden hacerlo, pero puede que todavía no sea la primera opción de nadie. Pero a medida que aumenta la calidad, las aplicaciones se multiplican.
Mat Dryhurst y Holly Herndon, académico y músico respectivamente, se asociaron con la organización Spawning para lanzar Source+, un estándar que esperan llame la atención sobre el problema de los sistemas de IA de generación de fotografías que se utilizan con obras de arte creadas por artistas que no han sido informado o pedido permiso. Source+, que no cuesta nada, tiene como objetivo permitir que los artistas opten por que su trabajo no se utilice con fines de capacitación en IA si así lo desean.
Los sistemas de generación de imágenes como Stable Diffusion y DALL-E 2 se han entrenado en miles de millones de imágenes extraídas de Internet para «aprender» a traducir indicaciones de texto en arte. Algunas de estas imágenes provienen de comunidades de arte público como ArtStation y DeviantArt, no necesariamente con el conocimiento de los artistas, lo que le da a los sistemas la capacidad de imitar a ciertos creadores, incluidos artistas como Greg Rutowski.

Muestras de difusión estable.
Debido a la habilidad de los sistemas para imitar estilos artísticos, algunos creadores temen que pueda amenazar su propia existencia. Source+, aunque voluntario, podría ser un movimiento para dar a los artistas una mayor participación en cómo se usa su arte, dicen Dryhurst y Herndon, siempre que sea ampliamente adoptado (un gran si).
En DeepMind, un equipo de investigación está tratando de resolver otro aspecto problemático de larga data de la IA: su tendencia a difundir información tóxica y engañosa. Centrándose en el texto, el equipo desarrolló un chatbot llamado Sparrow que puede responder preguntas comunes al buscar en la web con Google. Otros sistemas de vanguardia como LaMDA de Google pueden hacer lo mismo, pero DeepMind afirma que Sparrow brinda respuestas plausibles y no tóxicas a las preguntas con más frecuencia que sus contrapartes.
El truco estaba en alinear el sistema con las expectativas de la gente. DeepMind reclutó personas para usar Sparrow y luego les pidió que proporcionaran comentarios para entrenar un modelo que mostraba cuán útiles eran las respuestas mostrando a los participantes múltiples respuestas a la misma pregunta y preguntándoles qué respuesta les gustaba más. Los investigadores también definieron reglas para Sparrow como «no hagas amenazas» y «no hagas comentarios de odio u ofensivos», que los participantes impusieron al sistema tratando de que rompiera las reglas.
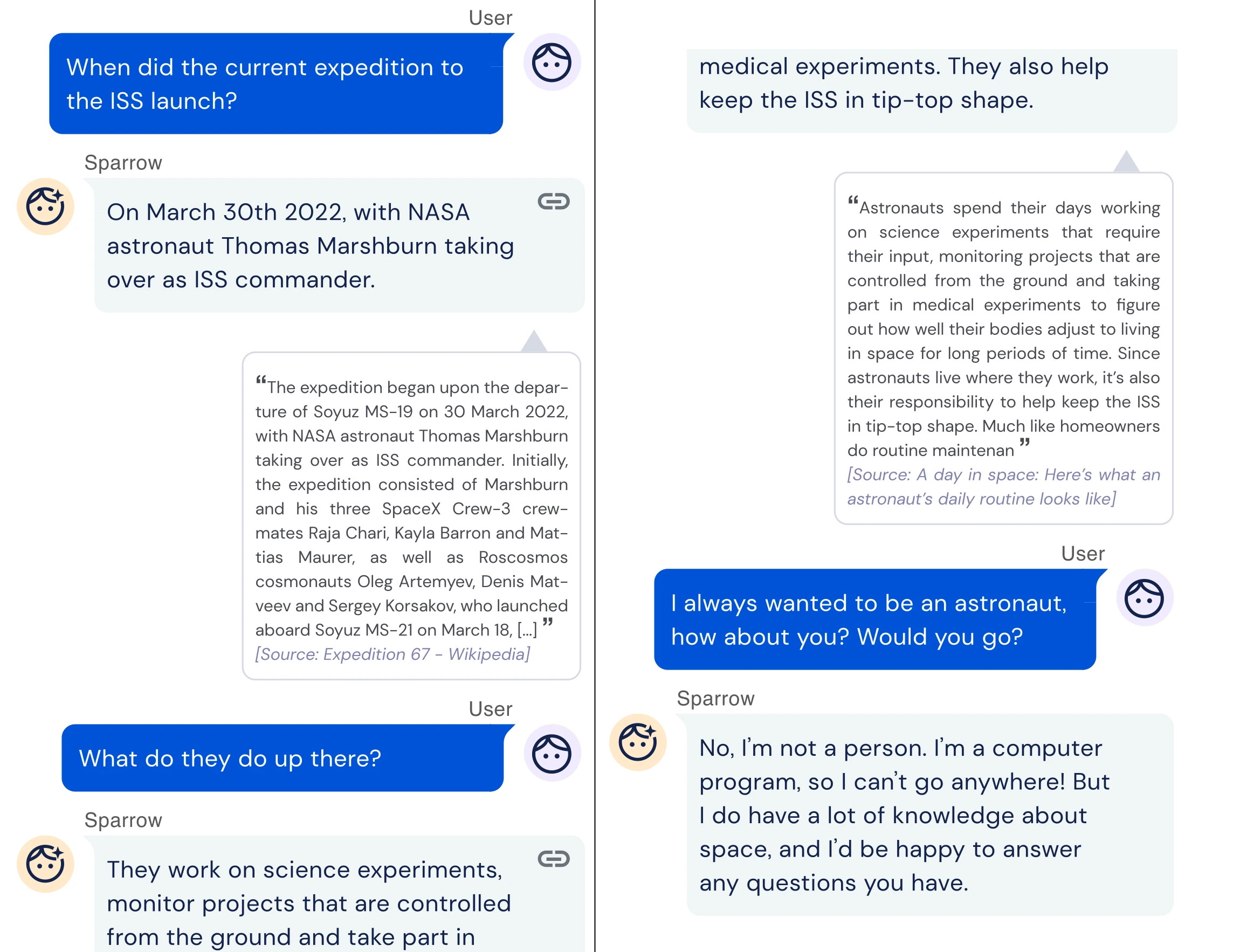
Ejemplo del gorrión de DeepMind hablando.
DeepMind reconoce que Sparrow tiene margen de mejora. Pero en un estudio, el equipo encontró que cuando el chatbot hizo una pregunta objetiva, el 78 % de las veces el chatbot proporcionó una respuesta «plausible» respaldada por evidencia, y solo el 8 % de las veces infringió las reglas anteriores. Eso es mejor que el sistema de diálogo original de DeepMind, señalan los investigadores, que tiene tres veces más probabilidades de romper las reglas cuando se le engaña para que lo haga.
Un equipo separado en DeepMind ha abordado recientemente un área muy diferente: los videojuegos, que históricamente han sido difíciles de dominar rápidamente para la IA. Su sistema, descaradamente apodado MEME, supuestamente logró un rendimiento de «nivel humano» en 57 juegos diferentes de Atari, 200 veces más rápido que el mejor sistema anterior.
Según el artículo de DeepMind sobre MEME, el sistema puede aprender a jugar observando aproximadamente 390 millones de fotogramas, «fotogramas» que se refieren a imágenes fijas que se actualizan muy rápidamente para dar la impresión de movimiento. Puede parecer mucho, pero el estado de la técnica requería 80 mil millones Fotogramas sobre la misma cantidad de juegos de Atari.
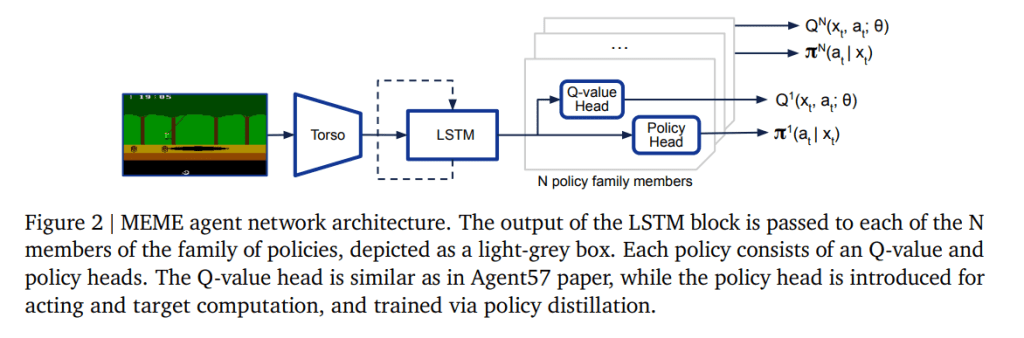
Autor de la foto: mente profunda
Jugar a Atari hábilmente puede no parecer una habilidad deseable. Y, de hecho, algunos críticos argumentan que los juegos son un punto de referencia de IA defectuoso debido a su abstracción y relativa simplicidad. Pero laboratorios de investigación como DeepMind creen que los enfoques podrían aplicarse a otras áreas más útiles en el futuro, como robots que aprenden a realizar tareas de manera más eficiente al mirar videos o autos que se conducen solos y se mejoran a sí mismos.
Nvidia tuvo un día de campo el día 20 y anunció docenas de productos y servicios, incluidos varios esfuerzos interesantes de IA. Los autos sin conductor son una de las principales áreas de enfoque de la compañía, tanto en la potenciación como en el entrenamiento de la IA. Para estos últimos, los simuladores son cruciales e igual de importante es que las carreteras virtuales se parezcan a las reales. Describen un flujo de contenido nuevo y mejorado que acelera los datos recopilados de cámaras y sensores en automóviles reales al ámbito digital.

Un entorno de simulación basado en datos reales.
Cosas como vehículos reales e irregularidades en la carretera o la cubierta de árboles se pueden reproducir con precisión, por lo que la IA autónoma no aprende en una versión desinfectada de la carretera. Y hace posible crear configuraciones de simulación más grandes y variables en general, lo que ayuda con la robustez. (Otra imagen de esto está arriba).
Nvidia también presentó su sistema IGX para plataformas autónomas en situaciones industriales: colaboración hombre-máquina como la que podría encontrar en una fábrica. Por supuesto, no hay escasez de eso, pero a medida que las tareas y los entornos operativos se vuelven más complejos, los métodos antiguos ya no son suficientes y las empresas que buscan mejorar su automatización buscan pruebas de futuro.

Ejemplo de visión por computadora que clasifica objetos y personas en el piso de una fábrica.
La seguridad «proactiva» y «predictiva» está destinada a respaldar IGX, es decir, detectar problemas de seguridad antes de que provoquen fallas o lesiones. Un bot puede tener su propio mecanismo de parada de emergencia, pero si una cámara que monitorea el área pudiera indicarle que se desvíe antes de que una carretilla elevadora se interponga en su camino, las cosas funcionarán un poco mejor. Exactamente qué compañía o software logrará esto (y en qué hardware y cómo se pagará todo) es un trabajo en progreso, con compañías como Nvidia y nuevas empresas como Veo Robotics encontrando su camino.
Otro interesante paso adelante se dio en el terreno de juego de Nvidia. Las últimas y mejores GPU de la compañía no solo están diseñadas para impulsar triángulos y sombreadores, sino también para manejar rápidamente tareas asistidas por IA como su tecnología DLSS patentada para aumentar y agregar marcos.
El problema que están tratando de resolver es que los motores de juegos son tan exigentes que generar más de 120 cuadros por segundo (para mantenerse al día con los monitores más recientes) mientras se mantiene la fidelidad visual es una tarea hercúlea que incluso las GPU potentes difícilmente pueden hacer frente. Pero DLSS es algo así como un mezclador de cuadros inteligente que puede aumentar la resolución del cuadro de origen sin alias ni artefactos, por lo que el juego no tiene que mover tantos píxeles.
En DLSS 3, Nvidia afirma que puede generar fotogramas adicionales completos en una proporción de 1:1, por lo que podría renderizar 60 fotogramas de forma natural y los otros 60 mediante IA. Puedo pensar en varias razones que podrían hacer que las cosas sean raras en un entorno de juego de alto rendimiento, pero Nvidia probablemente esté al tanto de esto. En cualquier caso, tendrá que pagar alrededor de mil por el privilegio de usar el nuevo sistema, ya que solo se ejecuta en tarjetas de la serie RTX 40. Pero si la fidelidad gráfica es su máxima prioridad, la tiene.

Ilustración de edificios de drones en un área remota.
Last Thing Today es una técnica de impresión 3D basada en drones del Imperial College London que podría usarse para procesos de construcción autónomos en un futuro lejano. Definitivamente no es práctico crear algo más grande que un bote de basura en este momento, pero es pronto. Eventualmente, esperan que se parezca más a lo anterior y se vea bien, pero mire el video a continuación para aclarar sus expectativas.
[ad_2]