[ad_1]
La creación de audio realista requiere información de modelado que se presenta en diferentes escalas. Así como la música, por ejemplo, construye frases musicales complejas a partir de notas individuales, el lenguaje combina estructuras temporales locales, como fonemas o sílabas, en palabras y oraciones. La creación de secuencias de audio coherentes y bien estructuradas en todas estas escalas es un desafío que se ha abordado combinando audio con transcripciones que pueden guiar el proceso generativo, ya sean transcripciones de texto para síntesis de voz o representaciones MIDI para piano. Sin embargo, este enfoque falla cuando se trata de modelar aspectos no transcritos del audio, como B. las cualidades del orador necesarias para ayudar a las personas con discapacidades del habla a recuperar su voz o los componentes estilísticos de una interpretación de piano.
En «AudioLM: un enfoque de modelado de lenguaje para la generación de audio» proponemos un nuevo marco de generación de audio que aprende a generar voz realista y música de piano simplemente escuchando audio. El audio generado por AudioLM demuestra consistencia a largo plazo (por ejemplo, sintaxis en el habla, melodía en la música) y alta fidelidad, superando a los sistemas anteriores y empujando las fronteras de la generación de audio con aplicaciones en síntesis de voz o música asistida por computadora. Siguiendo nuestros principios de IA, también desarrollamos un modelo para identificar el audio sintético generado por AudioLM.
Del texto a los modelos de lenguaje de audio
En los últimos años, los modelos de lenguaje entrenados en corpus de texto muy grandes han demostrado sus extraordinarias habilidades generativas, desde el diálogo abierto hasta la traducción automática o incluso el sentido común. También han demostrado su capacidad para modelar señales distintas al texto, como imágenes naturales. La intuición clave detrás de AudioLM es utilizar tales avances en el modelado de lenguaje para generar audio sin estar entrenado en datos anotados.
Sin embargo, al pasar de modelos de lenguaje de texto a modelos de lenguaje de audio, es necesario abordar algunos desafíos. Primero, uno tiene que lidiar con el hecho de que la tasa de datos para el audio es significativamente más alta, lo que resulta en secuencias mucho más largas, mientras que una oración escrita se puede representar con unas pocas decenas de caracteres, su forma de onda de audio generalmente contiene cientos de miles de valores. En segundo lugar, existe una relación de uno a muchos entre el texto y el audio. Esto significa que la misma oración puede ser reproducida por diferentes hablantes con diferentes estilos de habla, contenido emocional y condiciones de grabación.
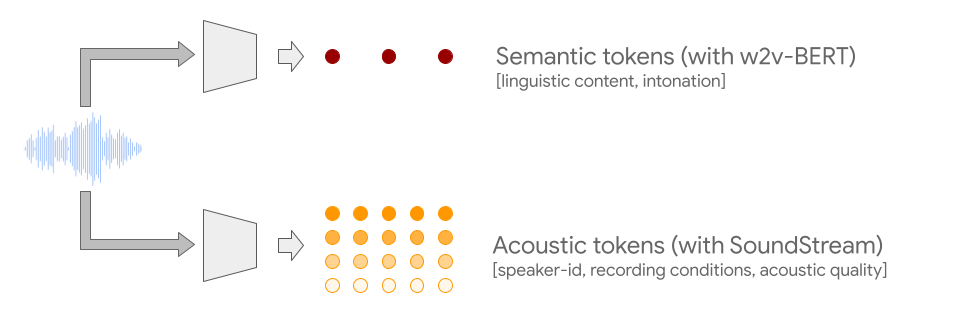
Para superar ambos desafíos, AudioLM utiliza dos tipos de tokens de audio. Primero, signos semánticos se extraen de w2v-BERT, un modelo de audio autosupervisado. Estos tokens capturan tanto dependencias locales (p. ej., fonética en el habla, melodía local en la música de piano) como estructuras globales a largo plazo (p. ej., sintaxis del habla y contenido semántico en el habla, armonía y ritmo en la música de piano) mientras reducen en gran medida la señal de audio para permitir el modelado de secuencias largas.
Sin embargo, el audio reconstruido a partir de estos tokens muestra poca fidelidad. Para superar esta limitación, también confiamos en tokens semánticos señales acústicas generado por un códec Neural SoundStream que captura los detalles de la forma de onda de audio (como las características del altavoz o las condiciones de grabación) y permite una síntesis de alta calidad. Entrenar un sistema para generar tokens semánticos y acústicos simultáneamente da como resultado una alta calidad de audio y una consistencia a largo plazo.
Entrenar un modelo de voz de solo audio
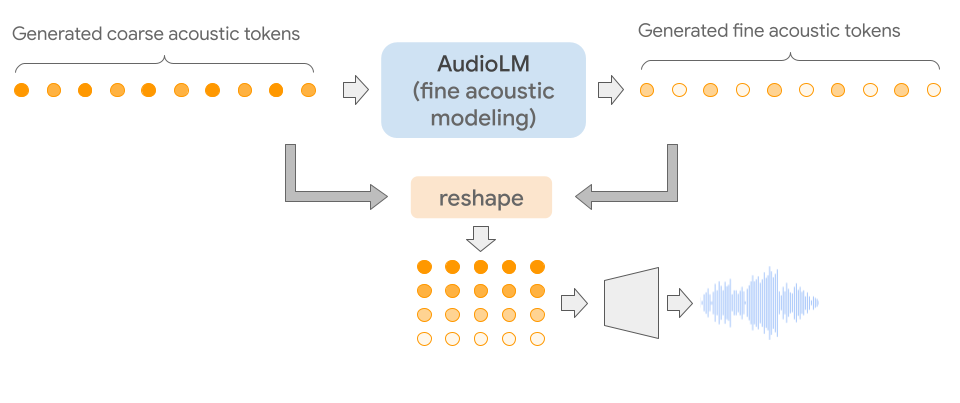
AudioLM es un modelo de solo audio que se entrena sin texto ni representación simbólica de la música. AudioLM modela jerárquicamente una secuencia de audio, desde tokens semánticos hasta tokens acústicos finos, encadenando múltiples modelos de Transformer, uno para cada etapa. Cada etapa se entrena para la próxima predicción de tokens basada en tokens anteriores, tal como se entrenaría un modelo de lenguaje textual. La primera etapa realiza esta tarea en tokens semánticos para modelar la estructura de alto nivel de la secuencia de audio.

En la segunda etapa, concatenamos toda la secuencia de tokens semánticos junto con los tokens acústicos generales pasados y alimentamos ambos como condicionamiento en el modelo acústico general, que luego predice los tokens futuros. Este paso modela propiedades acústicas tales como B. características del hablante en el habla o timbre en la música.

En la tercera etapa, procesamos los tokens acústicos gruesos con el modelo acústico fino, lo que agrega aún más detalles al audio final. Finalmente, alimentamos el decodificador SoundStream con tokens acústicos para reconstruir una forma de onda.
Después del entrenamiento, AudioLM se puede condicionar a unos pocos segundos de audio, lo que le permite producir una continuación consistente. Para demostrar la aplicabilidad general del marco AudioLM, consideremos dos tareas de diferentes dominios de audio:
- continuación del discursodonde se espera que el modelo conserve las características del hablante, la prosodia y las condiciones de grabación del anuncio mientras genera contenido nuevo que sea sintácticamente correcto y semánticamente consistente.
- piano de continuacióndonde se espera que el modelo produzca música de piano que sea coherente con el mensaje en términos de melodía, armonía y ritmo.
En el video a continuación, puede escuchar ejemplos en los que se le pide al modelo que continúe con el habla o la música y genere contenido nuevo que no se vio durante la capacitación. Mientras escucha, observe que todo lo que escuche después de la línea vertical gris fue generado por AudioLM, y que el modelo nunca vio el texto o la transcripción musical, solo aprendió del audio sin procesar. Publicaremos más muestras en este sitio web.
Para validar nuestros resultados, pedimos a evaluadores humanos que escucharan clips de audio cortos y decidieran si se trataba de una grabación original del habla humana o una continuación sintética generada por AudioLM. Según las revisiones recopiladas, observamos una tasa de éxito del 51,2 %, que no es significativamente diferente desde el punto de vista estadístico de la tasa de éxito del 50 % que se logra cuando las etiquetas se asignan al azar. Esto significa que el habla producida por AudioLM es casi indistinguible del habla real para el oyente promedio.
Nuestro trabajo en AudioLM tiene fines de investigación y actualmente no tenemos planes de lanzarlo más ampliamente. De acuerdo con nuestros principios de IA, buscamos comprender y mitigar la posibilidad de que los humanos pudieran malinterpretar las muestras breves de voz sintetizadas por AudioLM como voz real. Para ello, entrenamos un clasificador que puede reconocer voz sintetizada generada por AudioLM con una precisión muy alta (98,6 %). Esto muestra que las continuaciones generadas por AudioLM, aunque (casi) indistinguibles para algunos oyentes, son muy fáciles de detectar con un clasificador de audio simple. Este es un primer paso crítico en la protección contra el abuso potencial de AudioLM, con esfuerzos futuros que posiblemente exploren tecnologías como la «marca de agua» de audio.
Conclusión
Presentamos AudioLM, un enfoque de modelado de lenguaje para la generación de audio que ofrece coherencia a largo plazo y alta calidad de audio. Los experimentos de generación de voz muestran no solo que AudioLM puede generar voz sintáctica y semánticamente coherente sin texto, sino también que las continuaciones generadas por el modelo son casi indistinguibles del habla humana real. Además, AudioLM va mucho más allá del habla y puede modelar cualquier señal de audio, como música de piano. Esto fomenta la extensión futura a otros tipos de audio (por ejemplo, voz multilingüe, música polifónica y eventos de audio), así como la integración de AudioLM en un marco de codificador-decodificador para tareas condicionadas como la traducción de texto a voz o de voz a voz.
Gracias
La obra descrita aquí fue escrita por Zalán Borsos, Raphaël Marinier, Damien Vincent, Eugene Kharitonov, Olivier Pietquin, Matt Sharifi, Olivier Teboul, David Grangier, Marco Tagliasacchi y Neil Zeghidour. Agradecemos cualquier discusión y comentarios sobre este trabajo que hayamos recibido de nuestros colegas en Google.
[ad_2]