[ad_1]
En las conversaciones naturales, no decimos los nombres de las personas cada vez que hablamos. En su lugar, confiamos en los mecanismos de señalización contextual para iniciar conversaciones, y el contacto visual suele ser suficiente. El Asistente de Google, ahora disponible en más de 95 países y en más de 29 idiomas, se ha basado principalmente en un mecanismo de palabras activas («Hola Google» u «Ok Google») para involucrar a más de 700 millones de personas cada mes para ayudar a hacer las cosas en los dispositivos del Asistente. A medida que los asistentes virtuales se vuelven una parte permanente de nuestra vida cotidiana, estamos desarrollando formas de iniciar conversaciones de una manera más natural.
En Google I/O 2022, anunciamos Look and Talk, una gran evolución en nuestro viaje para crear formas naturales e intuitivas de interactuar con los dispositivos domésticos con tecnología del Asistente de Google. Esta es la primera función de asistente multimodal en el dispositivo que analiza simultáneamente audio, video y texto para determinar cuándo está hablando con su Nest Hub Max. Al usar ocho modelos de aprendizaje automático juntos, el algoritmo puede distinguir las interacciones intencionales de las miradas fugaces para identificar con precisión la intención de un usuario de interactuar con el asistente. Una vez que el usuario está a menos de 5 pies del dispositivo, simplemente puede mirar la pantalla y hablar para comenzar a interactuar con el asistente.
Desarrollamos Look and Talk de acuerdo con nuestros principios de IA. Cumple con nuestros estrictos requisitos de procesamiento de audio y video y, al igual que nuestras otras funciones de detección de cámara, el video nunca sale del dispositivo. Puedes pausar, revisar y eliminar tu actividad del Asistente en cualquier momento en myactivity.google.com. Estas capas adicionales de protección permiten que Look and Talk solo funcione para aquellos que lo habilitan, mientras mantienen sus datos seguros.
 |
| El Asistente de Google se basa en una serie de señales para determinar exactamente cuándo le habla el usuario. A la derecha hay una lista de las señales utilizadas con indicadores que muestran cuándo se activa cada señal según la proximidad del usuario al dispositivo y la dirección en la que mira. |
desafíos de modelado
El viaje de esta característica comenzó como un prototipo técnico construido sobre modelos desarrollados para la investigación académica. Sin embargo, la implementación a escala requería resolver desafíos del mundo real exclusivos de esta función. Debería:
- Admite una variedad de datos demográficos (por ejemplo, edad, color de piel).
- Adáptese a la diversidad ambiental del mundo real, incluida la iluminación exigente (p. ej., retroiluminación, patrones de sombras) y las condiciones acústicas (p. ej., reverberación, ruido de fondo).
- Trate con perspectivas de cámara inusuales, ya que las pantallas inteligentes a menudo se usan como dispositivos de mostrador, frente a los usuarios en lugar de las caras frontales que se usan típicamente en conjuntos de datos de investigación para entrenar modelos.
- Ejecución en tiempo real para garantizar respuestas oportunas mientras se procesan videos en el dispositivo.
El desarrollo del algoritmo involucró la experimentación con enfoques que van desde la personalización y personalización del dominio hasta el desarrollo de conjuntos de datos específicos del dominio, pruebas de campo y comentarios, y ajuste iterativo del algoritmo general.
Descripción general de la tecnología
Una interacción de mirar y hablar consta de tres fases. En la primera fase, el asistente utiliza señales visuales para reconocer cuando un usuario muestra la intención de participar y luego «se despierta» para escuchar su expresión. La segunda fase está diseñada para validar y comprender aún más la intención del usuario mediante señales visuales y de audio. Si una señal en la primera o segunda fase de procesamiento indica que no se trata de una solicitud del Asistente, el Asistente vuelve al modo de espera. Estas dos fases son las funciones principales de Look and Talk y se explican a continuación. La tercera fase del cumplimiento de la consulta es un flujo de consulta típico y está más allá del alcance de este blog.
Fase uno: interacción con el asistente
La primera fase de Look and Talk tiene como objetivo evaluar si un usuario registrado está interactuando intencionalmente con el Asistente. Look and Talk utiliza el reconocimiento facial para identificar la presencia del usuario, filtra la proximidad en función del tamaño del campo de visión detectado para inferir la distancia y, a continuación, utiliza el sistema Face Match existente para determinar si se trata de intercambios registrados de usuarios de Look and Talk.
Para un usuario inscrito dentro del alcance, un modelo de mirada personalizado determina si está mirando el dispositivo. Este modelo estima tanto el punto de vista como la confianza binaria de mirar a la cámara a partir de imágenes fijas utilizando una arquitectura de red neuronal convolucional de varias torres, con una torre procesando todo el rostro y otra procesando las manchas alrededor de los ojos. Debido a que la pantalla del dispositivo cubre un área debajo de la cámara que un usuario miraría naturalmente, asignamos el punto de vista y la predicción binaria de la mirada de la cámara al área de la pantalla del dispositivo. Para garantizar que la predicción final sea inmune a las predicciones individuales falsas y a los movimientos sacádicos y guiños involuntarios, aplicamos una función de suavizado a cada predicción basada en fotogramas para eliminar las predicciones individuales falsas.
 |
| Resumen de predicción de miradas y posprocesamiento. |
Aplicamos requisitos de atención más estrictos antes de notificar a los usuarios que el sistema está listo para interactuar, para minimizar los falsos activadores, p. B. cuando un usuario que pasa mira el dispositivo. Una vez que el usuario que mira el dispositivo comienza a hablar, relajamos el requisito de atención y permitimos que el usuario cambie su mirada de forma natural.
La señal final requerida en esta fase de procesamiento es verificar que el usuario de Face Matched sea el hablante activo. Esto lo proporciona un modelo de reconocimiento de hablante activo multimodal que toma como entrada tanto el video de la cara del usuario como el audio que contiene el habla y predice si habla. Varias técnicas de aumento (incluidos RandAugment, SpecAugment y aumento con sonidos AudioSet) ayudan a mejorar la calidad de la predicción en el hogar y aumentan el rendimiento de la función final en más del 10 %. El modelo final implementado es un modelo TFLite cuantificado y acelerado por hardware que utiliza cinco marcos de contexto para la entrada visual y 0,5 segundos para la entrada de audio.
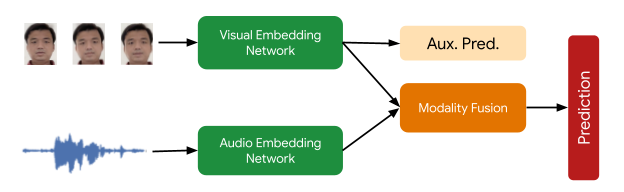 |
| Descripción general del modelo de reconocimiento de hablante activo: el modelo audiovisual de dos torres proporciona la predicción de la probabilidad de «hablar» para la cara. La predicción auxiliar de la red visual empuja a la red visual a ser lo mejor posible, mejorando la predicción multimodal final. |
Fase dos: el asistente comienza a escuchar
En la fase dos, el sistema comienza a escuchar el contenido de la solicitud del usuario, todavía completamente en el dispositivo, para evaluar más a fondo si la interacción está destinada al asistente, en función de señales adicionales. En primer lugar, Look and Talk utiliza Voice Match para garantizar aún más que el hablante esté registrado y sea coherente con la señal anterior de Face Match. Luego ejecuta un modelo de reconocimiento de voz automático de última generación en el dispositivo para transcribir el enunciado.
El siguiente paso crítico del procesamiento es el algoritmo de comprensión de la intención, que predice si la declaración del usuario estaba pensada como una consulta del Asistente. Consta de dos partes: 1) un modelo que analiza la información no léxica del audio (p. ej., tono, velocidad, ruido de retardo) para determinar si el enunciado suena como una consulta del asistente y 2) un modelo de análisis de texto, que determina si la transcripción es una solicitud de Asistente. Juntos, filtran las consultas que no están destinadas al Asistente. También utiliza señales visuales contextuales para determinar la probabilidad de que la interacción esté destinada al Asistente.
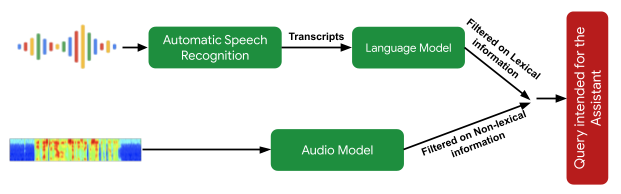 |
| Descripción general del enfoque de filtrado semántico para determinar si una expresión de usuario es una consulta destinada al asistente. |
Finalmente, cuando el modelo de comprensión de la intención determina que la expresión del usuario probablemente estaba destinada al Asistente, Look and Talk pasa a la fase de ejecución, donde se comunica con el servidor del Asistente para obtener una respuesta basada en la intención del usuario y el texto de la consulta.
Rendimiento, personalización y UX
Cada modelo compatible con Look and Talk se evaluó y mejoró de forma aislada, luego se probó en el sistema Look and Talk de extremo a extremo. La amplia variedad de condiciones ambientales en las que opera Look and Talk requiere la introducción de parámetros de personalización para la solidez del algoritmo. Usando señales obtenidas durante las interacciones basadas en palabras clave del usuario, el sistema personaliza los parámetros para usuarios individuales para proporcionar mejoras sobre el modelo global generalizado. Esta personalización también se ejecuta completamente en el dispositivo.
Sin una palabra clave predefinida para la intención del usuario proxy, la latencia era un problema importante para Look and Talk. A menudo, una señal de interacción lo suficientemente fuerte no se produce hasta que el usuario ha comenzado a hablar, lo que puede agregar cientos de milisegundos de latencia, y los modelos de comprensión de intenciones existentes contribuyen a esto al requerir consultas completas, no parciales. Para cerrar esta brecha, Look and Talk prescinde por completo de la transmisión de audio al servidor, con la transcripción y la comprensión de la intención en el dispositivo. Los modelos de comprensión de la intención pueden procesar enunciados parciales. Esto da como resultado una latencia de extremo a extremo comparable a los sistemas actuales basados en palabras activas.
La experiencia de la interfaz de usuario se basa en la investigación del usuario para proporcionar comentarios visuales equilibrados con una gran capacidad de aprendizaje. Esto se muestra en la imagen de abajo.
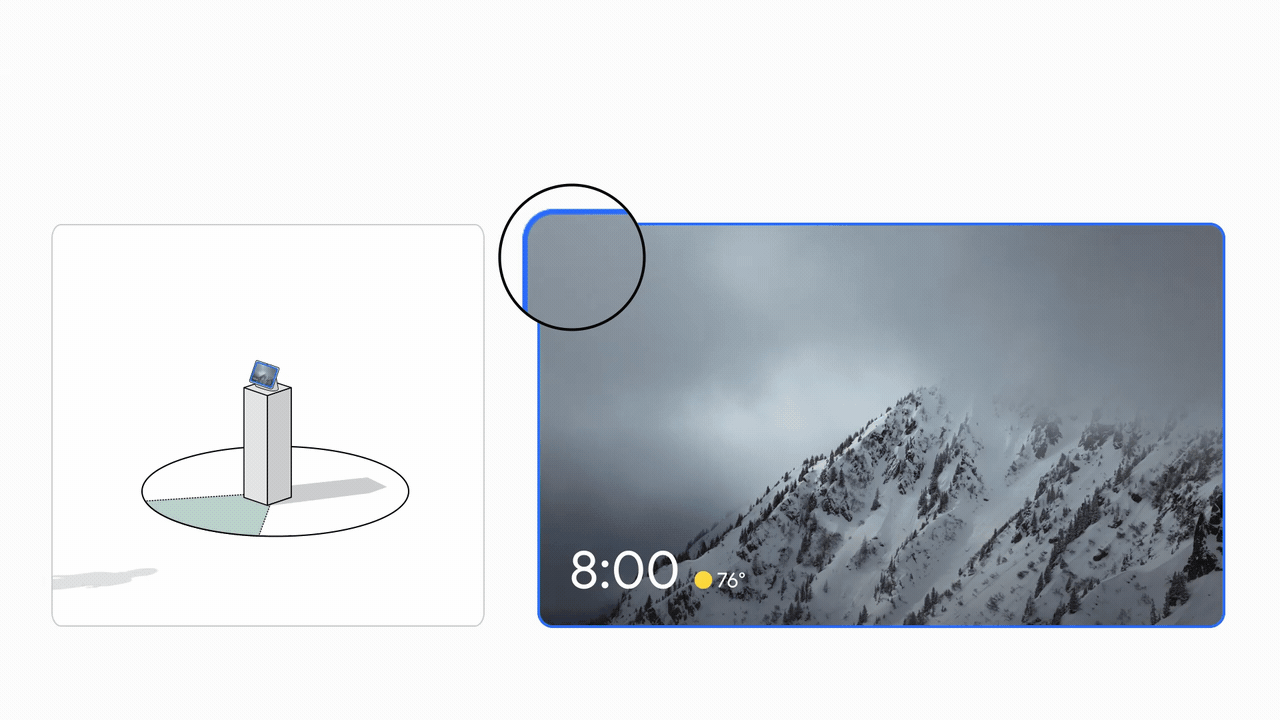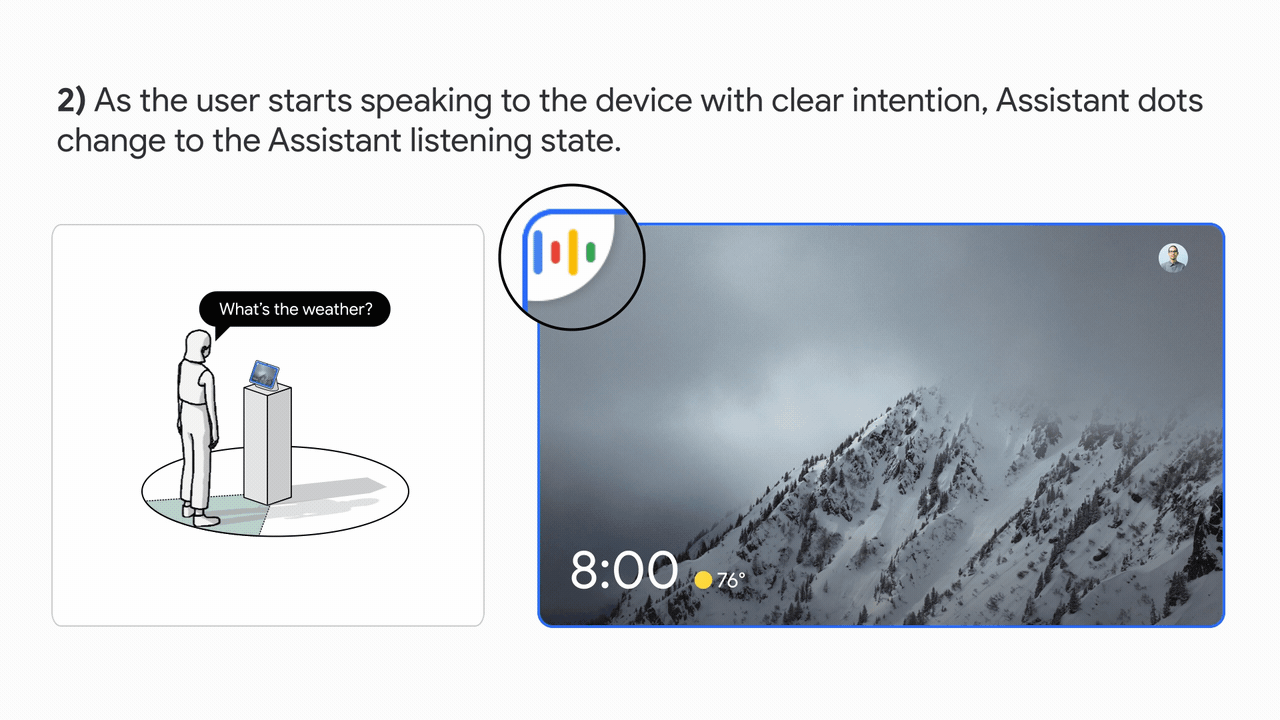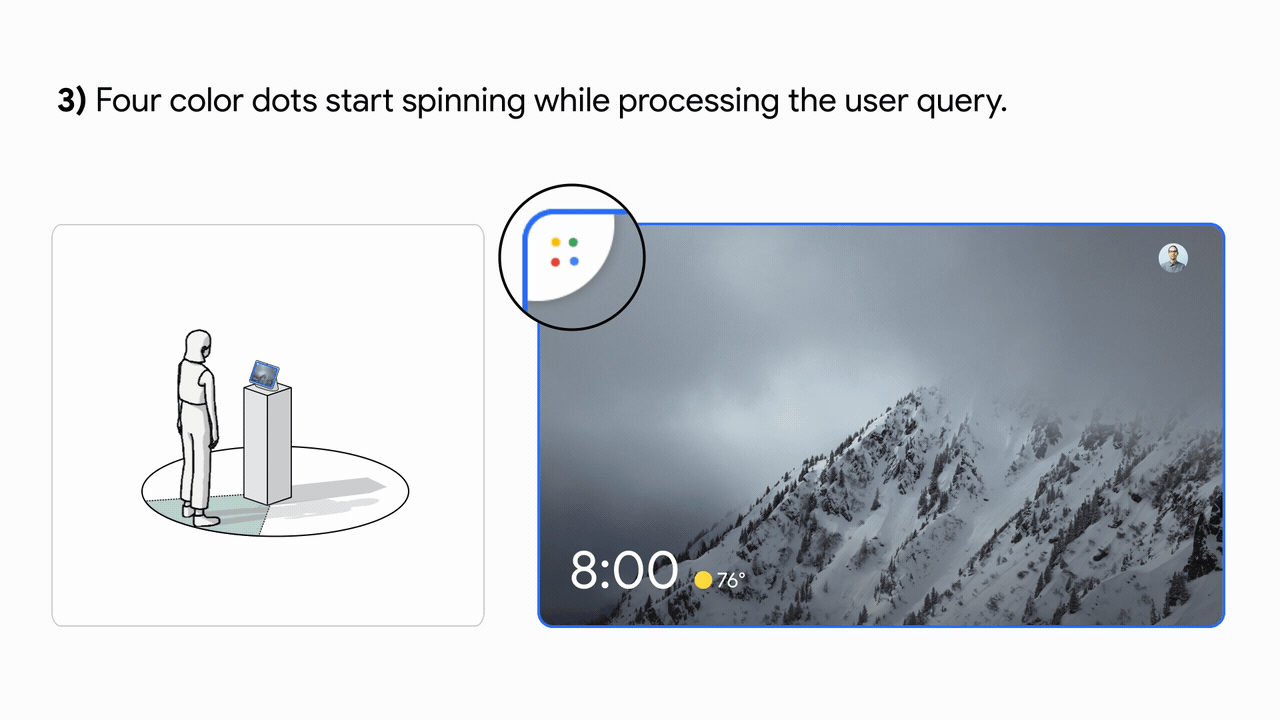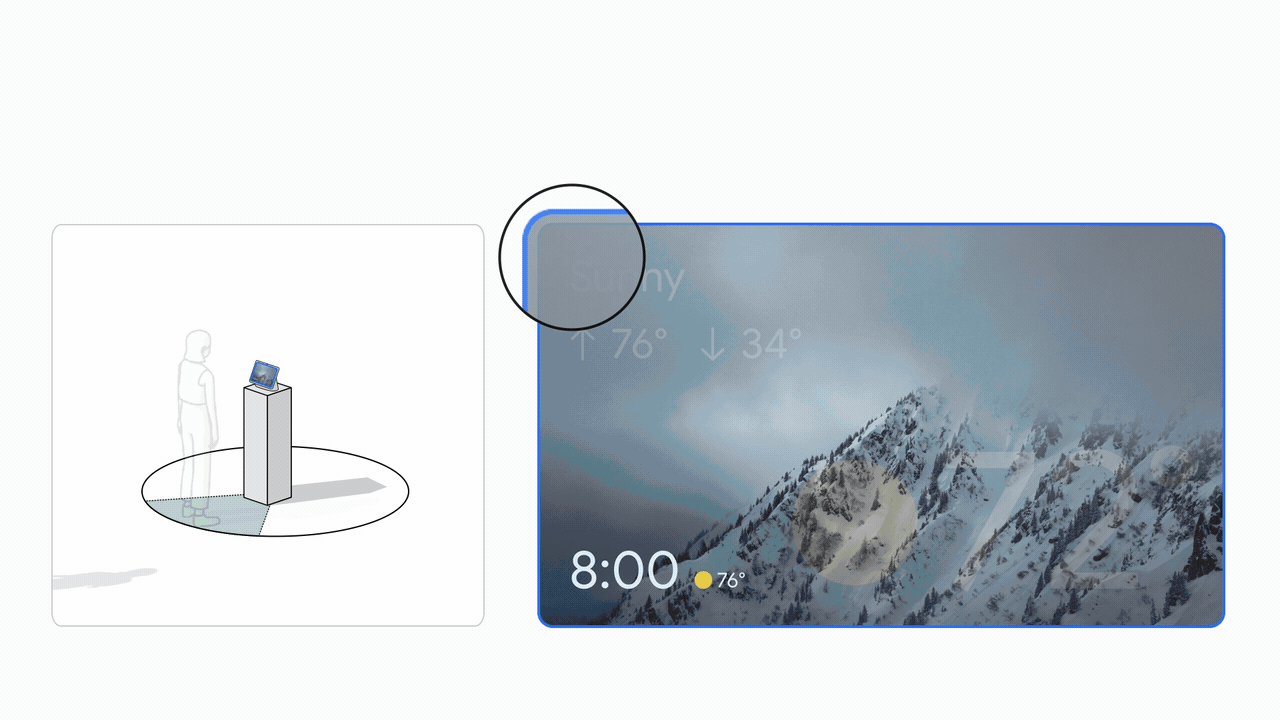 |
| Izquierda: el diagrama de interacción espacial de un usuario que interactúa con Look and Talk. Derecha: La experiencia de la interfaz de usuario (UI). |
Desarrollamos un conjunto de datos de video diverso con más de 3000 participantes para probar la función en subgrupos demográficos. Las mejoras de modelado, impulsadas por la diversidad de nuestros datos de entrenamiento, mejoraron el rendimiento de todos los subgrupos.
Conclusión
Look and Talk es un paso importante para que la interacción del usuario con el Asistente de Google sea lo más natural posible. Si bien este es un hito importante en nuestro viaje, esperamos que sea la primera de muchas mejoras en nuestros paradigmas de interacción que continuarán reinventando de manera responsable la experiencia del Asistente de Google. Nuestro objetivo es hacer que obtener ayuda se sienta natural y fácil, en última instancia, ahorrando tiempo para que los usuarios puedan concentrarse en lo que más importa.
Gracias
Este trabajo involucró la colaboración de un equipo multidisciplinario de desarrolladores de software, investigadores, UX y colaboradores multifuncionales. Los principales colaboradores del Asistente de Google incluyen a Alexey Galata, Alice Chuang, Barbara Wang, Britanie Hall, Gabriel Leblanc, Gloria McGee, Hideaki Matsui, James Zanoni, Joanna (Qiong) Huang, Krunal Shah, Kavitha Kandappan, Pedro Silva, Tanya Sinha, Tuan Nguyen, Vishal Desai, Will Truong, Yixing Cai, Yunfan Ye; de investigaciones que incluyen a Hao Wu, Joseph Roth, Sagar Savla, Sourish Chaudhuri, Susanna Ricco. Muchas gracias a Yuan Yuan y Caroline Pantofaru por su orientación, y a todos los miembros de los equipos de Nest, Assistant e Research que hicieron contribuciones invaluables al desarrollo de Look and Talk.
[ad_2]