
[ad_1]
Amazon SageMaker Data Wrangler es una herramienta de preparación de datos basada en la interfaz de usuario que admite el análisis, el preprocesamiento y la visualización de datos con capacidades para limpiar, transformar y preparar datos con mayor rapidez. Las plantillas de flujo preconstruidas de Data Wrangler ayudan a los científicos de datos y a los profesionales del aprendizaje automático (ML) a acelerar la preparación de datos al ayudarlos a acelerar y comprender los patrones de flujo de datos de mejores prácticas utilizando conjuntos de datos compartidos.
Puede utilizar los flujos de Data Wrangler para realizar las siguientes tareas:
- Visualización de datos – Examine las propiedades estadísticas de cada columna en el conjunto de datos, cree histogramas, examine valores atípicos
- limpieza de datos – Eliminar duplicados, eliminar o completar entradas con valores faltantes, eliminar valores atípicos
- Enriquecimiento de datos e ingeniería de características – Procesar columnas para crear características más significativas, seleccionando un subconjunto de características para entrenamiento
Esta publicación lo ayudará a comprender Data Wrangler utilizando los siguientes flujos de ejemplo prediseñados en GitHub. El repositorio muestra transformaciones de datos tabulares, transformaciones de datos de series temporales y transformaciones de conjuntos de datos relacionados. Cada uno, por su naturaleza fundamental, requiere un tipo diferente de transformación. Los datos tabulares o transversales estándar se recopilan en un momento específico. Por el contrario, los datos de series temporales se recopilan repetidamente a lo largo del tiempo, y cada punto de datos sucesivo depende de sus valores anteriores.
Veamos un ejemplo de cómo podemos usar el flujo de datos de muestra para datos tabulares.
requisitos
Data Wrangler es una función de Amazon SageMaker disponible en Amazon SageMaker Studio, por lo que debemos seguir el proceso de incorporación de Studio para iniciar el entorno y los cuadernos de Studio. Aunque tiene algunos métodos de autenticación para elegir, la forma más fácil de crear un dominio de Studio es seguir las instrucciones de inicio rápido. Quick Start utiliza la misma configuración predeterminada que la configuración estándar de Studio. También puede optar por incorporarse mediante AWS IAM Identity Center (sucesor de AWS Single Sign-On) para la autenticación (consulte Incorporación de dominios de Amazon SageMaker mediante IAM Identity Center).
Importe el conjunto de datos y los archivos de flujo a Data Wrangler usando Studio
Los siguientes pasos describen cómo importar datos a SageMaker para que los utilice Data Wrangler:
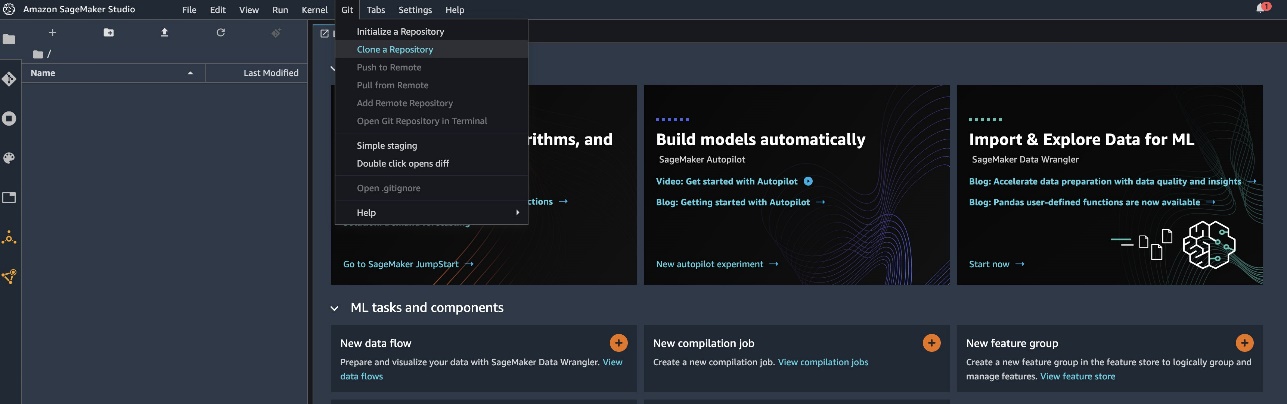
Inicialice Data Wrangler desde la interfaz de usuario de Studio seleccionando Nuevo flujo de datos.

Clone el repositorio de GitHub para descargar los archivos de flujo a su entorno de Studio.
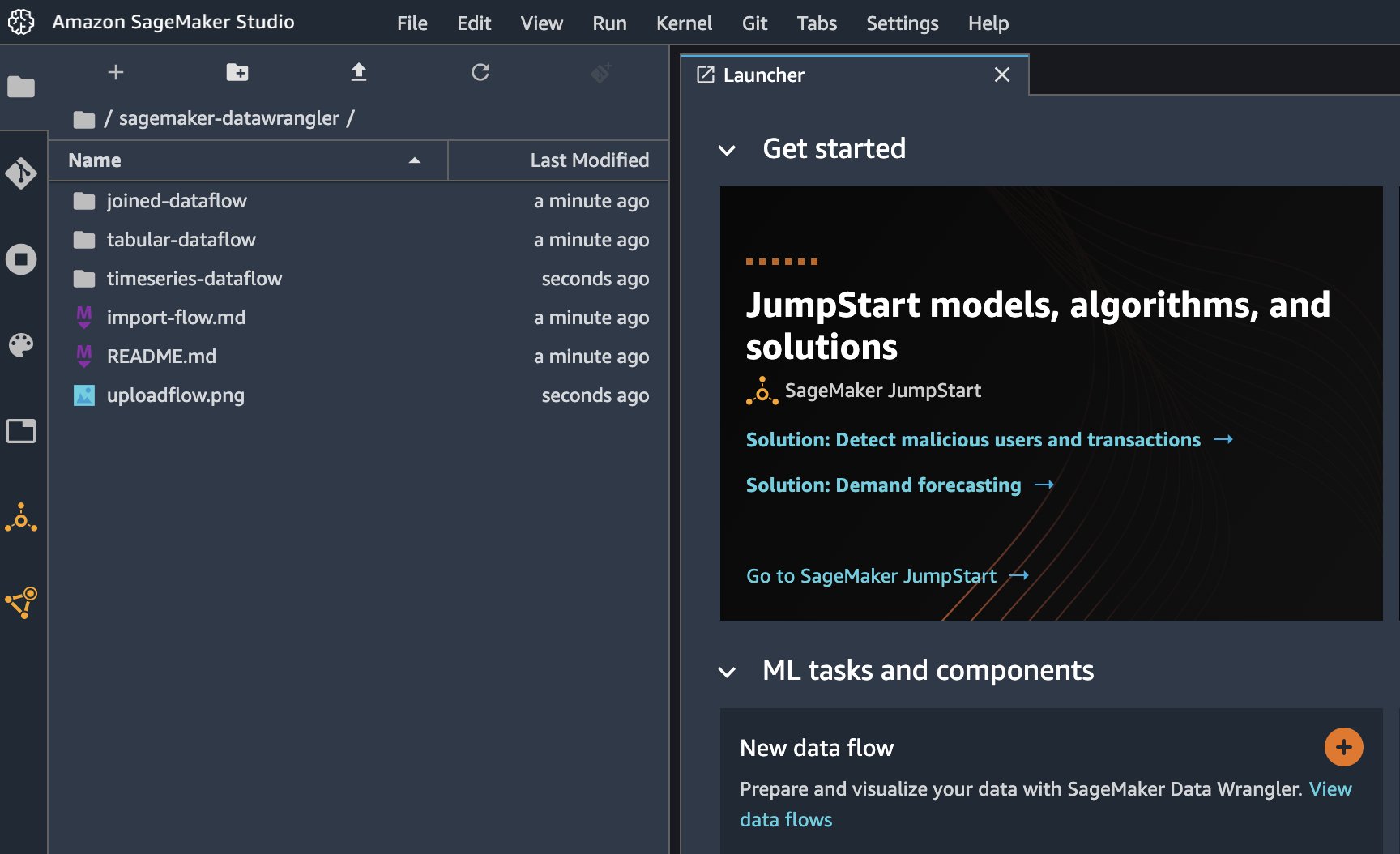
Cuando se complete la clonación, debería poder ver el contenido del repositorio en el panel izquierdo.
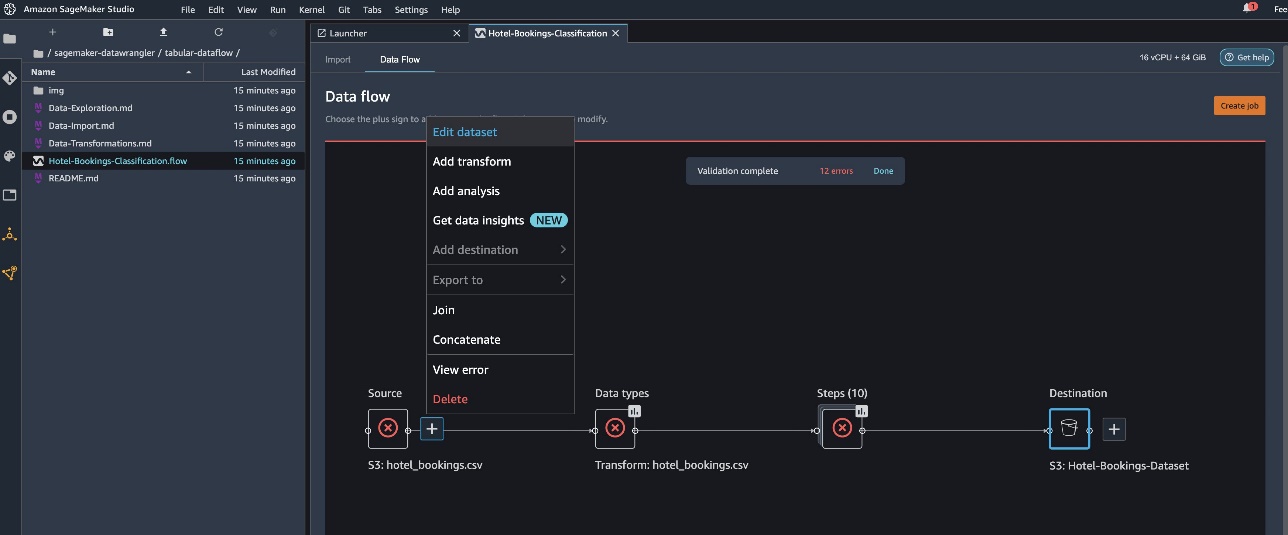
Seleccione el archivo Hotel-Reservas-Clasificación.flow para importar el archivo de flujo a Data Wrangler.
Si está utilizando la serie temporal o el flujo de datos vinculados, el flujo aparece con un nombre diferente. Después de importar el flujo, debería ver la siguiente captura de pantalla. Esto nos muestra errores, ya que debemos asegurarnos de que el archivo de flujo apunte a la fuente de datos correcta en Amazon Simple Storage Service (Amazon S3).
Elegir Editar registro para ver todos sus cubos S3. A continuación, seleccione el registro hotel_bookings.csv desde su depósito S3 para atravesar el flujo de datos tabulares.
Tenga en cuenta que al usar el flujo de datos conectado, es posible que deba importar varios conjuntos de datos a Data Wrangler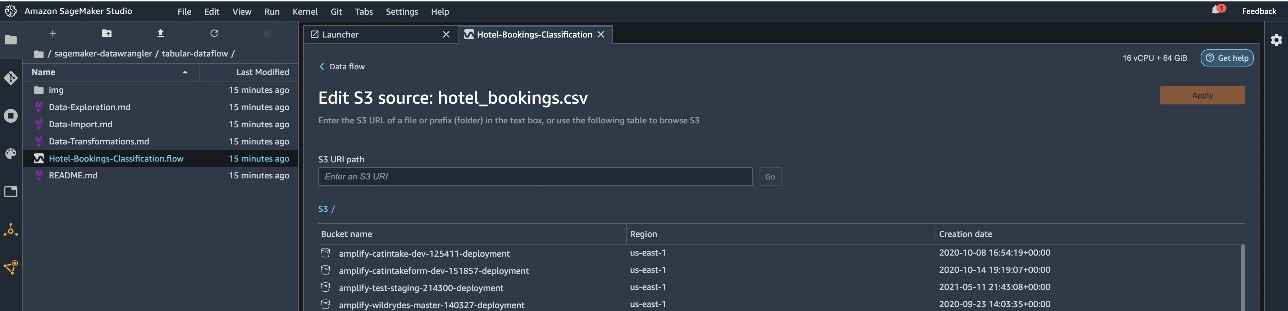
Asegúrese de que en el panel derecho COMA como separador y se selecciona muestreo se establece en primera k. Nuestro conjunto de datos es lo suficientemente pequeño como para ejecutar transformaciones de Data Wrangler en el conjunto de datos completo, pero queríamos resaltar cómo puede importar el conjunto de datos. Si tiene un conjunto de datos grande, considere usar el muestreo. Elegir Importar para importar ese registro a Data Wrangler.
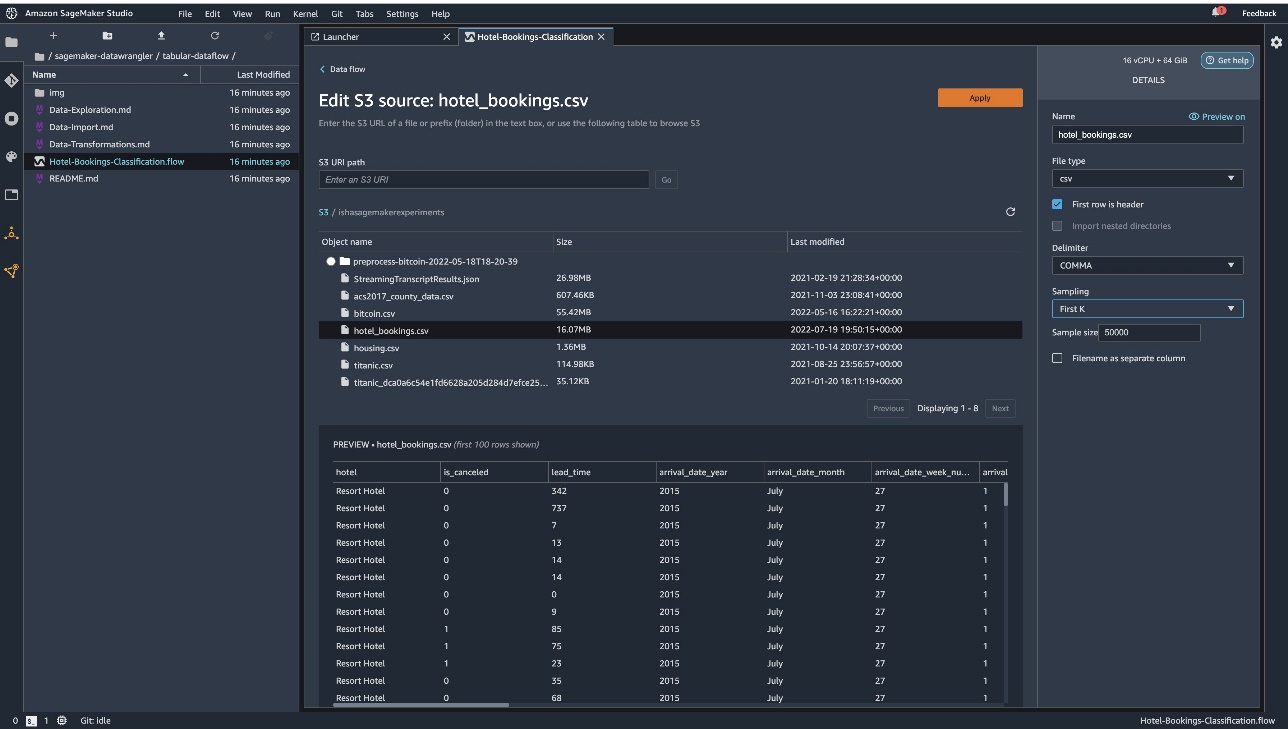
Después de importar el conjunto de datos, Data Wrangler valida automáticamente el conjunto de datos y reconoce los tipos de datos. Puede ver que los errores desaparecieron cuando señalamos el registro correcto. El editor de flujo ahora muestra dos bloques que muestran que los datos se importaron de una fuente y se reconocieron los tipos de datos. También puede editar los tipos de datos si es necesario.
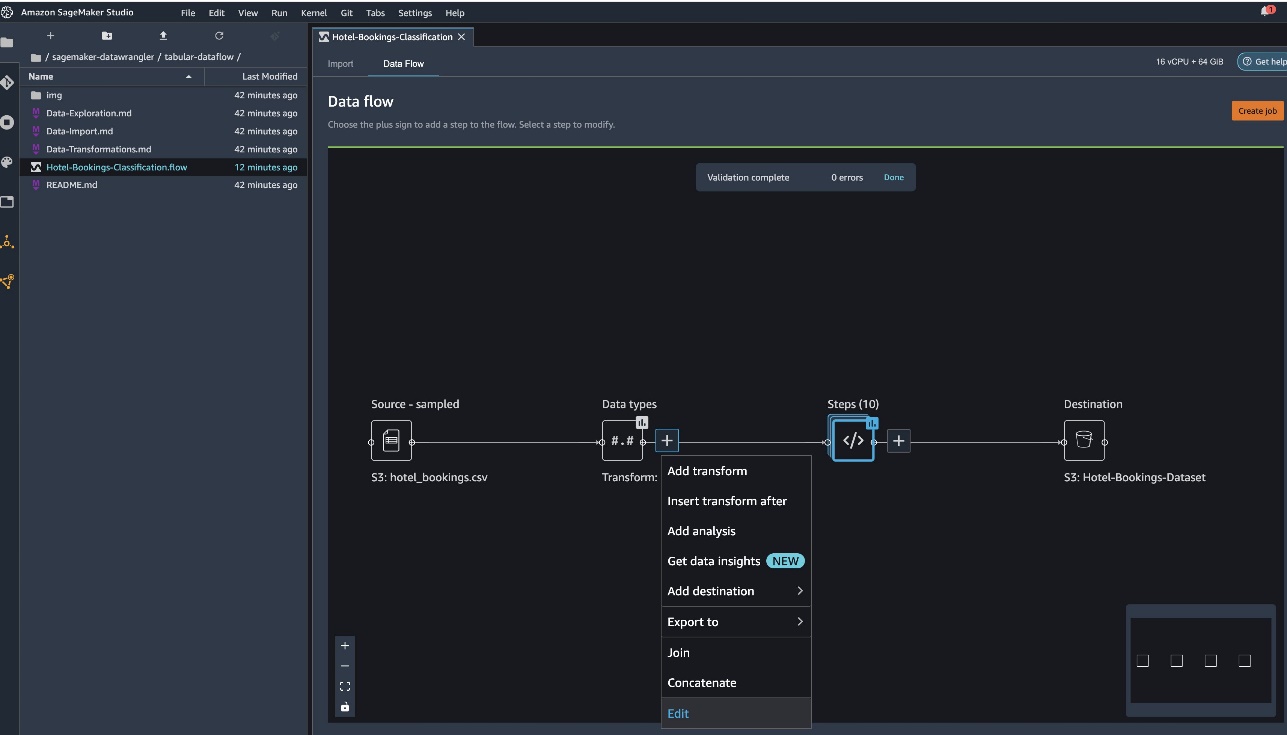
La siguiente captura de pantalla muestra nuestros tipos de datos.
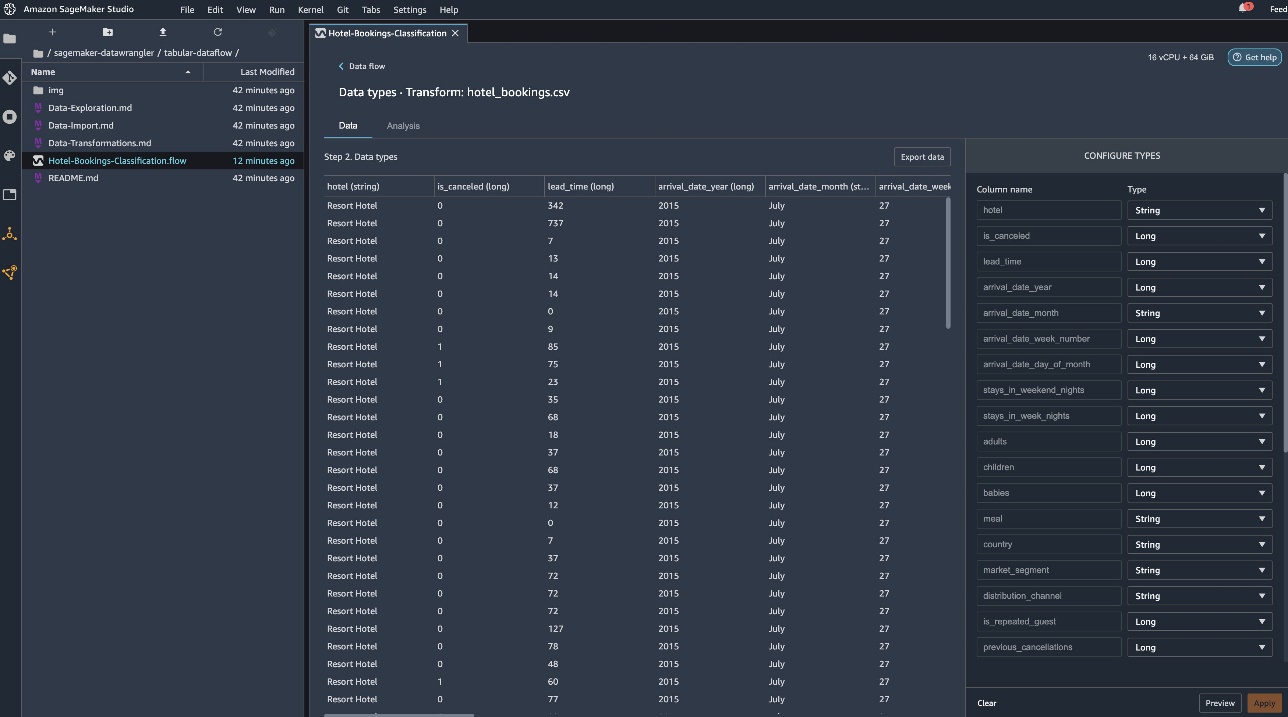
Veamos algunas de las transformaciones realizadas como parte de este flujo tabular. Si usa series temporales o flujos de datos conectados, consulte algunas transformaciones comunes en el repositorio de GitHub. Realizamos algunos análisis de datos exploratorios básicos utilizando informes de información de datos que examinan la fuga de objetivos y la colinealidad de características en el conjunto de datos, el análisis de resumen de tablas y las capacidades de modelado rápido. Consulte los pasos en el repositorio de GitHub.
Ahora estamos eliminando columnas según las recomendaciones del Informe de calidad y estadísticas de datos.
- Gota para fuga objetivo estado de la reserva.
- Eliminar para columnas redundantes días_en_lista_espera, hotel, tipo_habitación_reservada, fecha_llegada_mes, fecha_estado_reserva, bebés, y fecha_de_llegada_día_del_mes.
- Descartar columnas basadas en resultados de correlación lineal fecha de llegada_número de semana y fecha_de_llegada_año ya que los valores de correlación para estos pares de características (columnas) son mayores que el umbral recomendado de 0,90.
- Basado en resultados de correlación no lineal estado de la reserva. Esta columna ya se marcó para su eliminación según el análisis de fuga objetivo.
- Procesar valores numéricos (escala min-max) para Lead_time, stays_in_weekend_nights, stays_in_weekday_nights, is_repeated_guest, an_cancellations, an_bookings_not_canceled, booking_changes, adr, total_of_specific_requests, y estacionamiento_requerido.
- Codificación one-hot de variables categóricas como comida, is_repeat_guest, segmento de mercado, added_room_type, deposit_type, y tipo de cliente.
- Equilibre la variable objetivo. Sobremuestreo aleatorio para desequilibrio de clases. Utilice la función de modelado rápido para manejar valores atípicos y faltantes.
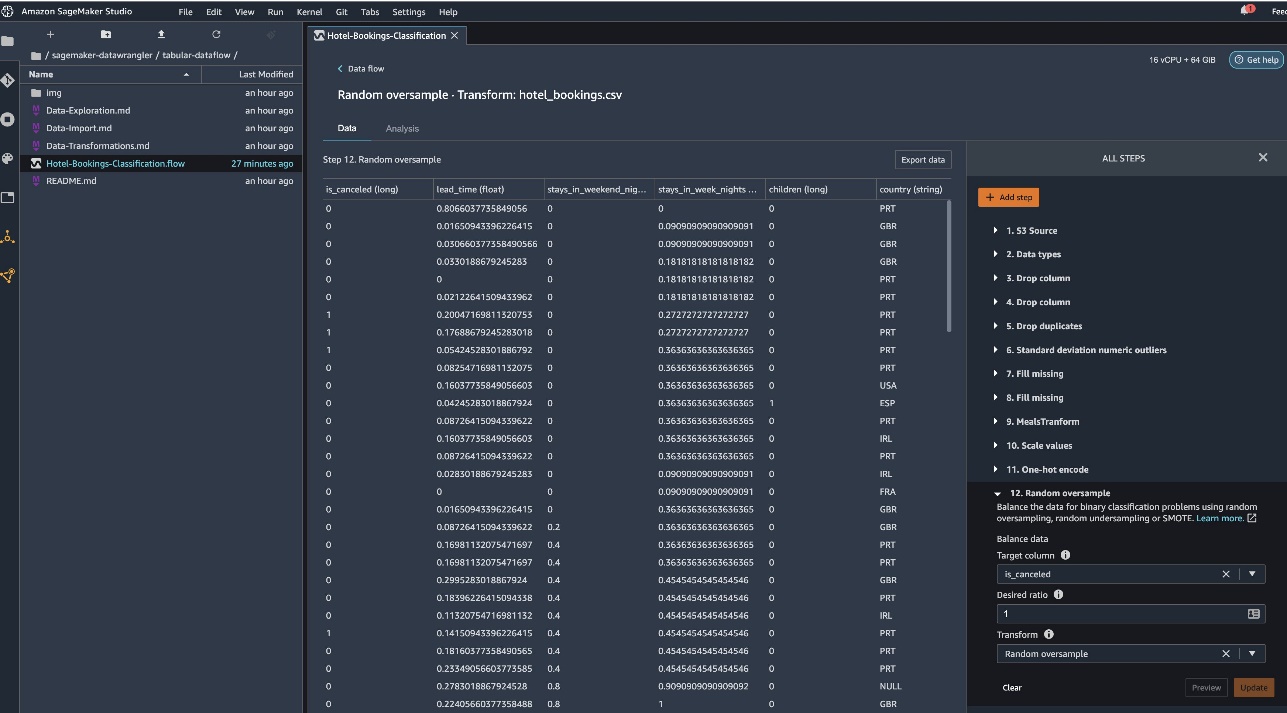
Exportar a Amazon S3
Ahora hemos pasado por varias transformaciones y estamos listos para exportar los datos a Amazon S3. Esta opción crea un trabajo de procesamiento de SageMaker que ejecuta el flujo de procesamiento de Data Wrangler y guarda el conjunto de datos resultante en un depósito de S3 específico. Siga los siguientes pasos para configurar la exportación a Amazon S3:
Elija el signo más junto a una colección de elementos de transformación y seleccione Agregar objetivodespués Amazonas S3.
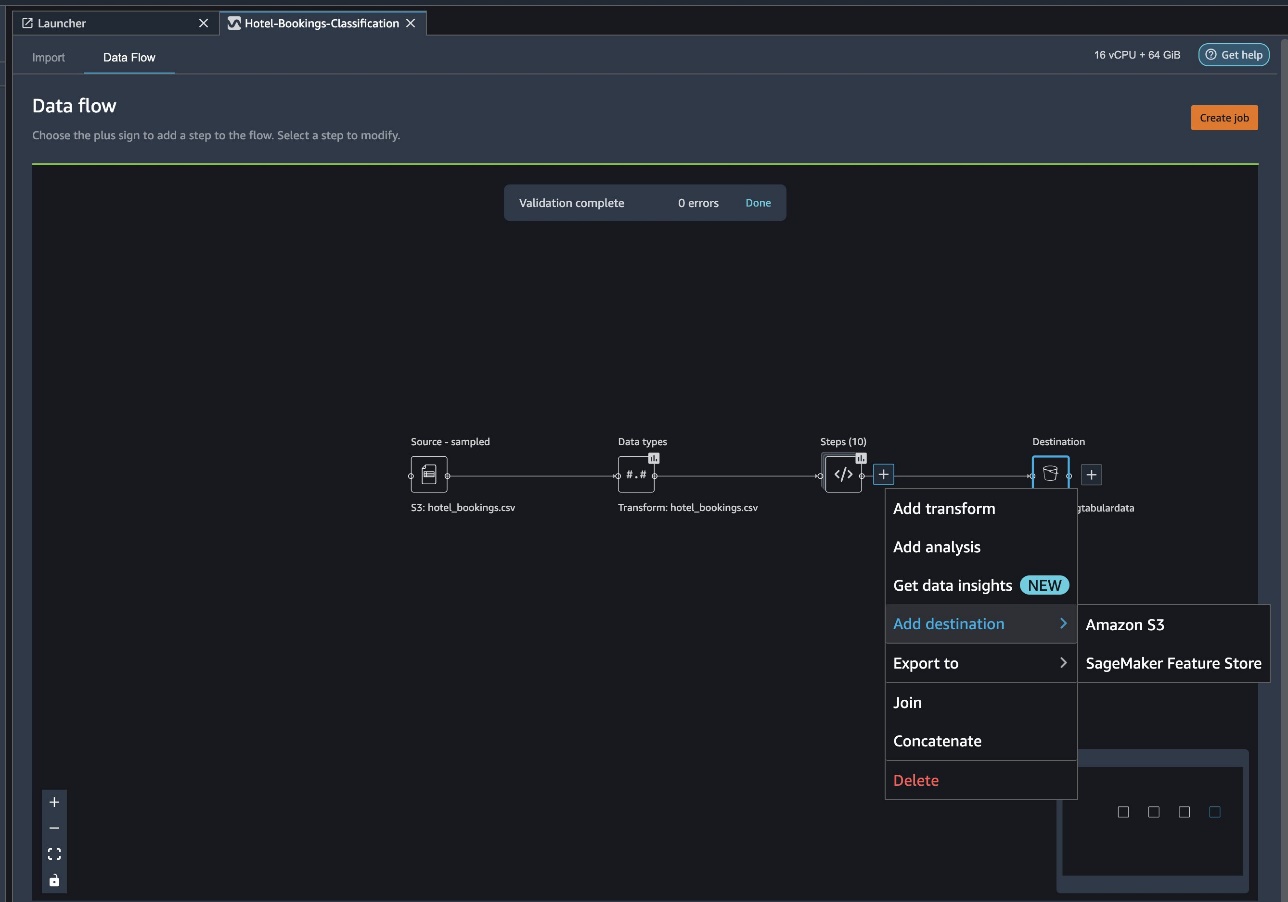
- Hacia nombre de registropor ejemplo, ingrese un nombre para el nuevo registro
NYC_export. - Hacia Tipo de archivoSeleccione CSV.
- Hacia delimitadorSeleccione coma.
- Hacia compresiónSeleccione ninguna.
- Hacia Ubicación de Amazon S3use el mismo nombre de depósito que creamos anteriormente.
- Elegir Agregar objetivo.
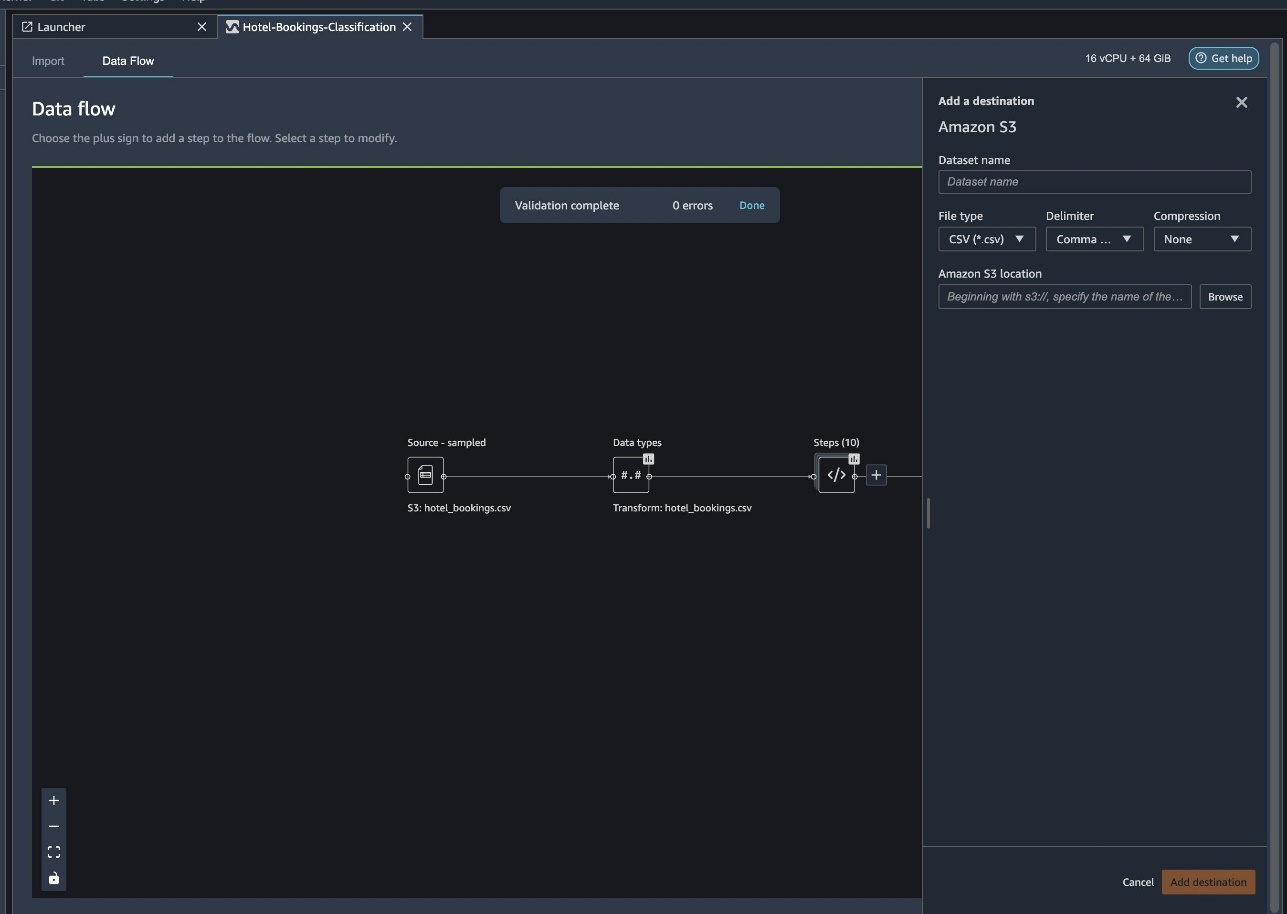
Elegir crear trabajo.
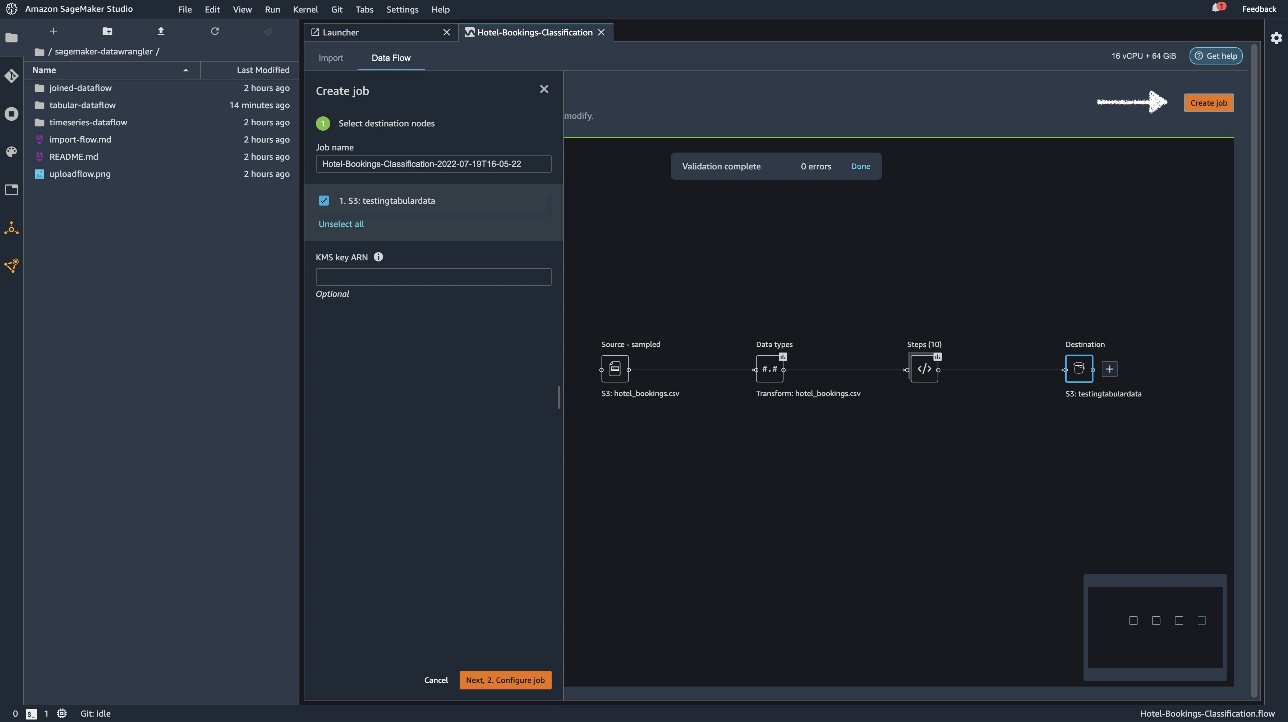
Hacia título profesionalingrese un nombre o mantenga la opción generada automáticamente y seleccione objetivo. Solo tenemos un objetivo S3:testingtabulardata, pero puede tener múltiples objetivos de diferentes pasos en su flujo de trabajo. Déjalos ARN de clave de KMS Campo vacío y elija próximo.
Ahora necesita configurar la capacidad informática para un trabajo. Para este ejemplo, puede conservar todos los valores predeterminados.
- Hacia tipo de instanciause ml.m5.4xlarge.
- Hacia Número de instanciasusar 2.
- puedes explorar Configuración adicionalpero mantenga la configuración predeterminada.
- Elegir Correr.
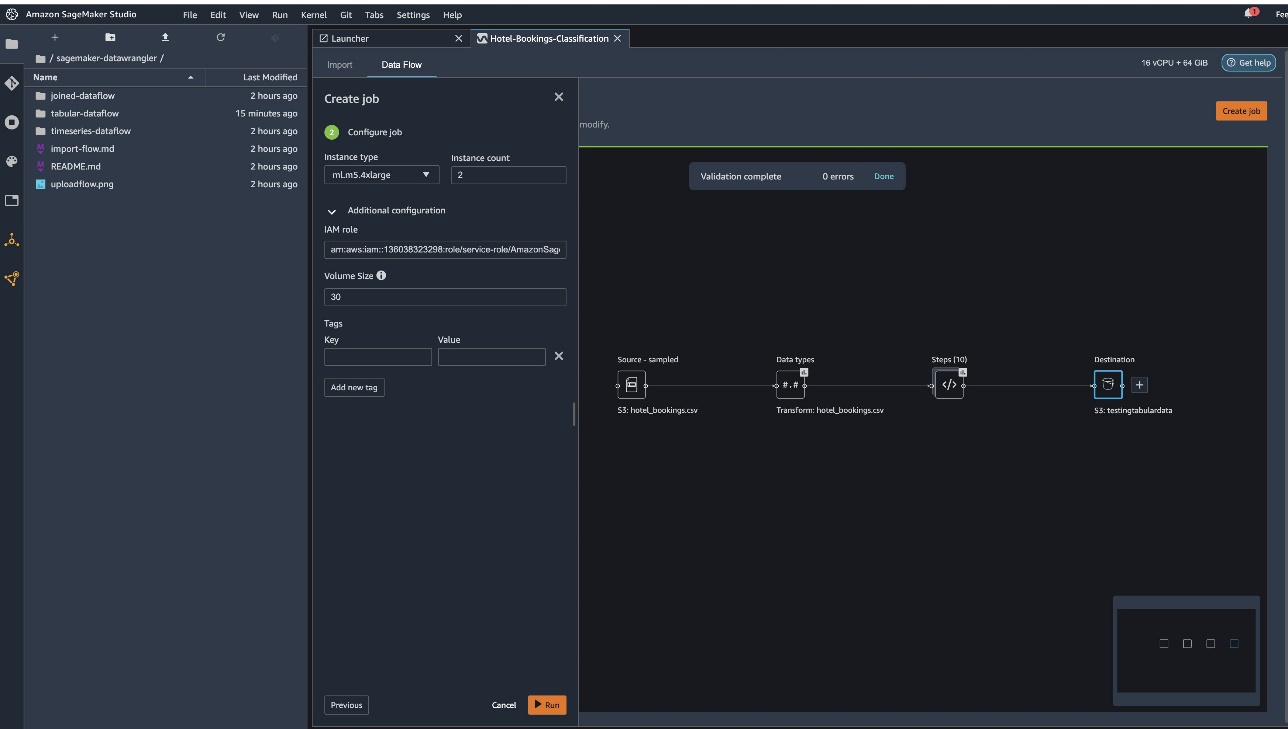
Ahora su trabajo ha comenzado y lleva algún tiempo procesar 6 GB de datos de acuerdo con nuestro flujo de procesamiento de Data Wrangler. El costo de este trabajo es de alrededor de $2 ya que ml.m5.4xlarge cuesta $0.922 por hora y usamos dos de ellos.
Cuando seleccione el nombre del trabajo, accederá a una nueva ventana con los detalles del trabajo.
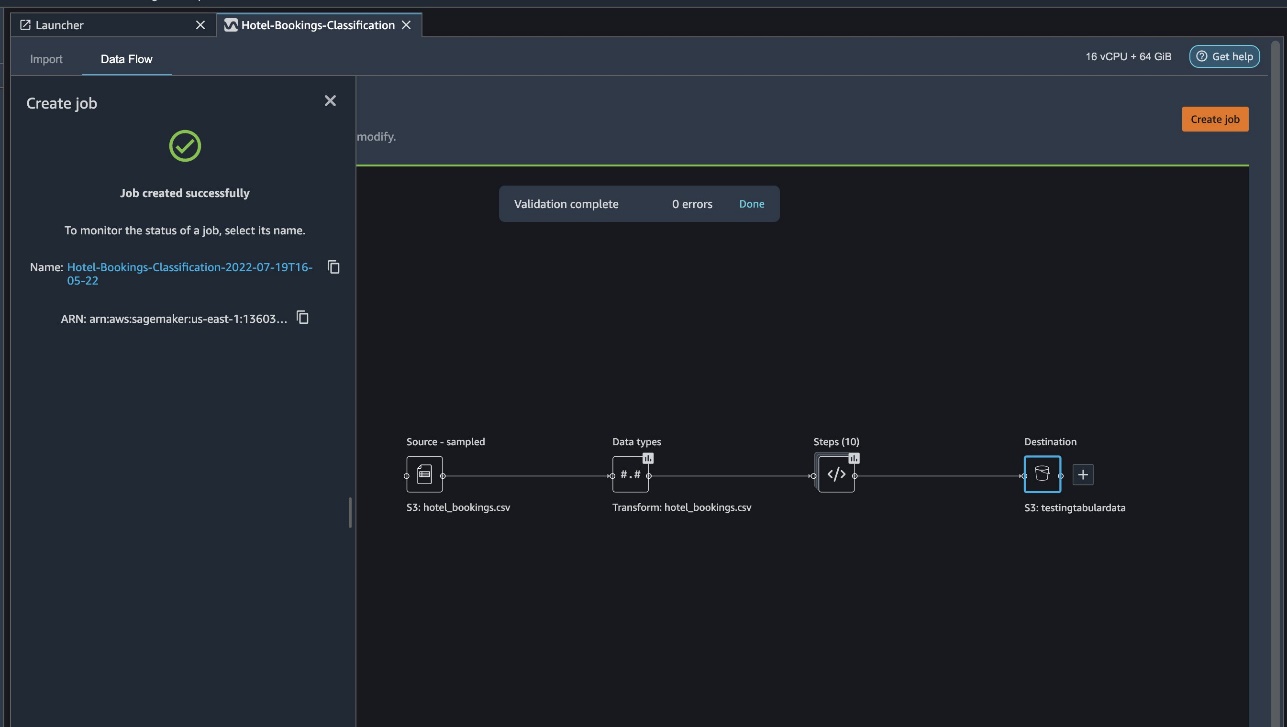
En la página de detalles del pedido, verá todos los parámetros de los pasos anteriores.
Si el estado del pedido cambia a Completado, también puede verificarlo Tiempo de procesamiento (segundos) Valor. Este trabajo de procesamiento tarda entre 5 y 10 minutos.
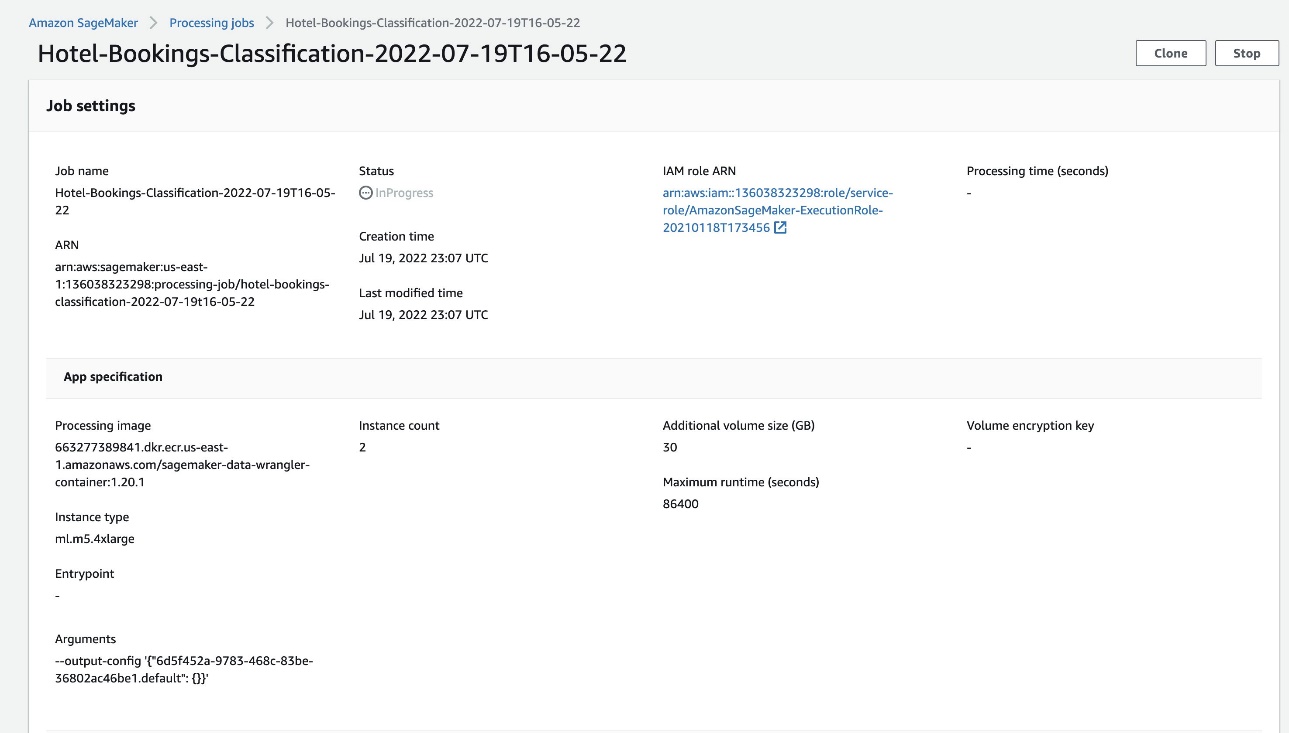
Cuando se completa el trabajo, los archivos de salida de entrenamiento y prueba están disponibles en sus respectivas carpetas de salida de S3. Puede encontrar la ubicación de salida en las configuraciones del trabajo de procesamiento.
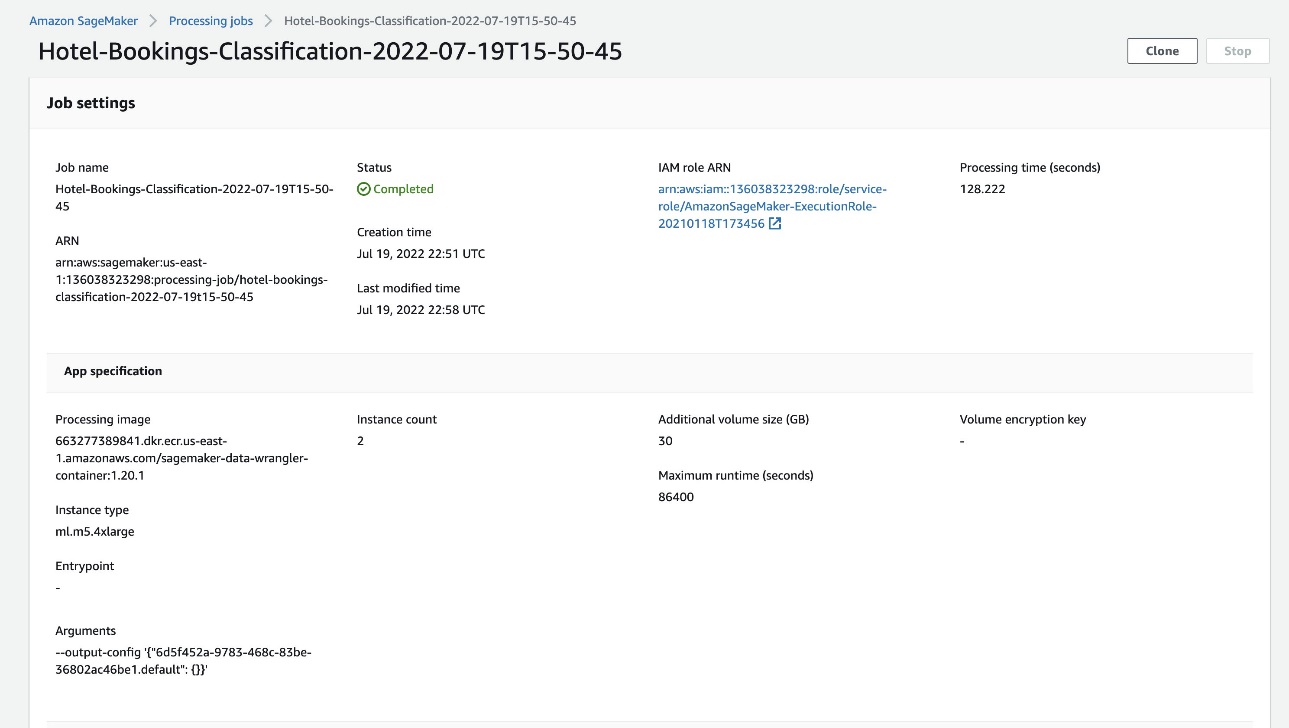
Una vez que se completa el trabajo de procesamiento de Data Wrangler, podemos revisar los resultados almacenados en nuestro depósito S3. No olvides actualizarlos job_name Variable con su nombre de trabajo.
Ahora puede usar estos datos exportados para ejecutar modelos ML.
Limpiar
Elimine sus depósitos de S3 y el flujo de Data Wrangler para borrar los recursos subyacentes y evitar costos no deseados después de finalizar el experimento.
Conclusión
En esta publicación, mostramos cómo importar el flujo de datos preconstruido tabular en Data Wrangler, conectarlo a nuestro conjunto de datos y exportar los resultados a Amazon S3. Si sus casos de uso requieren que manipule datos de series temporales o fusione varios conjuntos de datos, puede explorar los otros flujos de ejemplo prediseñados en el repositorio de GitHub.
Después de importar un flujo de trabajo de preparación de datos preconstruido, puede integrarlo con Amazon SageMaker Processing, Amazon SageMaker Pipelines y Amazon SageMaker Feature Store para simplificar la tarea de procesar, compartir y almacenar datos de capacitación de ML. También puede exportar este flujo de datos de ejemplo a una secuencia de comandos de Python y crear una canalización de preparación de datos de ML personalizada, acelerando su velocidad de publicación.
¡Lo alentamos a que visite nuestro repositorio de GitHub para ejercicios prácticos y encuentre nuevas formas de mejorar la precisión del modelo! Para obtener más información sobre SageMaker, visite la Guía para desarrolladores de Amazon SageMaker.
Sobre los autores
 Isha Dua es un Arquitecto de Soluciones Sénior con sede en el Área de la Bahía de San Francisco. Ella ayuda a los clientes empresariales de AWS a crecer mediante la comprensión de sus objetivos y desafíos, y los guía sobre cómo crear sus aplicaciones de forma nativa en la nube, a la vez que se asegura de que sean resistentes y escalables. Le apasionan las tecnologías de aprendizaje automático y la sostenibilidad ambiental.
Isha Dua es un Arquitecto de Soluciones Sénior con sede en el Área de la Bahía de San Francisco. Ella ayuda a los clientes empresariales de AWS a crecer mediante la comprensión de sus objetivos y desafíos, y los guía sobre cómo crear sus aplicaciones de forma nativa en la nube, a la vez que se asegura de que sean resistentes y escalables. Le apasionan las tecnologías de aprendizaje automático y la sostenibilidad ambiental.
[ad_2]