[ad_1]
Las redes neuronales convolucionales han sido la arquitectura de aprendizaje automático dominante para la visión artificial desde la introducción de AlexNet en 2012. Recientemente, los mecanismos de atención se han integrado de manera destacada en los modelos de visión, inspirados por el desarrollo de Transformers en el procesamiento del lenguaje natural. Estos métodos de atención aumentan algunas partes de los datos de entrada mientras minimizan otras partes, lo que permite que la red se concentre en partes pequeñas pero importantes de los datos. Vision Transformer (ViT) ha creado un nuevo panorama de diseños de modelos para visión por computadora que está completamente libre de convolución. ViT considera los campos de imagen como una secuencia de palabras y les aplica un codificador Transformer. Cuando se entrena con conjuntos de datos suficientemente grandes, ViT muestra un rendimiento convincente en el reconocimiento de imágenes.
Si bien los pliegues y la atención son suficientes para un buen desempeño, ninguno de los dos es necesario. Por ejemplo, MLP-Mixer utiliza un perceptrón multicapa (MLP) simple para mezclar parches de imagen en todas las posiciones espaciales, lo que da como resultado una arquitectura totalmente MLP. Es una alternativa competitiva a los modelos de visión de última generación existentes en términos de compensación entre la precisión y el cálculo necesarios para el entrenamiento y la inferencia. Sin embargo, tanto los modelos ViT como MLP tienen dificultades para escalar a una resolución de entrada más alta, ya que la complejidad computacional aumenta cuadráticamente con el tamaño de la imagen.
Hoy presentamos un nuevo enfoque multieje que es simple y efectivo, mejora los modelos ViT y MLP originales, es más adaptable a tareas de predicción densas y de alta resolución y, por supuesto, puede adaptarse a diferentes tamaños de entrada con alta flexibilidad y bajo complejidad. Sobre la base de este enfoque, hemos desarrollado dos modelos de columna vertebral para tareas de visión de alto y bajo nivel. Describimos el primero en «MaxViT: Multi-Axis Vision Transformer» que se presentará en ECCV 2022 y mostramos que mejora significativamente el estado del arte para tareas de alto nivel como clasificación de imágenes, detección de objetos, segmentación, evaluación de calidad, y Generación. El segundo, presentado en MAXIM: Multi-Axis MLP for Image Processing en CVPR 2022, se basa en una arquitectura similar a UNet y logra un rendimiento competitivo en tareas de procesamiento de imágenes de bajo nivel, que incluyen eliminación de ruido, desenfoque, eliminación de neblina, derrain y poca luz. reforzamiento. Para facilitar una mayor investigación sobre modelos eficientes de transformadores y MLP, hemos creado el código y los modelos para MaxViT y MAXIM de código abierto.
 |
| Una demostración de desenfoque de imagen con MAXIM cuadro por cuadro. |
visión general
Nuestro nuevo enfoque se basa en la atención de varios ejes, que descompone la atención de tamaño completo utilizada en ViT (cada píxel se ocupa de todos los píxeles) en dos formas dispersas: local y (escasa) global. Como se muestra en la imagen a continuación, la atención multieje incluye una pila secuencial de atención de bloque y atención de cuadrícula. La atención de bloque funciona en ventanas que no se superponen (pequeñas manchas en mapas de características intermedias) para capturar patrones locales, mientras que la atención de cuadrícula funciona en una cuadrícula uniforme escasamente muestreada para interacciones de largo alcance (globales). Los tamaños de ventana de las atenciones de bloque y ráster se pueden controlar completamente como hiperparámetros para garantizar una complejidad computacional lineal al tamaño de entrada.
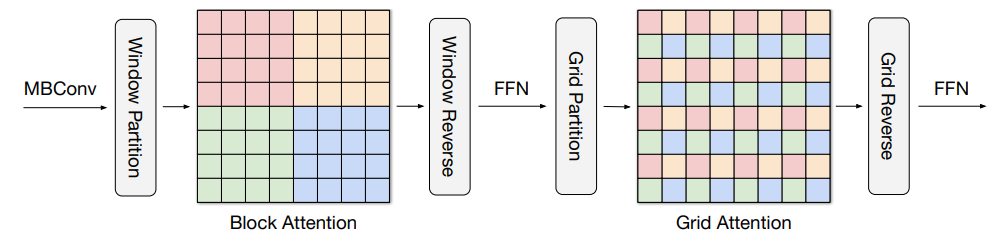 |
| La atención multieje propuesta dirige la atención local bloqueada y la atención global extendida, seguida de un FFN, con solo complejidad lineal. Los píxeles de los mismos colores se fusionan. |
Tal atención de baja complejidad puede mejorar en gran medida su amplia aplicabilidad a muchas tareas visuales, especialmente para predicciones visuales de alta resolución, y demostrar una mayor generalidad que la atención original utilizada en ViT. Construimos dos instancias de columna vertebral a partir de este enfoque de atención de múltiples ejes: MaxViT y MAXIM, para tareas de alto y bajo nivel, respectivamente.
MaxViT
En MaxViT, primero construimos un solo bloque MaxViT (ver a continuación) concatenando MBConv (propuesto por EfficientNet, V2) con la atención multieje. Este bloque único puede codificar información visual local y global independientemente de la resolución de entrada. Luego, simplemente apilamos bloques repetidos de atención y convoluciones en una arquitectura jerárquica (similar a ResNet, CoAtNet), lo que da como resultado nuestra arquitectura MaxViT homogénea. Sorprendentemente, MaxViT difiere de los enfoques jerárquicos anteriores, ya que puede «ver» toda la red globalmente, incluso en fases anteriores de alta resolución, y demuestra una mayor capacidad de modelado para diferentes tareas.
 |
| La metaarquitectura de MaxViT. |
MÁXIMA
Nuestra segunda columna vertebral, MAXIM, es una arquitectura genérica similar a UNet diseñada para tareas de predicción de imagen a imagen de bajo nivel. MAXIM investiga diseños paralelos de enfoques locales y globales utilizando la red Gated Multi-Layer Perceptron (gMLP) (MLP de mezcla de parches con un mecanismo de activación). Otra contribución de MAXIM es el bloque Cross-Gating, que se puede utilizar para aplicar interacciones entre dos señales de entrada diferentes. Este bloque puede servir como una alternativa eficiente al módulo de atención cruzada, ya que utiliza solo los operadores MLP controlados económicos para interactuar con varias entradas sin depender de la atención cruzada computacionalmente intensiva. Además, todos los componentes propuestos, incluido el MLP con compuerta y los bloques con compuerta cruzada en MAXIM, disfrutan de una complejidad lineal en el tamaño de la imagen, lo que hace que sea aún más eficiente para procesar imágenes de alta resolución.
Resultados
Demostramos la efectividad de MaxViT en una amplia gama de tareas visuales. En la clasificación de imágenes, MaxViT logra resultados de última generación en varias configuraciones: con solo el entrenamiento de ImageNet 1K, MaxViT logra una precisión máxima de 86,5 %; con el entrenamiento previo ImageNet-21K (14 millones de imágenes, 21 000 clases), MaxViT logra una precisión del 88,7 %; y con entrenamiento previo JFT (300 millones de imágenes, 18 000 clases), nuestro modelo más grande MaxViT-XL logra una alta precisión del 89,5 % con 475 millones de parámetros.
 |
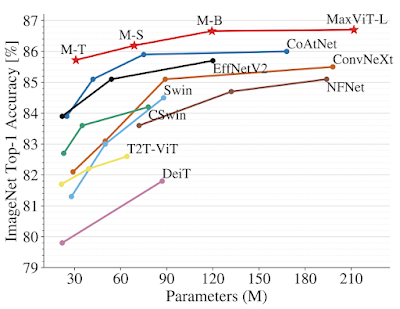 |
| Comparación de rendimiento de MaxViT con modelos de última generación en ImageNet-1K. arriba: Escalado de precisión frente a FLOP con resolución de imagen de 224×224. abajo: Precisión frente a la curva de escalado de parámetros en la configuración de ajuste fino de ImageNet 1K. |
Para tareas posteriores, MaxViT como columna vertebral ofrece un buen valor para una amplia gama de tareas. Para la detección y segmentación de objetos en el conjunto de datos COCO, la red troncal MaxViT logra 53,4 AP, superando a otros modelos base y requiriendo solo alrededor del 60 % del costo computacional. Para la evaluación de la estética de la imagen, el modelo MaxViT mejora el modelo MUSIQ de última generación en un 3,5 % en términos de correlación lineal con los valores de opinión humana. El dispositivo MaxViT independiente también demuestra un rendimiento efectivo de generación de imágenes, logrando mejores valores de FID e IS en la tarea de generación incondicional de ImageNet 1K con una cantidad significativamente menor de parámetros que el modelo HiT de última generación.
La red troncal MAXIM similar a UNet, adaptada para tareas de procesamiento de imágenes, también ha mostrado resultados de última generación en 15 de los 20 conjuntos de datos probados, incluida la reducción de ruido, desenfoque, eliminación de lluvia, eliminación de neblina y mejora con poca luz. mientras que requiere menos o un número comparable de parámetros y FLOP como modelos de la competencia. Las imágenes restauradas por MAXIM muestran más detalles restaurados con menos artefactos visuales.
 |
| Resultados visuales de MAXIM para desenfoque de imagen, drenaje y mejora con poca luz. |
resumen
El trabajo reciente de los últimos dos o más años ha demostrado que ConvNets y Vision Transformers pueden lograr un rendimiento similar. Nuestro trabajo presenta un diseño unificado que aprovecha lo mejor de ambos mundos (convolución eficiente y poca atención) y demuestra que un modelo construido sobre él, a saber, MaxViT, puede lograr un rendimiento de vanguardia en una variedad de tareas visuales. . Más importante aún, MaxViT escala bien a grandes cantidades de datos. También mostramos que un diseño multieje alternativo que utiliza operadores MLP, MAXIM, logra un rendimiento de vanguardia en una amplia gama de tareas de visión de bajo nivel.
Aunque presentamos nuestros modelos en el contexto de las tareas de visión, el enfoque multieje propuesto se puede extender fácilmente al modelado de lenguaje para capturar las dependencias locales y globales en tiempo lineal. Motivados por el trabajo aquí, anticipamos que valdrá la pena investigar otras formas de atención dispersa en señales multimodales o de dimensiones superiores, como videos, nubes de puntos y modelos de lenguaje visual.
Hemos puesto a disposición del público el código y los modelos de MAXIM y MaxViT para facilitar futuras investigaciones sobre modelos eficientes de atención y MLP.
Gracias
Agradecemos a nuestros coautores: Hossein Talebi, Han Zhang, Feng Yang, Peyman Milanfar y Alan Bovik. También nos gustaría agradecer a Xianzhi Du, Long Zhao, Wuyang Chen, Hanxiao Liu, Zihang Dai, Anurag Arnab, Sungjoon Choi, Junjie Ke, Mauricio Delbracio, Irene Zhu, Innfarn Yoo, Huiwen Chang y Ce Liu por su valiosa discusión y apoyo. .
[ad_2]