
[ad_1]

La computación adaptativa es la capacidad de un sistema de aprendizaje automático para adaptar su comportamiento en respuesta a cambios en el entorno. Si bien las redes neuronales tradicionales tienen una función y capacidad computacional fijas, lo que significa que consumen la misma cantidad de FLOP para procesar diferentes entradas, un modelo computacional dinámico y adaptativo modula el presupuesto computacional que gasta en procesar cada entrada dependiendo de la complejidad de las entradas.
Los cálculos adaptativos en redes neuronales son atractivos por dos razones principales. En primer lugar, el mecanismo que introduce la adaptabilidad introduce un sesgo inductivo que puede desempeñar un papel clave en la resolución de algunas tareas desafiantes. Por ejemplo, permitir diferentes números de pasos computacionales para diferentes entradas puede ser crucial al resolver problemas aritméticos que requieren modelar jerarquías de diferentes profundidades. En segundo lugar, brinda a los profesionales la oportunidad de optimizar los costos de inferencia con la mayor flexibilidad que ofrecen los cálculos dinámicos, ya que estos modelos se pueden ajustar para gastar más FLOP en el procesamiento de una nueva entrada.
Las redes neuronales pueden hacerse adaptables mediante el uso de diferentes funciones o presupuestos computacionales para diferentes entradas. Se puede considerar una red neuronal profunda como una función que devuelve un resultado basado en la entrada y sus parámetros. Para implementar tipos de funciones adaptativas, se activa selectivamente un subconjunto de parámetros en función de la entrada. Este proceso se llama cálculo condicional. La adaptabilidad basada en el tipo de función se ha estudiado en estudios de mezclas expertas, donde los parámetros escasamente activados para cada muestra de entrada se determinan mediante enrutamiento.
Otra área de investigación en computación adaptativa se refiere a los presupuestos de computación dinámica. A diferencia de las redes neuronales estándar como T5, GPT-3, PaLM y ViT, que tienen su presupuesto computacional fijo para diferentes muestras, investigaciones recientes han demostrado que los presupuestos computacionales adaptativos pueden mejorar el rendimiento en tareas donde los transformadores son insuficientes. Gran parte de este trabajo logra la adaptabilidad mediante el uso de profundidad dinámica para asignar el presupuesto computacional. Por ejemplo, se ha propuesto el algoritmo ACT (Adaptive Computation Time) para proporcionar un presupuesto de cálculo adaptativo para redes neuronales recurrentes. Universal Transformer extiende el algoritmo ACT a Transformer al hacer que el presupuesto computacional dependa del número de capas de Transformer utilizadas para cada muestra o token de entrada. Estudios recientes como PonderNet adoptan un enfoque similar al tiempo que mejoran los mecanismos de parada dinámica.
En el artículo «Computación adaptativa con secuencia de entrada elástica» presentamos un nuevo modelo que utiliza computación adaptativa, llamado AdaTape. Este modelo es una arquitectura basada en Transformer que utiliza un conjunto dinámico de tokens para construir secuencias de entrada elásticas, ofreciendo una perspectiva única sobre la adaptabilidad en comparación con trabajos anteriores. AdaTape utiliza un mecanismo de lectura de cinta adaptable para determinar una cantidad diferente de tokens de cinta para agregar a cada entrada según la complejidad de la entrada. AdaTape es muy fácil de implementar, proporciona una perilla eficaz para aumentar la precisión cuando es necesario, pero también es mucho más eficiente en comparación con otras líneas de base adaptativas, ya que inyecta adaptabilidad directamente en la secuencia de entrada y no en la profundidad del modelo. Finalmente, Adatape ofrece un mejor rendimiento en tareas estándar como clasificación de imágenes, así como en tareas algorítmicas, al tiempo que ofrece un compromiso favorable entre calidad y coste.
Transformador computacional adaptativo con secuencia de entrada elástica.
AdaTape utiliza tanto los tipos de funciones adaptativas como un presupuesto de cálculo dinámico. Específicamente, para un lote de secuencias de entrada después de la tokenización (por ejemplo, una proyección lineal de parches no superpuestos de una imagen en Vision Transformer), AdaTape utiliza un vector que representa cada entrada para seleccionar dinámicamente una secuencia de tokens de cinta de tamaño variable.
AdaTape utiliza un banco de tokens llamado «banco de cintas» para almacenar todos los tokens de cinta posibles que interactúan con el modelo a través del mecanismo de lectura de cinta adaptativa. Exploraremos dos métodos diferentes para crear el banco de bandas: un banco basado en entradas y un banco que se puede aprender.
La idea general de impulsado por entrada La tarea del banco es extraer un banco de tokens de la entrada, utilizando un enfoque diferente al del modelo de tokenizador original para asignar la entrada sin procesar a una secuencia de tokens de entrada. Esto permite un acceso dinámico y bajo demanda a la información de la entrada vista desde otro ángulo, p. una resolución de imagen diferente o un nivel diferente de abstracción.
En algunos casos, la tokenización en un nivel diferente de abstracción no es posible, lo que hace imposible un banco de bandas controlado por entradas, como cuando es difícil dividir aún más cada nodo en un transformador gráfico. Para resolver este problema, AdaTape proporciona un enfoque más general para generar el banco de cintas mediante el uso de un conjunto de vectores entrenables como tokens de cinta. Este enfoque se conoce como banco aprendible y puede considerarse como una capa de incrustación donde el modelo puede recuperar tokens dinámicamente según la complejidad del ejemplo de entrada. El banco de aprendizaje permite a AdaTape generar un banco de cintas más flexible y le brinda la capacidad de ajustar dinámicamente su presupuesto computacional en función de la complejidad de cada ejemplo de entrada, p. B. Ejemplos más complejos recuperan más tokens del banco, lo cual el modelo no permite usar solo el conocimiento almacenado en el banco, sino que también gasta más FLOP para procesar porque la entrada ahora es mayor.
Finalmente, los tokens de banda seleccionados se agregan a la entrada original y se envían a las siguientes capas del transformador. Para cada capa de transformador, se utiliza la misma atención de múltiples cabezales para todos los tokens de entrada y de banda. Sin embargo, se utilizan dos redes de retroalimentación (FFN) diferentes: una para todos los tokens de la entrada original y la otra para todos los tokens de banda. Al utilizar redes de retroalimentación separadas para tokens de entrada y de banda, hemos visto una calidad ligeramente mejor.
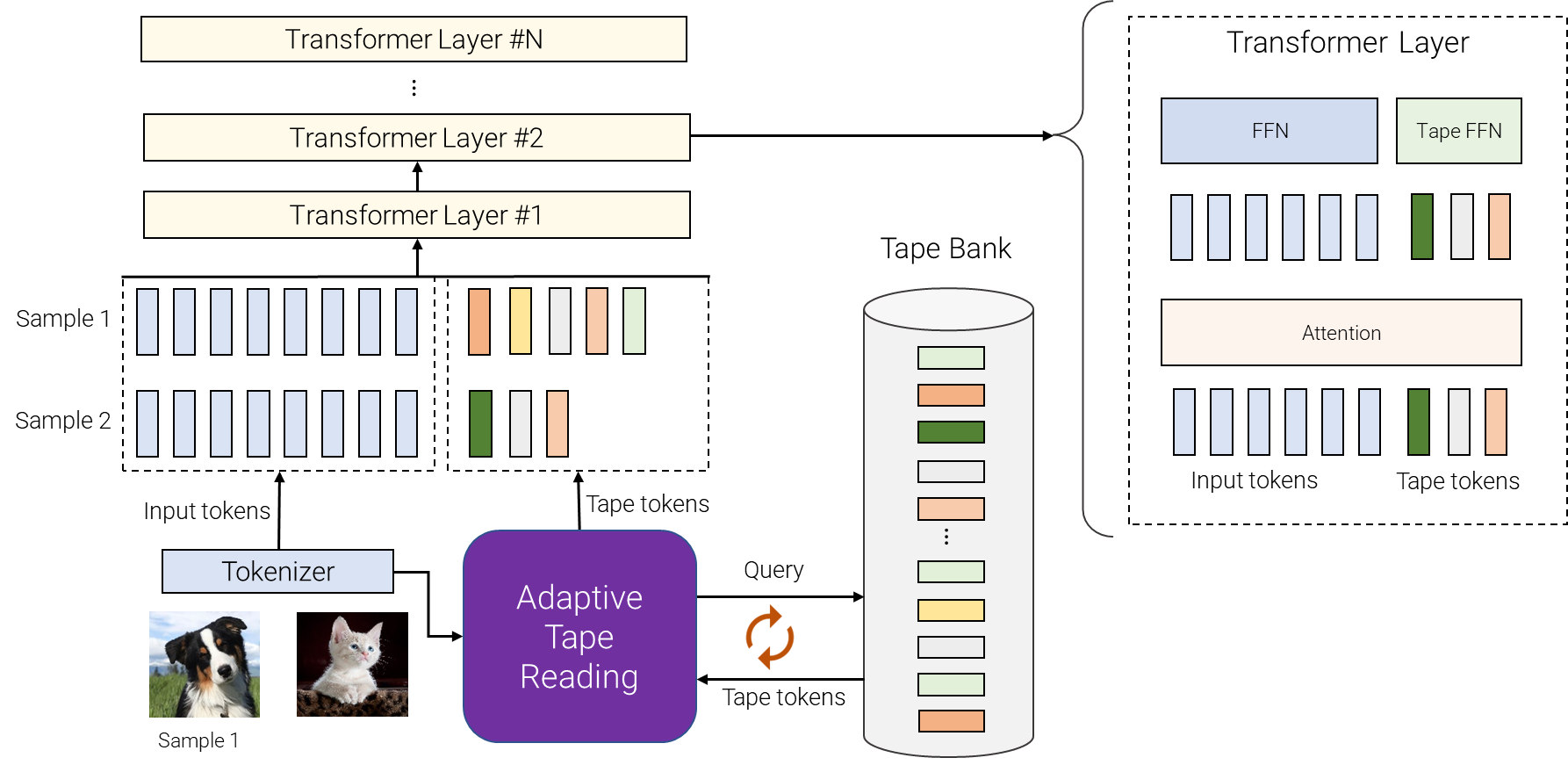 |
| Una descripción general de AdaTape. Para diferentes muestras seleccionamos un número variable de tokens diferentes del banco de bandas. El banco de bandas puede controlarse mediante la entrada, p.e. B. extrayendo información particularmente detallada, o puede ser un conjunto de vectores entrenables. La lectura de cinta adaptativa se utiliza para seleccionar recursivamente diferentes secuencias de tokens de cinta de longitud variable para diferentes entradas. Luego, estos tokens simplemente se conectan a las entradas y se alimentan al codificador del transformador. |
AdaTape proporciona polarización inductiva útil
Evaluamos la paridad de AdaTape, una tarea muy desafiante para el transformador estándar, para estudiar el efecto de los sesgos inductivos en AdaTape. En el problema de paridad, dada una secuencia de unos, ceros y -1, el modelo tiene que predecir qué tan par o impar es el número de unos en la secuencia. La paridad es el lenguaje regular periódico o sin recuento más simple, pero quizás sorprendentemente el transformador estándar no puede resolver el problema.
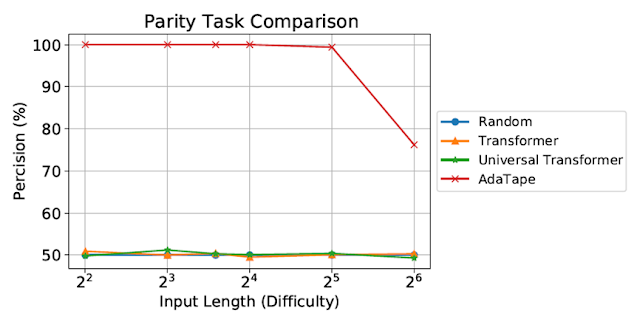 |
| Evaluación para la tarea de paridad. El transformador estándar y el transformador universal no pudieron hacer frente a esta tarea ya que ambos mostraron un rendimiento al nivel de una línea base aleatoria. |
A pesar de evaluar utilizando secuencias cortas y simples, tanto el transformador estándar como el transformador universal no pudieron realizar la tarea de paridad porque no pueden gestionar un contador en el modelo. Sin embargo, AdaTape supera a todas las líneas de base porque incorpora una repetición ligera en su mecanismo de selección de entrada, proporcionando polarización inductiva que permite el mantenimiento implícito de un contador, lo que no es posible con los transformadores estándar.
Evaluación para clasificación de imágenes.
También evaluamos AdaTape para la tarea de clasificación de imágenes. Con este fin, entrenamos a AdaTape desde cero en ImageNet-1K. La siguiente figura muestra la precisión de AdaTape y los métodos básicos, incluidos A-ViT y Universal Transformer ViT (UViT y U2T), en comparación con su velocidad (medida como la cantidad de fotogramas procesados por cada código por segundo). En términos de calidad y compensación de costos, AdaTape funciona significativamente mejor que las líneas base de transformadores adaptativos alternativos. En términos de eficiencia, los modelos AdaTape más grandes (en términos de recuento de parámetros) son más rápidos que los modelos base más pequeños. Estos resultados son consistentes con los hallazgos de trabajos anteriores que muestran que las arquitecturas de profundidad del modelo adaptativo no son adecuadas para muchos aceleradores como el TPU.
 |
| Evaluamos AdaTape entrenando ImageNet desde cero. Para A-ViT, no solo informamos los resultados del trabajo, sino que también volvemos a implementar A-ViT entrenando desde cero, es decir, A-ViT (el nuestro). |
Un estudio del comportamiento de AdaTape
Además de su desempeño en la tarea de paridad e ImageNet-1K, también evaluamos el comportamiento de selección de tokens de AdaTape con un banco basado en entradas en el conjunto de validación JFT-300M. Para comprender mejor el comportamiento del modelo, visualizamos los resultados de la selección de tokens en el Banco impulsado por entrada B. Mapas de calor, donde los colores más claros significan que la ubicación se elige con más frecuencia. Los mapas de calor muestran que AdaTape elige los parches centrales con más frecuencia. Esto es consistente con nuestro conocimiento previo, ya que los parches centrales tienden a ser más informativos, especialmente en el contexto de conjuntos de datos de imágenes naturales donde el objeto principal está en el centro de la imagen. Este resultado subraya la inteligencia de AdaTape, ya que puede identificar y priorizar de manera efectiva parches más informativos para mejorar su rendimiento.
 |
| Visualizamos el mapa de calor de selección de tokens de cinta de AdaTape-B/32 (izquierda) y AdaTape-B/16 (derecha). El color más cálido/claro significa que el parche en esa posición se seleccionará con más frecuencia. |
Diploma
AdaTape presenta longitudes de secuencia elásticas generadas por el mecanismo de lectura de cinta adaptativa. Esto también introduce una nueva polarización inductiva que permite a AdaTape resolver tareas que son desafiantes tanto para los transformadores estándar como para los transformadores adaptativos existentes. Al realizar extensos experimentos en puntos de referencia de reconocimiento de imágenes, demostramos que AdaTape supera a los transformadores estándar y a los transformadores de arquitectura adaptativa cuando el cálculo se mantiene constante.
gracias
Uno de los autores de esta publicación, Mostafa Dehghani, está ahora en Google DeepMind.
[ad_2]