[ad_1]

El lenguaje natural permite consultas descriptivas flexibles sobre imágenes. La interacción entre las consultas de texto y las imágenes establece un significado lingüístico en el mundo visual y permite una mejor comprensión de las relaciones de los objetos, las intenciones humanas hacia los objetos y las interacciones con el entorno. La comunidad de investigación ha estudiado la base visual a nivel de objeto a través de una variedad de tareas que incluyen la comprensión de referencias a expresiones, la localización basada en texto y, en general, el reconocimiento de objetos, cada uno de los cuales requiere diferentes habilidades en un modelo. Por ejemplo, el reconocimiento de objetos intenta encontrar todos los objetos de un conjunto predefinido de clases, lo que requiere una localización y clasificación precisas, mientras que la comprensión de las expresiones de referencia localiza un objeto de un texto de referencia y, a menudo, requiere un razonamiento complejo sobre los objetos destacados. En la intersección de los dos está la localización basada en texto, donde una simple consulta de texto basada en categorías le pide al modelo que reconozca los objetos de interés.
Debido a las diferentes características de sus tareas, la comprensión, el reconocimiento y la localización basada en texto de frases relacionadas se investigan principalmente mediante puntos de referencia separados, con la mayoría de los modelos dedicados a una sola tarea. Como resultado, los modelos existentes no han sintetizado adecuadamente la información de las tres tareas para lograr una comprensión visual y lingüística más holística. Por ejemplo, los modelos de comprensión de expresiones referenciales están entrenados para predecir un objeto por imagen y, a menudo, tienen dificultades para ubicar múltiples objetos, rechazar consultas negativas o reconocer nuevas categorías. Además, los modelos de reconocimiento son incapaces de manejar la entrada de texto y los modelos de localización basados en texto a menudo tienen dificultades para manejar consultas complejas que se refieren a una instancia de objeto, como B. «Medio sándwich izquierdo». Finalmente, ninguno de los modelos puede generalizar lo suficiente más allá de sus datos y categorías de entrenamiento.
Para abordar estas limitaciones, presentamos «FindIt: Localización generalizada con consultas de lenguaje natural» en ECCV 2022. Aquí proponemos un modelo de conexión a tierra visual unificado, universal y multitarea llamado FindIt que puede responder de manera flexible a diferentes tipos de consultas de conexión a tierra y detección. La clave de esta arquitectura es un motor de fusión de múltiples niveles y modalidades cruzadas que puede realizar un razonamiento complejo para comprender expresiones mientras reconoce objetos pequeños y desafiantes para la localización y el reconocimiento basados en texto. También encontramos que un detector de objetos estándar y las pérdidas de detección son adecuados y sorprendentemente efectivos para las tres tareas, sin la necesidad de un diseño específico para la tarea y las pérdidas que son comunes en las plantas existentes. FindIt es simple, eficiente y supera a los modelos alternativos de última generación en términos de comprensión de referencias y puntos de referencia de localización basada en texto, a la vez que es competitivo en términos de punto de referencia de reconocimiento.
 |
| FindIt es un modelo unificado para la comprensión de frases de referencia (columna 1), localización basada en texto (columna 2) y la tarea de reconocimiento de objetos (columna 3). FindIt puede responder con precisión cuando se prueba en tipos/clases de objetos desconocidos durante el entrenamiento, p. B. «Encuentra el escritorio» (columna 4). En comparación con las líneas de base existentes (MattNet y GPV), FindIt puede realizar estas tareas bien y en un solo modelo. |
Fusión de imagen y texto en varios niveles
Se crean varias tareas de localización con diferentes objetivos de comprensión semántica. Por ejemplo, dado que el trabajo de la expresión de referencia se refiere principalmente a objetos prominentes en la imagen en lugar de objetos pequeños, ocluidos o distantes, las imágenes de baja resolución generalmente son suficientes. Por el contrario, la tarea de detección tiene como objetivo detectar objetos de diferentes tamaños y planos oclusales en imágenes de mayor resolución. Aparte de estos puntos de referencia, el problema general de conexión a tierra visual es inherentemente multiescala, ya que las consultas naturales pueden referirse a objetos de cualquier tamaño. Esto establece la necesidad de un modelo de fusión de imagen y texto de varios niveles para procesar de manera eficiente imágenes de mayor resolución en diferentes tareas de localización.
La premisa de FindIt es fusionar las características semánticas de nivel superior con capas transformadoras más expresivas capaces de capturar interacciones de todos los pares entre imagen y texto. Para las funciones de menor nivel y mayor resolución, utilizamos una fusión de productos de puntos más económica para ahorrar costos de computación y almacenamiento. Adjuntamos un cabezal detector (por ejemplo, Faster R-CNN) encima de los mapas de características combinados para predecir las cajas y sus clases.
 |
| FindIt acepta una imagen y un texto de consulta como entradas y los procesa por separado en columnas vertebrales de imagen/texto antes de aplicar la fusión multinivel. Introducimos las funciones combinadas en Faster R-CNN para predecir los cuadros a los que se hace referencia en el texto. La fusión de funciones utiliza transformadores más expresivos en los niveles superiores y un producto punto más económico en los niveles inferiores. |
aprendizaje multitarea
Aparte de la fusión multinivel descrita anteriormente, adaptamos las tareas de localización y reconocimiento basadas en texto para aceptar las mismas entradas que la tarea de comprensión de frases de referencia. Para la tarea de localización basada en texto, generamos una serie de consultas sobre las categorías presentes en la imagen. Para cada categoría existente, la consulta de texto es de la forma «Buscar el [object],» dónde [object] es el nombre de la categoría. Los objetos correspondientes a esta categoría se marcan como primer plano y los demás objetos como fondo. En lugar del aviso anterior, usamos un aviso estático para la tarea de detección, p. B. «Buscar todos los objetos» Hemos descubierto que la selección específica de avisos no es importante para las tareas de localización y reconocimiento basadas en texto.
Después del ajuste, todas las tareas consideradas comparten las mismas entradas y salidas: una entrada de imagen, una consulta de texto y un conjunto de cuadros delimitadores y clases para la salida. Luego combinamos los conjuntos de datos y entrenamos en la mezcla. Finalmente, para todas las tareas, utilizamos las pérdidas de detección de objetos estándar, que encontramos sorprendentemente simples y efectivas.
Evaluación
Aplicamos FindIt al popular benchmark RefCOCO para referirnos a tareas de comprensión de expresiones. Cuando solo está disponible el conjunto de datos COCO y RefCOCO, FindIt supera al modelo de última generación en todas las tareas. En las configuraciones donde se permiten conjuntos de datos externos, FindIt establece un nuevo estado del arte mediante el uso de COCO y todas las divisiones de RefCOCO juntas (sin otros conjuntos de datos). En las desafiantes divisiones de Google y UMD, FindIt supera al estado de la técnica en un 10 %, demostrando colectivamente los beneficios del aprendizaje multitarea.
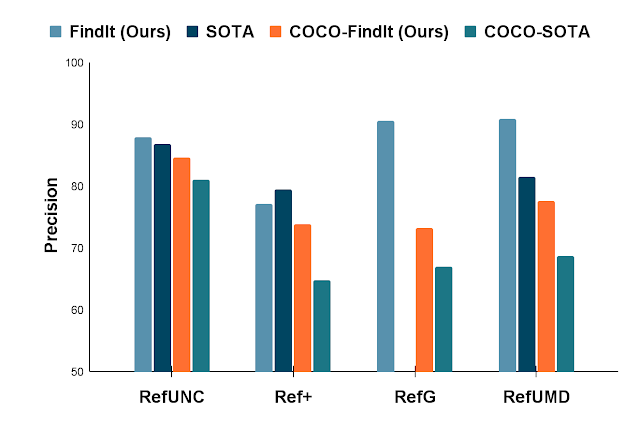 |
| Comparación con el estado de la técnica sobre el punto de referencia de expresión de referencia popular. FindIt es superior tanto en la configuración COCO como sin restricciones (se permiten datos de entrenamiento adicionales). |
En el punto de referencia de localización basado en texto, FindIt obtiene una puntuación del 79,7 %, por delante de las líneas de base GPV (73,0 %) y Faster R-CNN (75,2 %). Consulte el documento para obtener más evaluaciones cuantitativas.
También observamos que FindIt en la tarea de localización basada en texto generaliza mejor las nuevas categorías y supercategorías que las líneas de base comparables de una sola tarea en los populares conjuntos de datos COCO y Objects365, como se muestra en la figura a continuación.
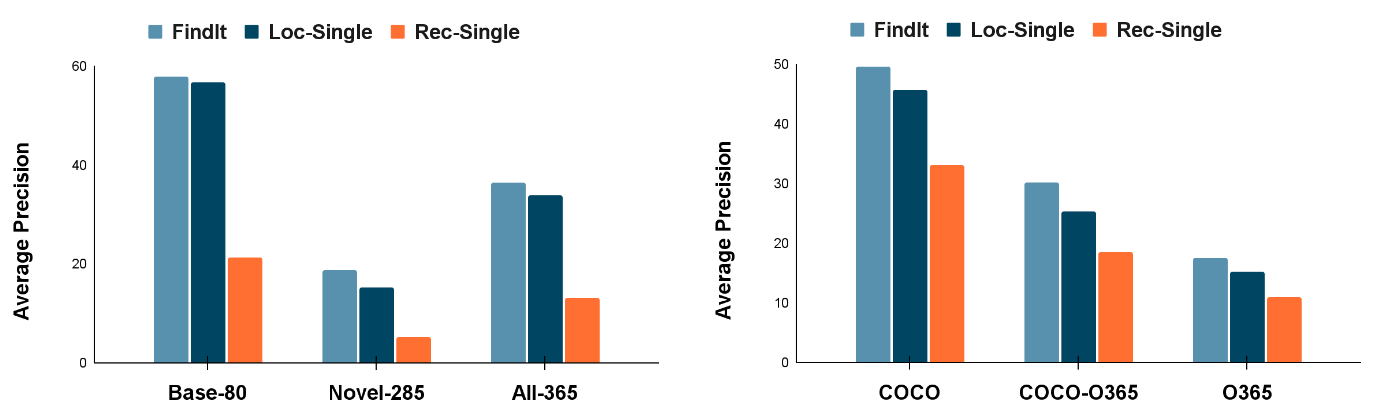 |
| FindIt en las categorías novel y super. Izquierda: FindIt supera las líneas de base de una sola tarea, especialmente en las categorías de novela. Derecha: FindIt supera las líneas de base de una sola tarea en las supercategorías invisibles. «Rec-Single» es el modelo de tarea única para comprender los términos de referencia y «Loc-Single» es el modelo de tarea única de localización basada en texto. |
eficiencia
También comparamos los tiempos de inferencia para la tarea de comprensión de expresiones de referencia (consulte la tabla a continuación). FindIt es eficiente y comparable a los enfoques de un solo paso existentes al tiempo que logra una mayor precisión. Para una comparación justa, todos los tiempos de ejecución se miden en una GPU GTX 1080Ti.
| modelo | tamaño de la imagen | columna vertebral | tiempo de ejecución (ms) | |||
| MattNet | 1000 | R101 | 378 | |||
| RAB | 256 | DarkNet53 | 39 | |||
| MCN | 416 | DarkNet53 | 56 | |||
| TransVG | 640 | R50 | 62 | |||
| FindIt (nuestro) | 640 | R50 | 107 | |||
| FindIt (nuestro) | 384 | R50 | 57 |
Conclusión
Presentamos Findit, que combina la comprensión de expresiones de referencia, la localización basada en texto y tareas de reconocimiento de objetos. Proponemos atención cruzada multiescala para unificar los diferentes requisitos de localización de estas tareas. Sin un diseño específico para tareas, FindIt supera el estado del arte en referencias de frases y localización basada en texto, muestra un rendimiento competitivo en el reconocimiento y generaliza mejor los datos fuera de distribución y las clases nuevas. Todo esto se logra en un modelo único, unificado y eficiente.
Gracias
Este trabajo está dirigido por Weicheng Kuo, Fred Bertsch, Wei Li, AJ Piergiovanni, Mohammad Saffar y Anelia Angelova. Nos gustaría agradecer a Ashish Vaswani, Prajit Ramachandran, Niki Parmar, David Luan, Tsung-Yi Lin y otros colegas de Google Research por sus consejos y debates útiles. Gracias a Tom Small por preparar la animación.
[ad_2]