
[ad_1]
El triunfo del rendimiento DDR5 continuó en la reciente Conferencia Internacional de Circuitos de Estado Sólido (ISSCC) de IEEE con un artículo de científicos de Samsung.

Samsung quiere duplicar la capacidad de DRAM con su nueva arquitectura propuesta. Imagen (modificada) utilizada bajo licencia de Adobe Stock
El documento, titulado «Una SDRAM DDR5 de 32 GB, 8,0 GB/s/pin con una arquitectura de mosaico simétrico en un proceso DRAM de 10 nm de quinta generación», aborda las limitaciones de la arquitectura de 16 GB utilizada actualmente y el diseño de mosaico simétrico propuesto por Samsung. En este artículo resumimos los componentes clave de la arquitectura descrita en el documento.
Del chip de 16 GB al chip monolítico de 32 GB
Actualmente, las memorias DDR5 de mayor capacidad utilizan una arquitectura apilada tridimensional (3DS) basada en un chip de 16 GB y fabricada en un proceso de 10 nm. El producto final principal actual es un módulo DRAM DDR5 de 64 GB, y la demanda de módulos de 128 GB está aumentando.
El artículo de Samsung describe un chip DDR5 monolítico de 32 GB de alta densidad que todavía utiliza el proceso de 10 nm. Samsung afirma que los sistemas 3DS basados en chips de 32 GB mejoran el rendimiento, admiten almacenamiento de hasta 1 TB cuando se utilizan en ocho pilas de chips y alcanzan velocidades de 8 GB por segundo por pin.
La industria reconoce la necesidad de pasar a un chip de 32 GB. Sin embargo, existen varios obstáculos. Los nodos de menos de 10 nm para DRAM aún no están listos, por lo que los fabricantes de chips deben encontrar formas de aumentar la capacidad sin cambiar el proceso de fabricación. Además, el factor de forma actual del módulo DRAM está demasiado arraigado para aumentar el tamaño del paquete sin aumentar significativamente la capacidad o el rendimiento.
Partición en mosaico para superar las limitaciones tradicionales de tamaño de DRAM
El chip de 32 GB es una adaptación, no un nuevo estándar y, por lo tanto, debe cumplir con los límites tradicionales del factor de forma DDR5 (máximo 10 mm x 11 mm) dictados por JDEC. Los métodos tradicionales para aumentar la capacidad sin reducir el tamaño del proceso incluyen agregar celdas DRAM dentro de un banco o duplicar el número de bancos físicos en un banco lógico. Esto da como resultado una huella de memoria rectangular que excede el tamaño del cuadro delimitador del paquete de 10 mm x 11 mm, ya sea en dirección vertical u horizontal.
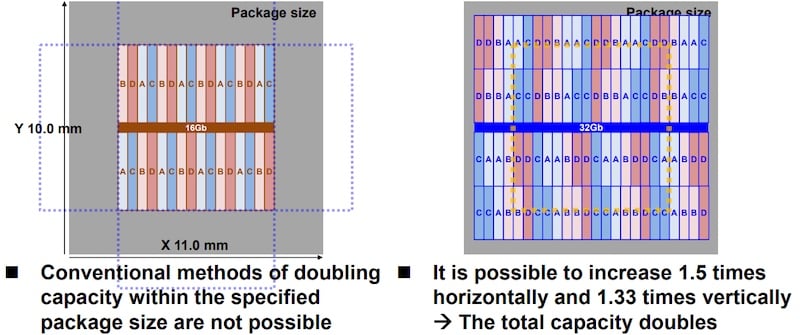
Comparación del aumento de la capacidad del chip utilizando la metodología convencional (izquierda) y el enfoque de mosaico simétrico (derecha).
En la arquitectura propuesta, cada banco de memoria lógica se divide en ⅓ y ⅔ particiones. Estos están dispuestos como un mosaico simétrico de diferentes particiones de los bancos lógicos. Esto duplica la capacidad de DRAM y solo aumenta el área 1,5 veces horizontalmente y 1,33 veces para caber dentro del cuadro delimitador.
Dos particiones de diferentes bancos lógicos comparten la misma línea de señal de E/S global (GIO) y el mismo amplificador de detección. Este intercambio reduce la capacidad de carga de la línea GIO, aumentando la velocidad y reduciendo el consumo de energía. Este diseño físico mantiene las E/S en el centro como se usa en el chip de 16 Gb, usa la misma estructura de pad y usa una estructura similar a través de silicio (TSV) para conectar las capas de 3DS.
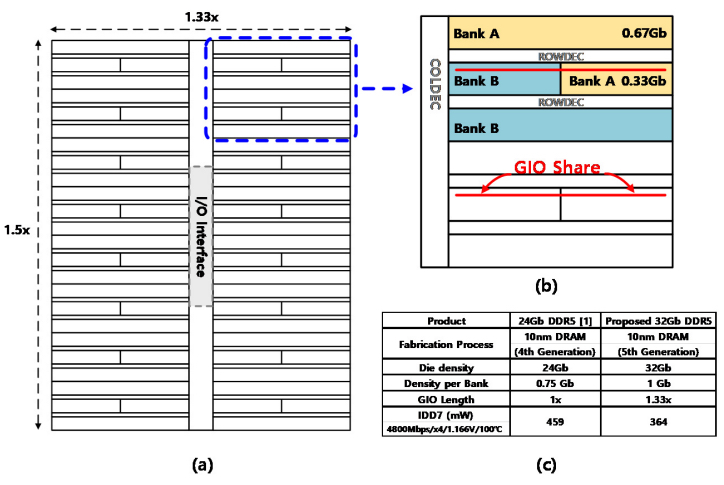
Arquitectura de mosaico simétrico.
El entrelazado y uso compartido de mosaicos de la línea GIO aprovecha la sincronización precisa de la especificación de sincronización garantizada de lectura a lectura y escritura a escritura (tCCD_L). Los bancos de memoria física se dividen y se accede a ellos como bancos lógicos utilizando las propiedades tCCD_L para dictar la sincronización.
Mayor velocidad y reducción de interferencias.
Para garantizar la precisión de los datos a velocidades tan altas, se requiere lógica adicional para lo que se conoce como ecualización de retroalimentación de decisión (DFE). La tecnología digital de alta velocidad no implica la simple transición de voltaje de «encendido/apagado» que ocurre a velocidades más bajas. Las señales son redondeadas, distorsionadas y, a menudo, parecen más analógicas que digitales. La capacitancia y la resistencia de la línea de señal esencialmente crean filtros con constantes de tiempo R/C que distorsionan y obstruyen la señal que transporta información (el símbolo). Los efectos de un símbolo pueden traspasarse al siguiente, o los reflejos del componente receptor pueden distorsionar el símbolo, provocando interferencia entre símbolos (ISI), que debe mitigarse para evitar datos no válidos.
La arquitectura propuesta por Samsung complementa los circuitos DFE tradicionales con un sistema de cuatro tomas, una alternativa al tradicional DFE de dos tomas. En un circuito DFE, las derivaciones se devuelven a la entrada y se suman. Los cuatro toques retroalimentan un toque directamente para minimizar el retraso de retroalimentación. Los toques segundo, tercero y cuarto utilizan la suma CML (lógica del modelo actual) para mejorar aún más la precisión de los símbolos.
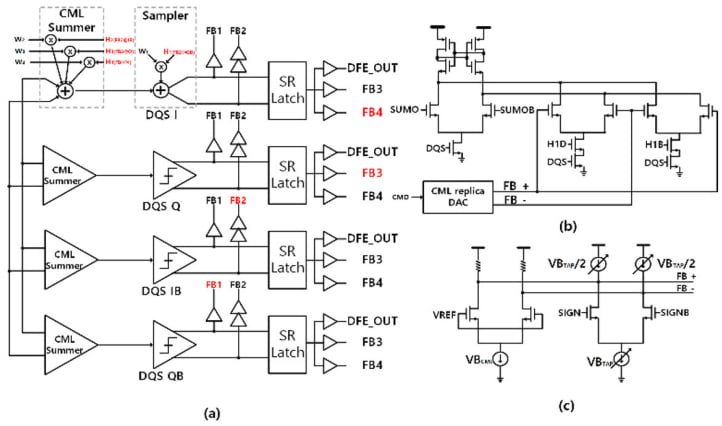
(a) DFE de cuatro toques. (b) Toque para alimentar el muestreador directamente. (c) Conecta de dos a cuatro en el circuito CML.
El DFE funciona junto con el circuito de calibración de voltaje de compensación automática en los buffers DQ. El circuito de calibración compensa el desplazamiento mediante el uso de cuatro rutas para cuatro fases de operación y calibra basándose en una mayoría directa de votos de las cuatro salidas de la ruta. El resultado es la capacidad de operar de manera confiable a 8 Gbps o más rápido.
Predecodificación de ID de chip
Con el doble de celdas de RAM por chip, el consumo de energía se vuelve aún más crítico que con un chip de 16 GB. Dado que estos chips se instalan en gran medida en configuraciones apiladas en 3D, los fabricantes de chips deben mejorar el proceso para centrarse en los chips ineficientes.
Un «rango» es un conjunto lógicamente combinado de bancos físicos que transportan el mismo ancho de palabra de datos que el bus de datos del chip. Puede formarse dentro de un troquel físico o en varios troqueles en un sistema de troqueles apilados en 3D. Por ejemplo, el cuadrante superior izquierdo de cada uno de los ocho chips apilados podría combinarse en un rango lógico de 8 bits y abordarse como tal.
En una configuración estándar, un comando llega al bus de comando con un ID de chip (CID). Luego, todos los rangos realizan una decodificación para determinar si son el objetivo previsto. Una vez completada la decodificación, solo se aplicará la clasificación prevista. Si todos los rangos realizan el proceso de decodificación, se desperdicia una cantidad significativa de energía.
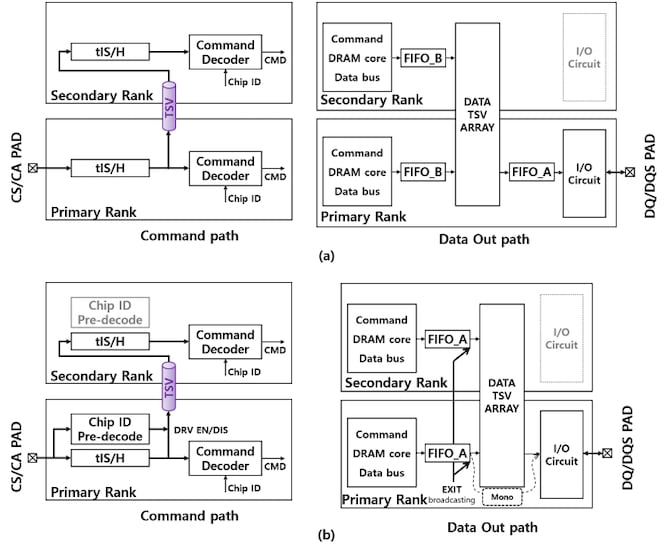
(a) Pila de decodificación CID tradicional y (b) sistema de predecodificación propuesto por Samsung.
Esta arquitectura propuesta tiene predecodificación de ID de chip en cada rango. Con tal funcionalidad, el rango primario tiene un circuito de predecodificación antes del TSV. Sólo envía el CID al siguiente rango si no es el objetivo previsto. Básicamente, cada rango de la pila detiene el CID si es el objetivo previsto. Si el último rango de la pila es el objetivo previsto, no se ahorra energía, pero se guarda una cantidad proporcional de energía para todos los rangos inferiores.
Progreso en el factor de forma actual
La arquitectura propuesta por Samsung aumenta significativamente la capacidad de DRAM sin cambiar el factor de forma general ni reducir las geometrías de grabado del chip. Al utilizar una estructura organizativa más eficiente, aunque poco convencional, se pueden integrar más empresas en un mismo área sin necesidad de estándares o cambios de fábrica. La arquitectura propuesta aprovecha rangos lógicos, peculiaridades de sincronización y uso compartido de recursos para aumentar la capacidad, reducir el consumo de energía y aumentar la velocidad máxima.
Según las mediciones de Samsung, un DIMM de 0,5 TB basado en 32 GB utiliza un 30% menos de energía que una pieza basada en 16 GB, lo que lo convierte en un reemplazo útil para centros de datos y otras aplicaciones informáticas que consumen mucha capacidad y energía.
Todas las imágenes técnicas utilizadas son cortesía de Samsung e ISSCC.
[ad_2]