[ad_1]
Los sistemas de subtítulos de video multimodal utilizan tanto los fotogramas de video como el habla para generar descripciones en lenguaje natural (subtítulos) de videos. Dichos sistemas son peldaños hacia el objetivo de larga data de crear sistemas conversacionales multimodales que se comuniquen sin esfuerzo con los usuarios y, al mismo tiempo, perciban entornos a través de flujos de entrada multimodales.
A diferencia de las tareas de comprensión de video (p. ej., clasificación y recuperación de video), donde el principal desafío radica en procesar y comprender los videos de entrada multimodal, la tarea de subtítulos de video multimodal incluye el desafío adicional de generar subtítulos bien fundamentados. El enfoque más común para esta tarea es entrenar una red de codificador-decodificador junto con datos anotados manualmente. Sin embargo, debido a la falta de datos extensos y anotados manualmente, la tarea de anotar subtítulos razonados para videos es laboriosa y, en muchos casos, poco práctica. Investigaciones anteriores como VideoBERT y CoMVT pre-entrenan sus modelos videos sin subtítulos utilizando el reconocimiento automático de voz (ASR). Sin embargo, estos modelos a menudo no pueden generar oraciones en lenguaje natural porque carecen de un decodificador y solo el codificador de video se pasa a las tareas posteriores.
En Preentrenamiento generativo de extremo a extremo para subtítulos de video multimodal, publicado en CVPR 2022, presentamos un marco de preentrenamiento novedoso para subtítulos de video multimodal. Este marco, que llamamos preentrenamiento de video generativo multimodal o MV-GPT, entrena colectivamente un codificador de video multimodal y un decodificador de oraciones a partir de videos sin etiquetar utilizando una expresión futura como texto de destino y formulando una nueva tarea de generación bidireccional. Mostramos que MV-GPT se puede asignar de manera efectiva a la subtitulación de video multimodal y lograr resultados de vanguardia en varios puntos de referencia. Además, el codificador de video multimodal es competitivo para múltiples tareas de comprensión de video, como B. VideoQA, texto a video a pedido y detección de acciones.
Expresión futura como señal de texto adicional
Por lo general, cada videoclip de entrenamiento de subtítulos de video multimodal está asociado con dos textos diferentes: (1) una transcripción de voz que está alineada con el clip como parte del flujo de entrada multimodal y (2) un subtítulo de destino que a menudo se anota manualmente. Que codificadores aprende a combinar información de la transcripción con contenido visual, y la firma objetivo se usa para entrenar esto descifrador por generaciones. Sin embargo, para videos sin subtítulos, cada clip de video contiene solo una transcripción de ASR, sin un subtítulo de destino anotado manualmente. Además, no podemos usar el mismo texto (la transcripción ASR) tanto para la entrada del codificador como para el objetivo del decodificador, ya que generar el objetivo sería trivial.
MV-GPT evita este desafío al usar una expresión futura como una señal de texto adicional y al permitir que el codificador y el decodificador se entrenen previamente juntos. Sin embargo, entrenar un modelo para generar expresiones futuras, que a menudo no se basan en el contenido de entrada, no es lo ideal. Entonces aplicamos una nueva pérdida de generación bidireccional para fortalecer la conexión a la entrada.
Pérdida de generación bidireccional
El problema de la generación de texto no justificado se mitiga mediante la formulación de una pérdida de generación bidireccional que incluye generación hacia adelante y hacia atrás. La generación directa genera expresiones futuras, marcos visuales dados y sus transcripciones correspondientes, y permite que el modelo aprenda a fusionar el contenido visual con su transcripción correspondiente. La generación hacia atrás utiliza los marcos visuales y las expresiones futuras para entrenar al modelo para que genere una transcripción que contenga un texto más informado del videoclip. La pérdida de generación bidireccional en MV-GPT hace posible entrenar el codificador y el decodificador para manejar texto con base visual.
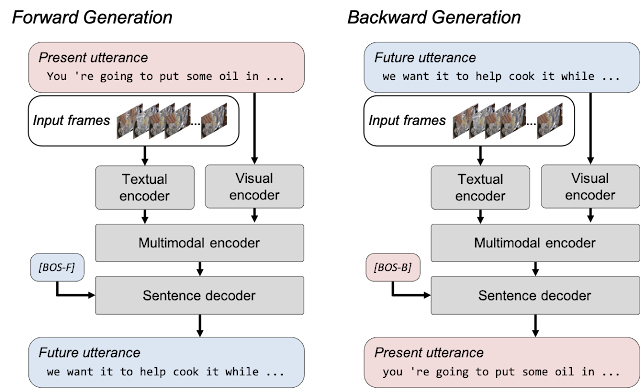 |
| Generación bidireccional en MV-GPT. Se entrena un modelo con dos pérdidas de generación. En la generación hacia adelante, el modelo genera un enunciado futuro (cajas azules) dados los marcos y el enunciado presente (cajas rojas), mientras que la generación hacia atrás genera el presente a partir del enunciado futuro. Dos iniciadores de oraciones especiales ([BOS-F] y [BOS-B]) iniciar la generación hacia adelante y hacia atrás para el decodificador. |
Resultados en subtítulos de video multimodal
Comparamos MV-GPT con pérdidas previas al entrenamiento utilizando la misma arquitectura de modelo en YouCook2 con métricas de evaluación estándar (Bleu-4, Cider, Meteor y Rouge-L). Si bien todas las técnicas de entrenamiento previo mejoran el rendimiento de los subtítulos, es crucial entrenar previamente el decodificador para mejorar el rendimiento del modelo. Mostramos que MV-GPT supera al anterior método de preentrenamiento conjunto de última generación en más de un 3,5 %, con aumentos relativos en las cuatro métricas.
| pérdida antes del entrenamiento | Piezas preentrenadas | Azul-4 | sidra | meteorito | Rojo-L |
| Sin entrenamiento previo | N / A | 13.25 | 1.03 | 17.56 | 35.48 |
| CoMVT | codificadores | 14.46 | 1.24 | 18.46 | 37.17 |
| UniVL | codificadores + decodificadores | 19.95 | 1.98 | 25.27 | 46.81 |
| MV-GPT (nuestro) | codificadores + decodificadores | 21.26 | 2.14 | 26.36 | 48.58 |
| Rendimiento de MV-GPT en cuatro métricas (Bleu-4, Cider, Meteor y Rouge-L) de varias pérdidas previas al entrenamiento en YouCook2. Partes preentrenadas indica qué partes del modelo están preentrenadas: solo el codificador o tanto el codificador como el decodificador. Reimplementamos las funciones de pérdida de los métodos existentes pero usamos nuestro modelo y estrategias de entrenamiento para una comparación justa. | ||||
Transferimos un modelo previamente entrenado por MV-GPT a cuatro puntos de referencia de subtítulos diferentes: YouCook2, MSR-VTT, ViTT y ActivityNet-Captions. Nuestro modelo logra un rendimiento de vanguardia en los cuatro puntos de referencia por un claro margen. Por ejemplo, en la métrica Meteor, MV-GPT muestra mejoras relativas de más del 12 % en los cuatro puntos de referencia.
| tucocinas2 | MSR VTT | ViTT | Etiquetas de ActivityNet | |
| mejor base | 22.35 | 29,90 | 11.00 | 10.90 |
| MV-GPT (nuestro) | 27/09 | 38.66 | 26.75 | 31.12 |
| Puntuaciones métricas de meteoritos de los mejores métodos de referencia y MV-GPT en cuatro puntos de referencia. | ||||
Resultados en tareas de comprensión de videos no generativos
Aunque MV-GPT está diseñado para entrenar un modelo generativo para subtítulos de video multimodales, también encontramos que nuestra técnica de entrenamiento previo aprende un potente codificador de video multimodal que se puede aplicar a múltiples tareas de comprensión de video, incluido VideoQA, recuperación de texto a video y clasificación de acciones. En comparación con los modelos base más comparables, el modelo transferido de MV-GPT demuestra un rendimiento superior en cinco puntos de referencia de comprensión de video para sus métricas principales, es decir, precisión superior 1 para puntos de referencia de VideoQA y clasificación de acciones y recuperación en 1 para punto de referencia de recuperación.
| tarea | Punto de referencia | Mejor línea de base comparable | GPT de media tensión |
| VideoQA | MSRVTT-QA | 41.5 | 41.7 |
| Control de calidad de ActivityNet | 38,9 | 39.1 | |
| Recuperación de texto a video | MSR VTT | 33.7 | 37.3 |
| Reconocimiento de acciones | Tarifa-400 | 78,9 | 80.4 |
| Tarifa-600 | 80.6 | 82.4 |
| Comparaciones de MV-GPT con los modelos base más comparables en cinco puntos de referencia de comprensión de video. Para cada conjunto de datos, informamos la métrica principal ampliamente utilizada, es decir, MSRVTT-QA y ActivityNet-QA: precisión de la respuesta principal 1; MSR-VTT: devolución de llamada en 1; y cinética: precisión de clasificación top 1. | ||||
resumen
Presentamos MV-GPT, un nuevo marco de preentrenamiento generativo para subtítulos de video multimodal. Nuestro objetivo generativo bidireccional entrena previamente de manera conjunta un codificador multimodal y un decodificador de subtítulos utilizando expresiones muestreadas en diferentes momentos en videos sin subtítulos. Nuestro modelo preentrenado logra resultados de vanguardia en varios puntos de referencia de subtítulos de video y otras tareas de comprensión de video, a saber, VideoQA, recuperación de video y clasificación de acciones.
Gracias
Esta investigación fue realizada por Paul Hongsuck Seo, Arsha Nagrani, Anurag Arnab y Cordelia Schmid.
[ad_2]