[ad_1]
El aprendizaje robótico se ha aplicado a una amplia gama de tareas desafiantes del mundo real, incluida la manipulación hábil, la locomoción de las piernas y el agarre. El aprendizaje de robots se aplica con menos frecuencia a tareas dinámicas de alta aceleración que requieren interacciones estrechas entre humanos y robots, como B. Tenis de mesa. Hay dos propiedades complementarias de la tarea del tenis de mesa que la hacen interesante para la investigación del aprendizaje de robots. En primer lugar, la tarea requiere velocidad y precisión, lo que impone demandas significativas a un algoritmo de aprendizaje. Al mismo tiempo, el problema está muy estructurado (con un entorno fijo y predecible) y naturalmente multiagente (el robot puede jugar con humanos u otro robot), lo que lo convierte en un campo de pruebas deseable para investigar problemas de interacción humano-robot e investigar aprendizaje reforzado. Estas propiedades han llevado a varios grupos de investigación a desarrollar plataformas de investigación de tenis de mesa. [1, 2, 3, 4].
El equipo de robótica de Google construyó una plataforma de este tipo para estudiar los problemas que surgen del aprendizaje de robots en un entorno multijugador dinámico e interactivo. En el resto de esta publicación, presentamos dos proyectos, Iterative-Sim2Real (que se presentará en CoRL 2022) y GoalsEye (IROS 2022), que ilustran los problemas que hemos explorado hasta ahora. Iterative-Sim2Real permite que un robot realice jugadas de más de 300 aciertos con un jugador humano, mientras que GoalsEye permite aprender pautas basadas en objetivos que coinciden con la precisión de los humanos aficionados.
| Las políticas iterativas de Sim2Real juegan cooperativamente con humanos (arriba) y una política de GoalsEye que devuelve balones a diferentes lugares (abajo). |
Iterative-Sim2Real: Usar un simulador para jugar en cooperativo con humanos
En este proyecto, el objetivo es que el robot cooperativa en la naturaleza: corre un rally con un humano durante el mayor tiempo posible. Dado que sería tedioso y llevaría mucho tiempo entrenar directamente contra un jugador humano en el mundo real, adoptamos un enfoque basado en simulación (es decir, de simulación a realidad). Sin embargo, debido a que es difícil simular con precisión el comportamiento humano, es difícil aplicar el aprendizaje simulado a real a tareas que requieren una interacción cercana e íntima con un participante humano.
En Iterative-Sim2Real (es decir, i-S2R) presentamos un método para aprender modelos de comportamiento humano para tareas de interacción humano-robot y los instanciamos en nuestra plataforma de tenis de mesa robot. Hemos construido un sistema que puede lograr rallies de hasta 340 golpes con un jugador humano aficionado (ver más abajo).
| Un rally de 340 hits que dura más de 4 minutos. |
Aprendizaje de modelos de comportamiento humano: un problema del huevo y la gallina
El problema clave en el aprendizaje de modelos precisos de comportamiento humano para la robótica es el siguiente: si no tenemos una política de robots lo suficientemente buena, no podremos recopilar datos de alta calidad sobre cómo una persona podría interactuar con el robot. Pero sin un modelo de comportamiento humano, no podemos obtener políticas de robots en absoluto. Una alternativa sería entrenar una política de robots directamente en el mundo real, pero esto suele ser lento, costoso y plantea desafíos de seguridad que se exacerban cuando hay humanos involucrados. El i-S2R que se muestra a continuación es una solución a este problema del huevo y la gallina. Utiliza un modelo simple de comportamiento humano como punto de partida aproximado, alternando entre entrenamiento en simulación y despliegue en el mundo real. En cada iteración, se refinan tanto el modelo de comportamiento humano como la política.
 |
| Metodología i-S2R. |
Resultados
Para evaluar i-S2R, repetimos el proceso de entrenamiento cinco veces con cinco oponentes humanos diferentes y lo comparamos con un enfoque de referencia de sim-to-real ordinario más ajuste fino (S2R+FT). Agregado entre todos los jugadores, la duración del rally i-S2R es aproximadamente un 9 % más alta que S2R+FT (abajo a la izquierda). El histograma de la duración de los rallies para i-S2R y S2R+FT (abajo a la derecha) muestra que una gran proporción de los rallies para S2R+FT son más cortos (es decir, menos de 5), mientras que i-S2R suele lograr rallies más largos.
 |
| Resumen de los resultados de i-S2R. Detalles del diagrama de caja: el círculo blanco es la media, la línea horizontal es la mediana, los límites de la caja son los percentiles 25 y 75. |
También desglosamos los resultados por tipo de jugador: Principiante (40 % de los jugadores), Intermedio (40 % de los jugadores) y Avanzado (20 % de los jugadores). Vemos que i-S2R claramente supera a S2R+FT tanto para principiantes como para jugadores avanzados (80 % de los jugadores).
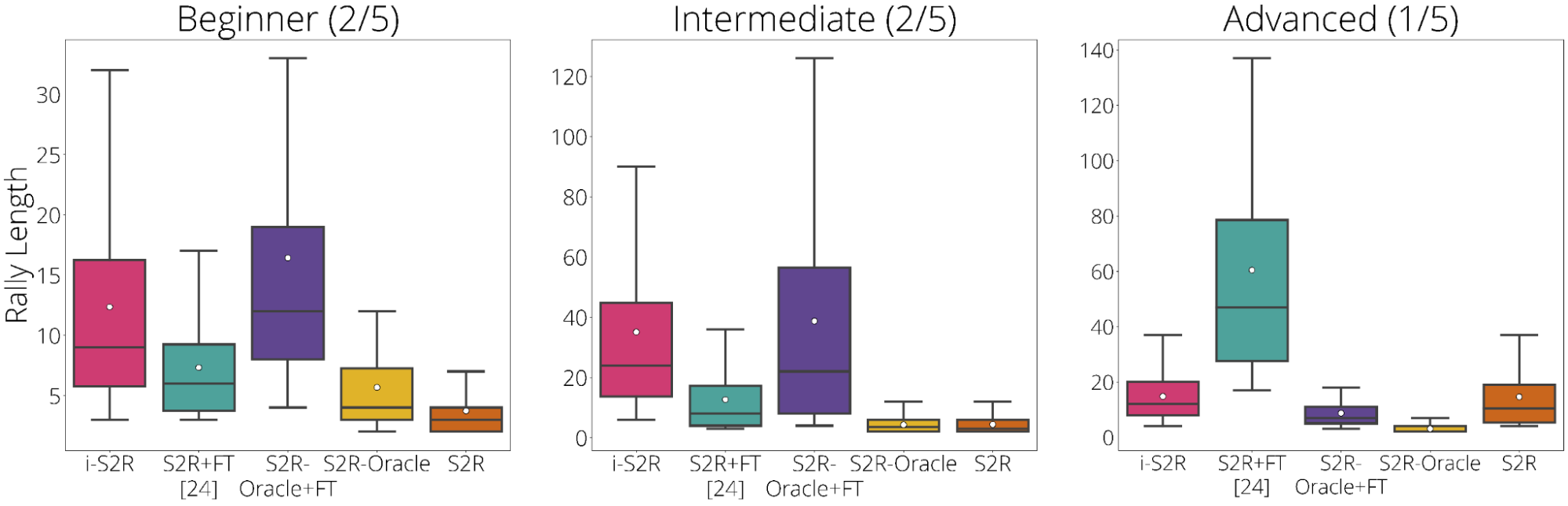 |
| Resultados i-S2R por tipo de jugador. |
Se pueden encontrar más detalles sobre i-S2R en nuestra preimpresión, nuestro sitio web y también en el video resumen a continuación.
GoalsEye: Aprende a devolver balones con precisión en un robot físico
Si bien nos enfocamos en el aprendizaje de simulación a realidad en i-S2R, a veces es deseable aprender solo con datos del mundo real; cerrar la brecha de simulación a realidad es innecesario en este caso. El aprendizaje por imitación (IL) proporciona un enfoque simple y estable para el aprendizaje del mundo real, pero requiere acceso a la demostración y no puede exceder la capacidad del maestro. La recopilación de demostraciones humanas expertas de la adquisición precisa de objetivos en entornos de alta velocidad es un desafío y, a veces, imposible (debido a la precisión limitada del movimiento humano). Si bien el aprendizaje por refuerzo (RL) es muy adecuado para tales tareas de alta velocidad y alta precisión, se enfrenta a un problema de exploración difícil (especialmente al principio) y puede ser muy ineficiente para la muestra. En GoalsEye, demostramos un enfoque que combina técnicas actuales de clonación de comportamiento [5, 6] para aprender una política dirigida precisa a partir de un conjunto de datos pequeño, débilmente estructurado y no dirigido.
Aquí consideramos otro problema de tenis de mesa con énfasis en la precisión. Queremos que el robot devuelva la pelota a cualquier posición objetivo en la mesa, p. B. «golpear la esquina trasera izquierda» o «dejar caer el balón directamente sobre la red en el lado derecho» (ver el video de la izquierda a continuación). También queríamos encontrar un método que pudiera usarse directo en nuestro entorno real de tenis de mesa sin simulación. Descubrimos que la síntesis de dos técnicas de aprendizaje por imitación existentes, el aprendizaje del juego (LFP) y el aprendizaje supervisado condicionado por objetivos (GCSL), es apropiada para este entorno. Es lo suficientemente seguro y poderoso como para entrenar la estrategia en un robot físico que es tan preciso como un humano aficionado en la tarea de devolver las bolas a objetivos específicos en la mesa.
| GoalsEye política dirigida a un objetivo de 20 cm de diámetro (Izquierda). Jugador humano apuntando al mismo objetivo (A la derecha). |
Los ingredientes esenciales para el éxito son:
- Un conjunto de datos de «arranque» mínimo pero no dirigido del robot golpeando la pelota para superar un problema de exploración inicialmente difícil.
- Retrospectiva renombrada clonación conductual condicionada por objetivos (GCBC) para entrenar una política dirigida a objetivos para lograr cada objetivo en el conjunto de datos.
- Consecución iterativa de objetivos autosupervisados. El agente mejora continuamente estableciendo objetivos aleatorios e intentando alcanzarlos utilizando la política actual. Todas las pruebas se renombran y se agregan a un conjunto de entrenamiento en continuo crecimiento. Este auto practicadonde el robot amplía los datos de entrenamiento estableciendo objetivos y tratando de alcanzarlos se repite iterativamente.
 |
| Metodología GoalsEye. |
Las demostraciones y la superación personal a través de la práctica son clave.
La síntesis de técnicas es crucial. El objetivo de la política es devolver un diversidad de bolas entrantes a ningún Posición en el lado de la mesa del oponente. Una guía entrenada en las primeras 2480 demostraciones solo da en el blanco con precisión dentro de los 30 cm el 9% del tiempo. Sin embargo, después de que una pauta haya practicado aproximadamente 13 500 intentos, la precisión del logro de la meta aumenta al 43 % (abajo a la derecha). Esta mejora es claramente visible como se muestra en los videos a continuación. Sin embargo, si una política es solo auto-práctica, la educación en este marco fracasa por completo. Curiosamente, el número de demostraciones mejora la eficiencia de la autopráctica posterior, aunque con rendimientos decrecientes. Esto indica que los datos de demostración y el autoejercicio podrían sustituirse según el tiempo y el costo relativos para recopilar datos de demostración en comparación con el autoejercicio.
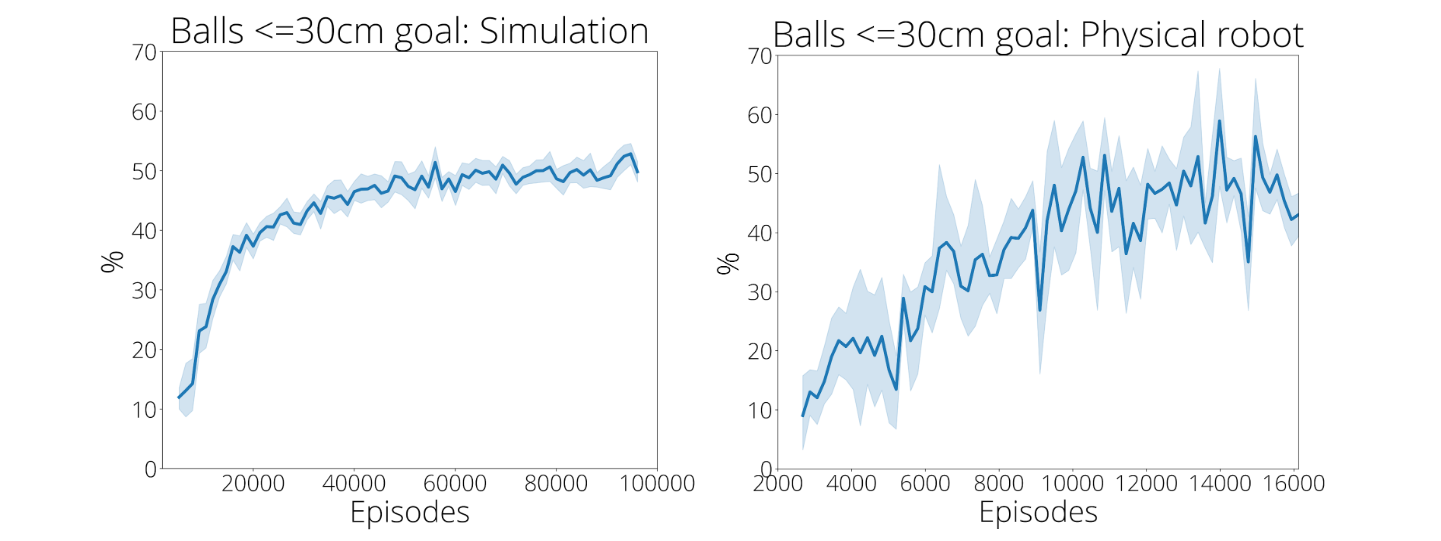 |
| La auto-práctica mejora en gran medida la precisión. Izquierda: entrenamiento simulado. Derecha: entrenamiento de robots reales. Los conjuntos de datos de demostración contienen ~2500 episodios, tanto en simulación como en el mundo real. |
| Visualización de los beneficios de la auto-práctica. Izquierda: Política entrenada en primeras 2.480 manifestaciones. Derecha: Política después de otros 13.500 intentos de autoejercicio. |
Se pueden encontrar más detalles sobre GoalsEye en la preimpresión y en nuestro sitio web.
Conclusión y trabajo futuro
Presentamos dos proyectos complementarios utilizando nuestra plataforma de investigación de tenis de mesa robótico. i-S2R aprende políticas de RL capaces de interactuar con humanos, mientras que GoalsEye demuestra que el aprendizaje a partir de datos no estructurados del mundo real combinado con la práctica autosupervisada es eficaz para ofrecer políticas orientadas a objetivos en un entorno dinámico y preciso para aprender.
Una línea de investigación interesante que podría llevarse a cabo en la plataforma de tenis de mesa sería construir un «entrenador» robótico que pudiera adaptar su estilo de juego al nivel de habilidad del participante humano, manteniendo las cosas desafiantes y emocionantes.
Gracias
Agradecemos a nuestros coautores Saminda Abeyruwan, Alex Bewley, Krzysztof Choromanski, David B. D’Ambrosio, Tianli Ding, Deepali Jain, Corey Lynch, Pannag R. Sanketi, Pierre Sermanet y Anish Shankar. También estamos agradecidos por el apoyo de muchos miembros del equipo de robótica, que se enumeran en las secciones de agradecimientos de los documentos.
[ad_2]