[ad_1]
En los últimos años, las videoconferencias han jugado un papel cada vez más importante para muchos usuarios en la comunicación tanto profesional como personal. En los últimos dos años, hemos mejorado esta experiencia en Google Meet mediante la introducción de funciones de fondo de aprendizaje automático (ML) que protegen la privacidad, también conocidas como «pantallas verdes virtuales», que permiten a los usuarios desenfocar sus fondos o reemplazarlos con otras imágenes. para reemplazar . Lo que es único acerca de esta solución es que se ejecuta directamente en el navegador sin necesidad de instalar software adicional.
Hasta la fecha, estas capacidades impulsadas por ML se basan en la inferencia de CPU habilitada al aprovechar la escasez de redes neuronales, una solución popular que funciona en todos los dispositivos, desde computadoras de nivel de entrada hasta estaciones de trabajo de gama alta. Esto permite que nuestras características lleguen a la audiencia más amplia. Sin embargo, los dispositivos de gama media y alta a menudo tienen GPU potentes que no se utilizan para la inferencia de ML, y las capacidades existentes permiten que los navegadores web accedan a las GPU a través de sombreadores (WebGL).
Con la última actualización de Google Meet, ahora estamos aprovechando el poder de las GPU para mejorar en gran medida la fidelidad y el rendimiento de estos efectos de fondo. Como detallamos en Efficient Heterogeneous Video Segmentation at the Edge, estos avances están impulsados por dos componentes principales: 1) un nuevo modelo de segmentación de video en tiempo real y 2) un nuevo enfoque altamente eficiente para la aceleración de ML en el navegador mediante WebGL. Usamos esta capacidad para desarrollar una inferencia rápida de ML sobre sombreadores de fragmentos. Esta combinación da como resultado ganancias significativas en precisión y latencia, lo que da como resultado límites de primer plano más nítidos.
 |
| Segmentación de CPU frente a segmentación de HD en Meet. |
Hacia modelos de segmentación de video de mayor calidad
Para predecir detalles más finos, nuestro nuevo modelo de segmentación ahora funciona con imágenes de entrada de alta definición (HD) en lugar de imágenes de menor resolución, duplicando efectivamente la resolución con respecto al modelo anterior. Para adaptarse a esto, el modelo debe tener una mayor capacidad para extraer características con suficiente detalle. En términos generales, duplicar la resolución de entrada cuadruplica el esfuerzo computacional durante la inferencia.
La inferencia de modelos de alta resolución usando la CPU no es factible para muchos dispositivos. La CPU puede tener algunos núcleos de alto rendimiento que le permiten ejecutar cualquier código complejo de manera eficiente, pero tiene una capacidad limitada para realizar el cálculo paralelo requerido para la segmentación HD. Por el contrario, las GPU tienen muchos núcleos con un rendimiento relativamente bajo junto con una amplia interfaz de memoria, lo que las hace especialmente adecuadas para modelos de convolución de alta resolución. Por lo tanto, para dispositivos de gama media y alta, utilizamos una canalización solo de GPU significativamente más rápida integrada a través de WebGL.
Este cambio nos ha inspirado a reconsiderar algunas de las decisiones de diseño de arquitectura modelo anteriores.
- columna vertebral: Comparamos varios backbones de red en el dispositivo ampliamente utilizados y descubrimos que EfficientNet-Lite es más adecuado para la GPU, ya que elimina el bloque de compresión y excitación, un componente que es ineficiente en WebGL (más abajo).
- descifrador: Cambiamos a un decodificador MLP (Multi-Layer Perceptron) que consta de convoluciones 1×1 en lugar de usar un muestreo ascendente bilineal simple o los bloques de compresión y excitación más costosos. MLP se ha adoptado con éxito en otras arquitecturas de segmentación, como DeepLab y PointRend, y se puede calcular de manera eficiente tanto en CPU como en GPU.
- tamaño del modelo: Con nuestra nueva inferencia WebGL y arquitectura de modelo compatible con GPU, podemos permitirnos un modelo más grande sin sacrificar la velocidad de fotogramas en tiempo real necesaria para una segmentación de video fluida. Examinamos los parámetros de ancho y profundidad mediante una búsqueda de arquitectura neuronal.
 |
| Arquitectura del modelo de segmentación HD. |
En general, estos cambios mejoran significativamente la métrica Intersección media sobre unión (IoU) en un 3 %, lo que genera menos incertidumbre y límites más nítidos alrededor del cabello y los dedos.
También emitimos la tarjeta modelo complementaria para este modelo de segmentación, que detalla nuestros puntajes de imparcialidad. Nuestro análisis muestra que el modelo es consistente en su desempeño en diferentes regiones, razas y géneros, con solo variaciones menores en las métricas de IoU.
| modelo | resolución | inferencia | pagaré | Latencia (ms) | ||||
| segmentador de CPU | 256×144 | ¿Qué SIMD? | 94,0% | 8.7 | ||||
| segmentador de GPU | 512×288 | WebGL | 96,9% | 4.3 |
| Comparación del modelo de segmentación anterior con el nuevo modelo de segmentación HD en un Macbook Pro (2018). |
Acelere Web ML con WebGL
Un desafío común para la inferencia basada en la web es que las tecnologías web pueden causar una degradación del rendimiento en comparación con las aplicaciones que se ejecutan de forma nativa en el dispositivo. Para las GPU, esta desventaja es significativa y solo logra alrededor del 25 % del rendimiento nativo de OpenGL. Esto se debe a que WebGL, el estándar de GPU actual para la inferencia basada en web, se diseñó principalmente para la representación de imágenes y no para cualquier carga de trabajo de aprendizaje automático. En particular, WebGL no incluye sombreadores de cómputo que permitan cálculos de propósito general y habilitan cargas de trabajo de ML en aplicaciones móviles y nativas.
Para resolver este desafío, aceleramos los núcleos de redes neuronales de bajo nivel con sombreadores de fragmentos, que normalmente calculan las propiedades de salida de un píxel, como el color y la profundidad, y luego aplicamos optimizaciones novedosas inspiradas en la comunidad gráfica. Dado que las cargas de trabajo de ML en las GPU a menudo están vinculadas al ancho de banda de la memoria en lugar de a la potencia de procesamiento, nos centramos en las técnicas de representación que mejorarían el acceso a la memoria, como B. Múltiples objetivos de renderizado (MRT).
MRT es una característica de las GPU modernas que permite que las imágenes se representen en múltiples texturas de salida (objetos OpenGL que representan imágenes) simultáneamente. Si bien MRT se desarrolló originalmente para admitir la representación de gráficos avanzados, como el sombreado diferido, descubrimos que podemos aprovechar esta capacidad para reducir drásticamente el uso de ancho de banda de memoria de nuestras implementaciones de sombreado de fragmentos para operaciones críticas como convoluciones y capas totalmente conectadas. Hacemos esto tratando los tensores intermedios como múltiples texturas OpenGL.
En la siguiente figura, mostramos un ejemplo de tensores intermedios, cada uno con cuatro texturas GL subyacentes. Con MRT, la cantidad de subprocesos de GPU, lo que reduce efectivamente la cantidad de solicitudes de memoria para pesos, se reduce en un factor de cuatro y ahorra el uso de ancho de banda de memoria. Aunque esto introduce complejidades significativas en el código, nos ayuda a lograr más del 90 % del rendimiento nativo de OpenGL. Cerrando la brecha con aplicaciones nativas.
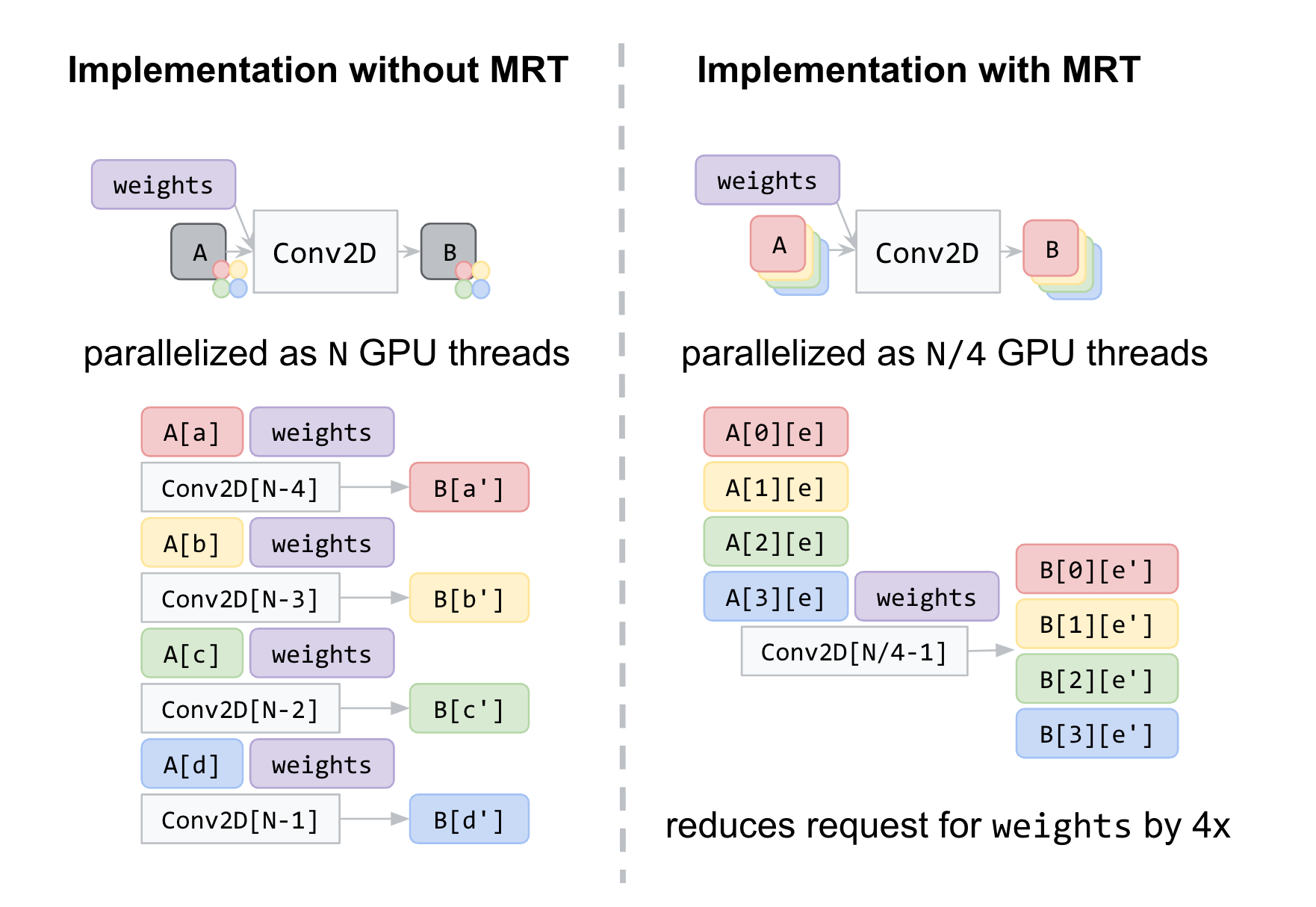 |
| Izquierda: una implementación clásica de Conv2D con correspondencia 1 a 1 de Tensor y una textura OpenGL. Los cuadros rojo, amarillo, verde y azul indican diferentes posiciones en una sola textura, respectivamente para los tensores intermedios A y B. Derecha: Nuestra implementación de Conv2D con MRI, donde los tensores intermedios A y B se realizan con un conjunto de 4 texturas GL cada uno, se muestran como cuadros rojos, amarillos, verdes y azules. Tenga en cuenta que esto reduce el recuento de solicitudes de pesos cuatro veces. |
Conclusión
Hemos progresado rápidamente en la mejora de la calidad de los modelos de segmentación en tiempo real al aprovechar la GPU en dispositivos de gama media y alta para usar con Google Meet. Esperamos con ansias las posibilidades que brindan las próximas tecnologías como WebGPU que traen sombreadores de cómputo a la web. Más allá de la inferencia de GPU, también estamos trabajando para mejorar la calidad de la segmentación para dispositivos de menor potencia con inferencia cuantificada a través de XNNPACK WebAssembly.
Gracias
Un agradecimiento especial al equipo de Meet y a otras personas que trabajaron en este proyecto, especialmente a Sebastian Jansson, Sami Kalliomäki, Rikard Lundmark, Stephan Reiter, Fabian Bergmark, Ben Wagner, Stefan Holmer, Dan Gunnarsson, Stéphane Hulaud y a todos los miembros de nuestro equipo que hicieron este posibles: Siargey Pisarchyk, Raman Sarokin, Artsiom Ablavatski, Jamie Lin, Tyler Mullen, Gregory Karpiak, Andrei Kulik, Karthik Raveendran, Trent Tolley y Matthias Grundmann.
[ad_2]