
[ad_1]
TL;DR: Mensaje de texto -> LLM -> Representación intermedia (por ejemplo, un diseño de imagen) -> Difusión estable -> Imagen.
Los avances recientes en la generación de texto a imagen utilizando modelos de difusión han producido resultados notables en la síntesis de imágenes diversas y muy realistas. Sin embargo, a pesar de sus impresionantes capacidades, los modelos de difusión como Stable Diffusion a menudo tienen dificultades para seguir instrucciones con precisión cuando se requiere pensamiento espacial o de sentido común.
La siguiente figura enumera cuatro escenarios en los que la difusión estable no puede producir imágenes que coincidan exactamente con las indicaciones dadas, a saber negación, CalcularY Asignación de atributos, relación espacial. Por el contrario, nuestro método es llMETRO-conectado a tierra Dinfusión (LMD) proporciona una comprensión inmediata mucho mejor en la generación de texto a imagen en estos escenarios.

Figura 1: La difusión basada en LLM mejora la comprensión rápida de los modelos de difusión de texto a imagen.
Por supuesto, una posible solución a este problema es recopilar un enorme conjunto de datos multimodal con títulos complejos y entrenar un modelo de difusión grande con un codificador de lenguaje grande. Este enfoque tiene un costo significativo: entrenar tanto modelos de lenguajes grandes (LLM) como modelos de difusión lleva mucho tiempo y es costoso.
nuestra solución
Para resolver este problema de manera eficiente y con un costo mínimo (es decir, sin costos de capacitación), en su lugar Equipar modelos de difusión con razonamiento espacial y de sentido común mejorado utilizando LLM congelados disponibles comercialmente en un novedoso proceso de generación de dos etapas.
Primero, adaptamos un LLM a través del aprendizaje contextual como un generador de diseño basado en texto. Al proporcionar un mensaje de imagen, un LLM genera un diseño de escena en forma de cuadros delimitadores junto con las descripciones individuales correspondientes. En segundo lugar, controlamos un modelo de difusión con un controlador novedoso para generar imágenes dependientes del diseño. Ambas fases utilizan modelos preentrenados congelados sin LLM ni optimización de parámetros del modelo de difusión. Invitamos a los lectores a leer el artículo sobre arXiv para obtener más detalles.
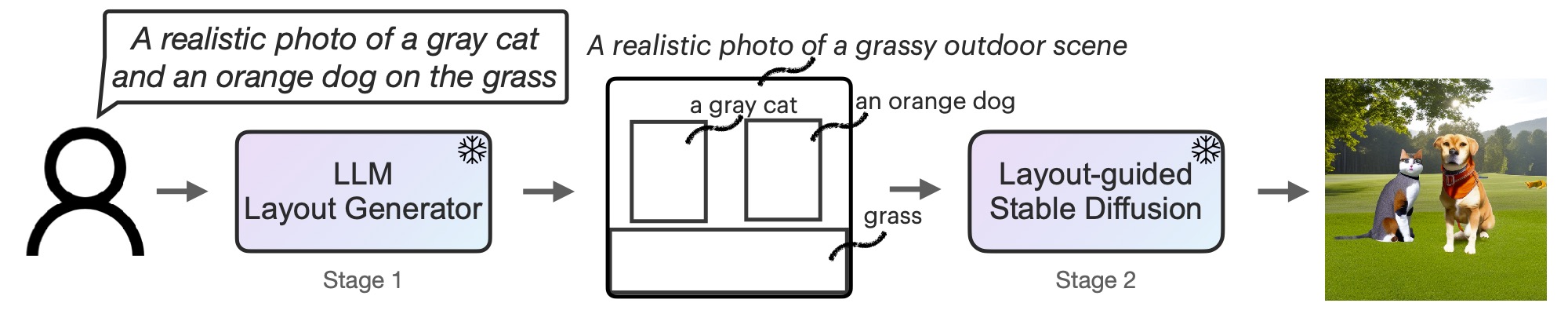
Figura 2: LMD es un modelo generativo de texto a imagen con un novedoso proceso de generación de dos etapas: un generador de texto a diseño con LLM + aprendizaje en contexto y una novedosa difusión estable basada en el diseño. Ambas etapas son libres de entrenamiento.
Funciones adicionales de LMD
Además, LMD por supuesto permite Especificación de escenas de múltiples rondas basadas en diálogosEsto permite aclaraciones adicionales y modificaciones posteriores para cada mensaje. Además, LMD es capaz de hacer esto. Manejar indicaciones en un idioma que no sea compatible con el modelo de difusión subyacente..

Figura 3: Al integrar un LLM para una comprensión rápida, nuestro método puede realizar una especificación de escena basada en diálogos y una generación de indicaciones en un idioma (chino en el ejemplo anterior) que no admite el modelo de difusión subyacente.
Para un LLM que admite diálogos de múltiples rondas (por ejemplo, GPT-3.5 o GPT-4), LMD permite al usuario proporcionar información o aclaraciones adicionales al LLM consultando el LLM después de la generación del diseño inicial en el diálogo y generando imágenes con ese diseño actualizado en la respuesta posterior del LLM. Por ejemplo, un usuario podría solicitar agregar un objeto a la escena o cambiar la posición o descripción de los objetos existentes (mitad izquierda de la Figura 3).
Además, al proporcionar un ejemplo de un mensaje que no está en inglés con un diseño y una descripción del fondo en inglés durante el aprendizaje contextual, LMD acepta entradas de mensajes que no están en inglés y genera diseños con descripciones de cuadros y el fondo en inglés para propósitos de diseño posteriores. Generación de imágenes. Como se muestra en la mitad derecha de la Figura 3, esto permite generar mensajes en un lenguaje que no es compatible con los modelos de difusión subyacentes.
Visualizaciones
Validamos la superioridad de nuestro diseño comparándolo con el modelo de difusión inicial (SD 2.1) que utiliza LMD bajo el capó. Invitamos a los lectores a nuestro trabajo para obtener más revisiones y comparaciones.
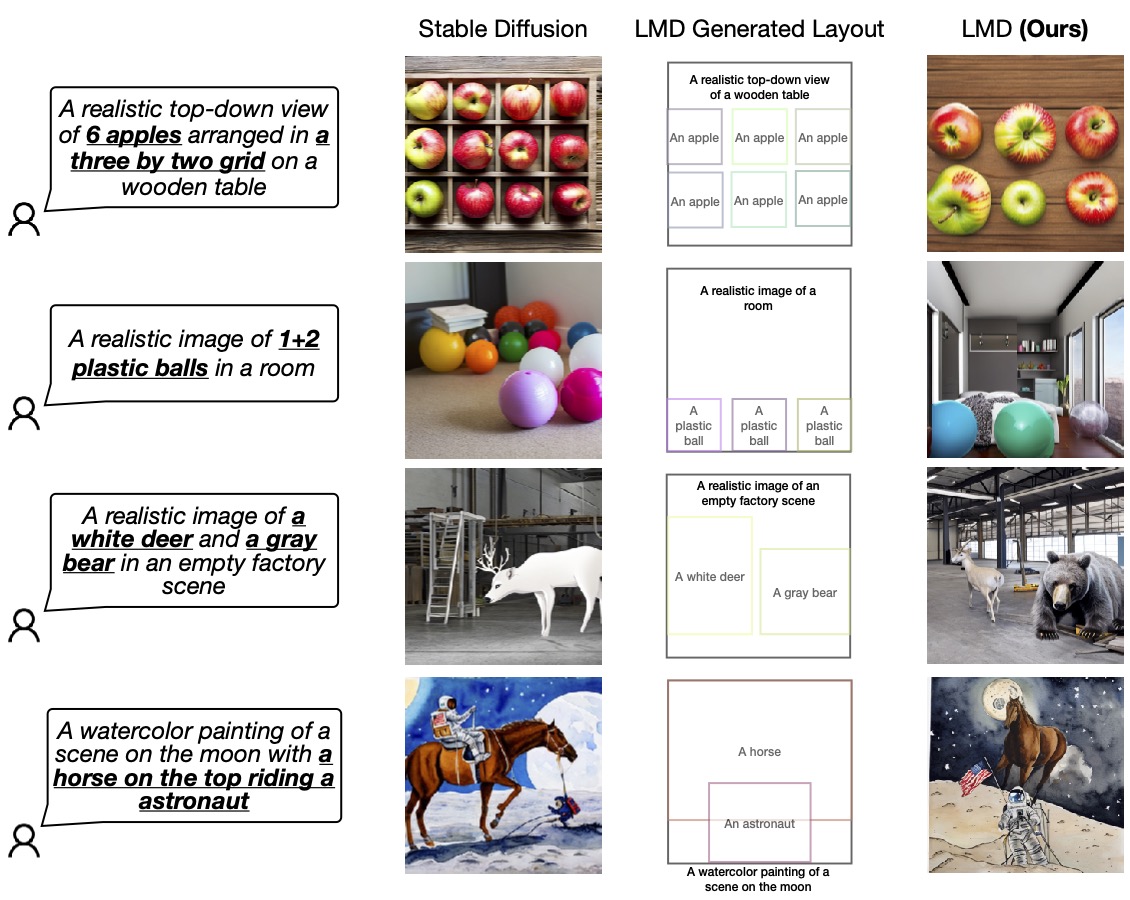
Figura 4: LMD supera al modelo de difusión de referencia al generar imágenes con precisión de acuerdo con indicaciones que requieren lenguaje y razonamiento espacial. LMD también permite la generación de texto a imagen contrafactual, que el modelo de difusión base no puede generar (última fila).
Para obtener más información sobre LLM-Grounded Diffusion (LMD), visite nuestro sitio web y el artículo sobre arXiv.
BibTex
Si la difusión basada en LLM inspira su trabajo, cítelo con:
@article{lian2023llmgrounded,
title={LLM-grounded Diffusion: Enhancing Prompt Understanding of Text-to-Image Diffusion Models with Large Language Models},
author={Lian, Long and Li, Boyi and Yala, Adam and Darrell, Trevor},
journal={arXiv preprint arXiv:2305.13655},
year={2023}
}
[ad_2]